太好用!图片转文字没有python环境也能运行了!!!
昨天菜鸟小白的分享——将图片中的文字提取出来,有不少小伙伴也都私信我,对我表示肯定,更是有小伙伴希望我将昨天的代码做成和之前一样的可执行文件。本来我是以为将整个程序完善了之后再打包为可执行文件的,既然已经有小伙伴私信要求了,那我就直接将这个打包了。公众号上私信回复“文字识别可执行文件”即可获取。
粉丝问题解答
有小伙伴拿了我之前图片漫画的程序,执行后出现如下报错
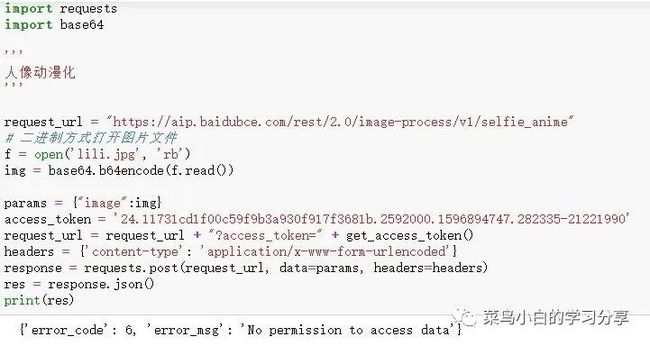
菜鸟小白看到后其实只能分析出这个应该是权限问题,首先我会先去查API文档中关于错误码的部分
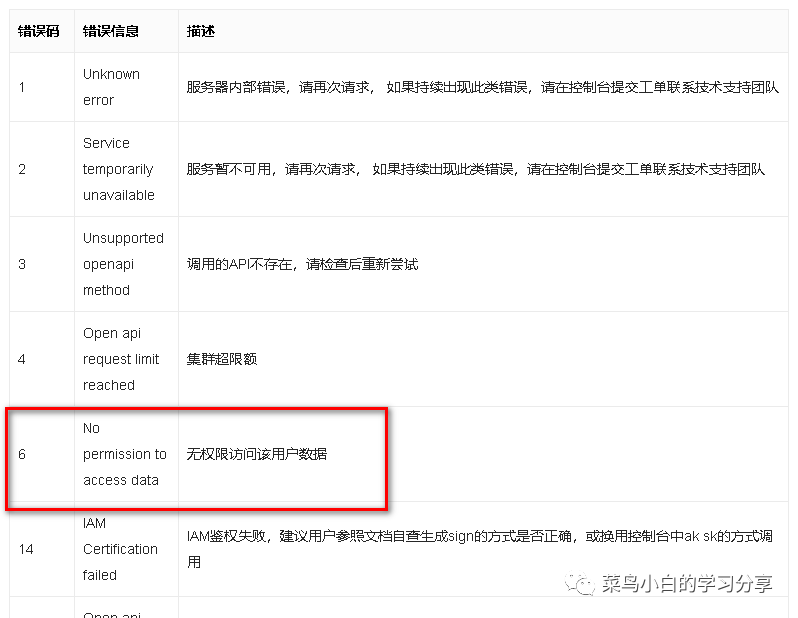
确实就是权限问题,但是这个还是没有给出我们解决方案,这个时候就需要我们去搜索了。我当时搜到这样一个文章,文章中是这样说的,遇到这样的问题是因为我们创建的应用API没有对应的权限,需要在应用中勾选上我们需要的API接口权限,然后向百度AI开放平台客服提工单开放对应权限即可。

