脑裂真的是一个很头疼的问题(ps: 脑袋都裂开了,能不疼吗?),看下面的图:
一、哨兵(sentinel)模式下的脑裂
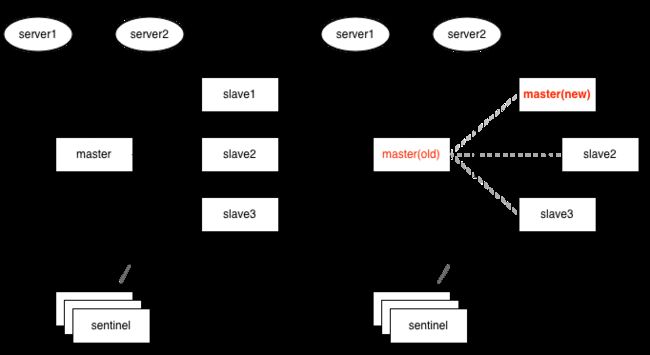
如上图,1个master与3个slave组成的哨兵模式(哨兵独立部署于其它机器),刚开始时,2个应用服务器server1、server2都连接在master上,如果master与slave及哨兵之间的网络发生故障,但是哨兵与slave之间通讯正常,这时3个slave其中1个经过哨兵投票后,提升为新master,如果恰好此时server1仍然连接的是旧的master,而server2连接到了新的master上。
数据就不一致了,基于setNX指令的分布式锁,可能会拿到相同的锁;基于incr生成的全局唯一id,也可能出现重复。
二、集群(cluster)模式下的脑裂
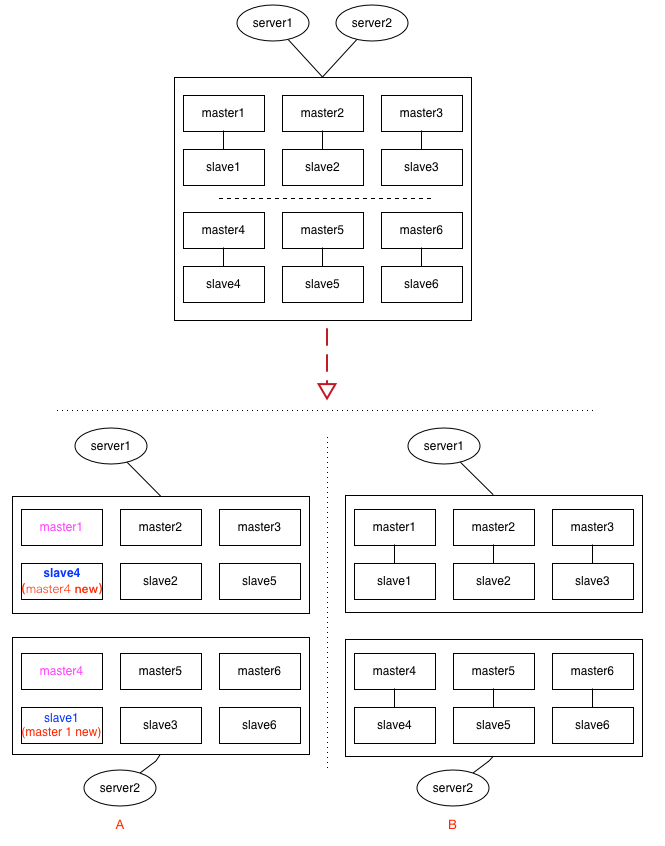
custer模式下,这种情况要更复杂,见上面的示意图,集群中有6组分片,每给分片节点都有1主1从,如果出现网络分区时,各种节点之间的分区组合都有可能,上面列了2种情况:
情况A:
假设master1与slave4落到同1个分区,这时slave4经过选举后,可能会被提升为新的master4,而另一个分区里的slave1,可能会提升为新的master1。看过本博客前面介绍redis cluster的同学应该知道,cluster中key的定位是依赖slot(槽位),情况A经过这一翻折腾后,master1与master4上的slot,出现了重复,在二个分区里都有。类似的,如果依赖incr及setNX的应用场景,都会出现数据不一致的情况。
情况B:
如果每给分片内部的逻辑(即:主从关系)没有乱,只是恰好分成二半,这时slot整体上看并没有出现重复,如果原来请求的key落在其它区,最多只是访问不到,还不致于发生数据不一致的情况。(即:宁可出错,也不要出现数据混乱)
三、主从迁移带来的不一致
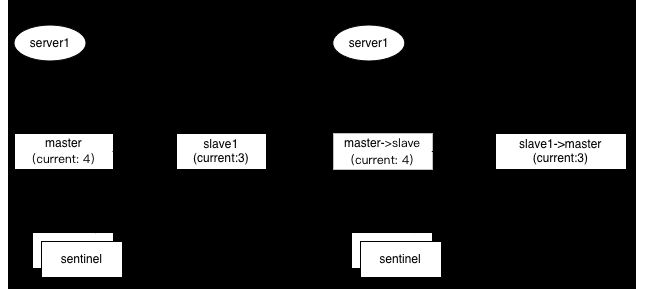
如上图,1主1从,如果采用incr来生成全局唯一键,假如master上的值是4,但是尚未同步到slave上(slave上仍然是旧值3),这时候如果发生选举,slave被提升为新master,应用服务器server1切换到新主后,下次再incr获取的值,就可能重复了(3+1=4)
总结:虽然上面的情况都比较极端,但实际中还是有可能发生的,正如官方文档所言,redis并不能保证强一致性(Redis Cluster is not able to guarantee strong consistency. / In general Redis + Sentinel as a whole are a an eventually consistent system) 对于要求强一致性的应用,更应该倾向于相信RDBMS(传统关系型数据库)。
参考:
http://www.redis.io/topics/sentinel
https://redis.io/topics/cluster-tutorial