图像分类VGG网络
VGG
VGG网络是2014年ILSVRC图像分类比赛的第二名,将 Top-5错误率降到7.3%。。VGG网络结构简洁,可以当做图像分类算法的baseline进行修改开发。
网络结构图如下:
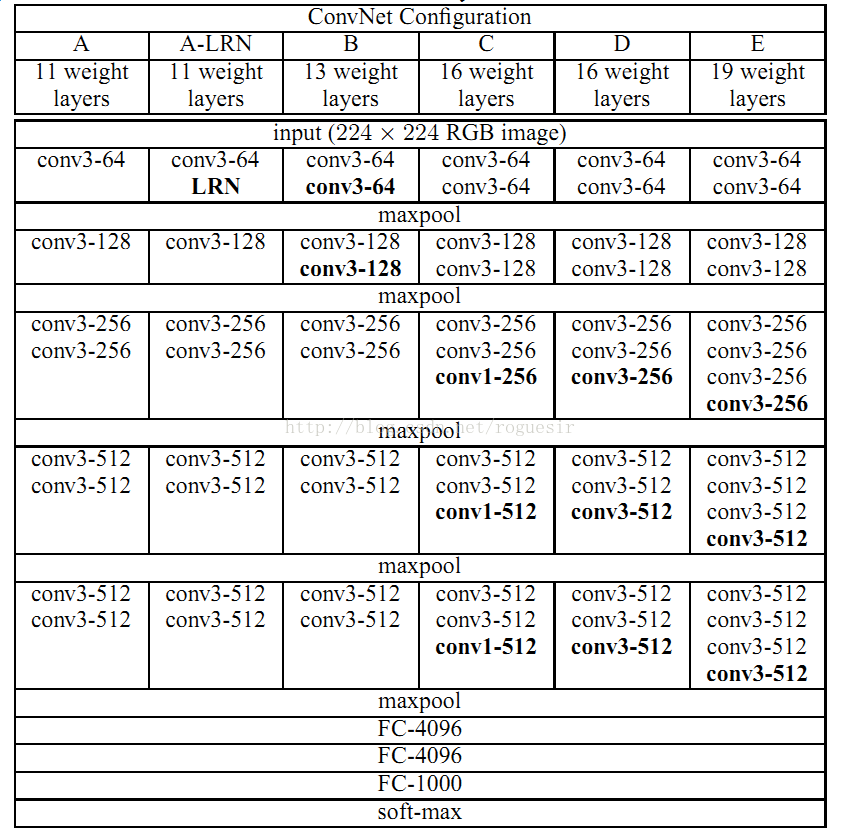
利用多个小卷积核可以代替高维卷积核进行卷及操作,达到减少计算量的效果。网络结构中,卷积层步长都为1,池化层步长都为2。从VGG-A到VGG-E的参数量没有发生太大的改变,主要是由于参数都集中在全连接层。LRN被证明没有什么效果而且白白浪费计算量,所以在VGG-B往后的网络结构中都被去掉了。
下面给出VGG-D的tensorflow实现方法:
定义好卷积和池化层的方法。
# 卷积
def conv2d(x, W, strides=1, padding='SAME', name=None):
return tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding=padding, name=name)
# 平均池化
def max_pool(x, size=2, strides=2, padding='SAME', name=None):
return tf.nn.max_pool(x, ksize=[1, size, size, 1], strides=[1, strides, strides, 1], padding=padding, name=name)定义VGG网络,接受一个输入,批量图像。返回一个输出,有几个类别,输出就是几维。例子中是10个类别
def Vgg_net(input,keep_prob):
with tf.variable_scope("vggnet")as scope:
x_image = tf.reshape(input, [-1, 224, 224, 1])
kernel1 = tf.Variable(tf.random_uniform([3, 3, 1, 64], -0.1, 0.1))
conv1 = conv2d(x_image, kernel1)
relu1 = tf.nn.relu(conv1)
kernel2 = tf.Variable(tf.random_uniform([3, 3, 64, 64], -0.1, 0.1))
con2 = conv2d(relu1, kernel2)
relu2 = tf.nn.relu(con2)
maxpool1 = max_pool(relu2)
kernel3 = tf.Variable(tf.random_uniform([3, 3, 64, 128], -0.1, 0.1))
conv3 = conv2d(maxpool1, kernel3)
relu3 = tf.nn.relu(conv3)
kernel4 = tf.Variable(tf.random_uniform([3, 3, 128, 128], -0.1, 0.1))
conv4 = conv2d(relu3, kernel4)
relu4 = tf.nn.relu(conv4)
maxpool2 = max_pool(relu4)
kernel5 = tf.Variable(tf.random_uniform([3, 3, 128, 256], -0.1, 0.1))
conv5 = conv2d(maxpool2, kernel5)
relu5 = tf.nn.relu(conv5)
kernel6 = tf.Variable(tf.random_uniform([3, 3, 256, 256], -0.1, 0.1))
conv6 = conv2d(relu5, kernel6)
relu6 = tf.nn.relu(conv6)
kernel7 = tf.Variable(tf.random_uniform([3, 3, 256, 256], -0.1, 0.1))
conv7 = conv2d(relu6, kernel7)
relu7 = tf.nn.relu(conv7)
maxpool3 = max_pool(relu7)
kernel8 = tf.Variable(tf.random_uniform([3, 3, 256, 512], -0.1, 0.1))
conv8 = conv2d(maxpool3, kernel8)
relu8 = tf.nn.relu(conv8)
kernel9 = tf.Variable(tf.random_uniform([3, 3, 512, 512], -0.1, 0.1))
conv9 = conv2d(relu8, kernel9)
relu9 = tf.nn.relu(conv9)
kernel10 = tf.Variable(tf.random_uniform([3, 3, 512, 512], -0.1, 0.1))
conv10 = conv2d(relu9, kernel10)
relu10 = tf.nn.relu(conv10)
maxpool4 = max_pool(relu10)
kernel11 = tf.Variable(tf.random_uniform([3, 3, 512, 512], -0.1, 0.1))
conv11 = conv2d(maxpool4, kernel11)
relu11 = tf.nn.relu(conv11)
kernel12 = tf.Variable(tf.random_uniform([3, 3, 512, 512], -0.1, 0.1))
conv12 = conv2d(relu11, kernel12)
relu12 = tf.nn.relu(conv12)
kernel13 = tf.Variable(tf.random_uniform([3, 3, 512, 512], -0.1, 0.1))
conv13 = conv2d(relu12, kernel13)
relu13 = tf.nn.relu(conv13)
maxpool5 = max_pool(relu13)
#7*7*512=25088
maxreshape=tf.reshape(maxpool5,[-1,25088])
W1 = tf.Variable(tf.random_uniform([25088,4096], -0.1, 0.1))
bias1 = tf.Variable(tf.random_normal([4096], mean=0.0, stddev=0.01))
FC1 = tf.matmul(maxreshape, W1) + bias1
relu14 = tf.nn.relu(FC1)
out_1 = tf.nn.dropout(relu14, keep_prob=keep_prob)
W2 = tf.Variable(tf.random_uniform([4096, 4096], -0.1, 0.1))
bias2 = tf.Variable(tf.random_normal([4096], mean=0.0, stddev=0.01))
FC2 = tf.matmul(out_1, W2) + bias2
relu15 = tf.nn.relu(FC2)
out_2 = tf.nn.dropout(relu15, keep_prob=keep_prob)
W3 = tf.Variable(tf.random_uniform([4096, 10], -0.1, 0.1))
bias3 = tf.Variable(tf.random_normal([10], mean=0.0, stddev=0.01))
y_= tf.matmul(out_2, W3) + bias3
return y_
# 图像路径和标签
def get_filename(file_dir):
original_pic = []
labe1_pic = []
for filename in os.listdir(file_dir):
ls = file_dir + "\\" + filename
for subfilename in os.listdir(ls):
original_pic.append(ls + '\\' + subfilename)
labe1_pic.append(filename)
return np.asarray(original_pic), np.asarray(labe1_pic)
#乱序
def shuffle_image(image, label):
random.seed(1234)
random.shuffle(image)
random.seed(1234)
random.shuffle(label)
return image, label
Train_Path = r'.\train_image'
Test_Path = r'.\test_image'
BATCHSIZE = 5
epoches = 100000
isTrain=True
#获取图像路径和对应标签,做好训练集,验证集的比例
a, b = get_filename(Train_Path)
#c = get_Test_filename(Test_Path)
shuffle_image(a, b)
ratio = 0.9
s = np.int(b.shape[0] * ratio)
s0 = b.shape[0] - s
a_train = a[:s]
b_train = b[:s]
a_val = a[s:]
b_val = b[s:]
#这里使用的灰度图,所以最后一个维度是1,如果是彩色图,就是3
input_image = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 1])
y_true=tf.placeholder(dtype=tf.float32,shape=[None,10])
keep_prob = tf.placeholder(tf.float32)
data_x = np.zeros([BATCHSIZE, 100, 100, 1])
data_y = np.zeros([BATCHSIZE, 10])
y_ = Vgg_net(input_image,keep_prob)
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_))
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
if isTrain:
with tf.Session() as sess:
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
tf.summary.scalar('loss_gen', cross_entropy)
tf.summary.scalar('accuracy', accuracy)
writer = tf.summary.FileWriter('./my_graph/1', sess.graph)
summary_op = tf.summary.merge_all()
#训练
for epoch in range(1000000):
randnum = epoch % int(s / BATCHSIZE)
image_train = a_train[randnum * BATCHSIZE:(randnum + 1) * BATCHSIZE]
label_train = b_train[randnum * BATCHSIZE:(randnum + 1) * BATCHSIZE]
for j in range(BATCHSIZE):
imc = cv2.imread(image_train[j])
data_x[j, :, :, :] = imc
#看你标签的文件夹怎么取名了。
data_y[j, :] = [(label_train[j] == var) for var in
['000','001', '002', '003', '004', '005', '006', '007', '008', '009']]
_, accuracy_p, summary_op_p = sess.run([train_step , accuracy , summary_op],
feed_dict={input_image: data_x, y_true:data_y,keep_prob:0.5})
print('epoch:%d,coorect:%f' % (epoch, accuracy_p))
#验证,每当epoch达到1000,验证一次
if epoch % 1000 == 0:
randnum = np.random.randint(low=0, high=int(s0 / BATCHSIZE))
image_val = a_val[randnum * BATCHSIZE:(randnum + 1) * BATCHSIZE]
label_val = b_val[randnum * BATCHSIZE:(randnum + 1) * BATCHSIZE]
for k in range(BATCHSIZE):
imc = cv2.imread(image_val[k])
data_x[k, :, :, :] = imc
data_y[k, :] = [(label_val[k] == var) for var in
['000','001', '002', '003', '004', '005', '006', '007', '008', '009']]
accuracy_p = sess.run(accuracy, feed_dict={input_image: data_x, y_true: data_y,keep_prob:1.0})
print('val------------epoch:%d,coorect:%f' % (epoch,accuracy_p ))
#tensorboard上显示训练过程
if epoch % 10 == 0:
writer.add_summary(summary_op_p, epoch)
#保存模型
if epoch % 10000 == 0:
saver.save(sess, './myModel/model' + str(epoch / 10000) + '.cptk')
else:
with tf.Session() as sess:
#恢复模型
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint('myModel')
saver.restore(sess, ckpt)
#然后进行预测,就不写了
#xxxxxxxxxxxxxxxxxxx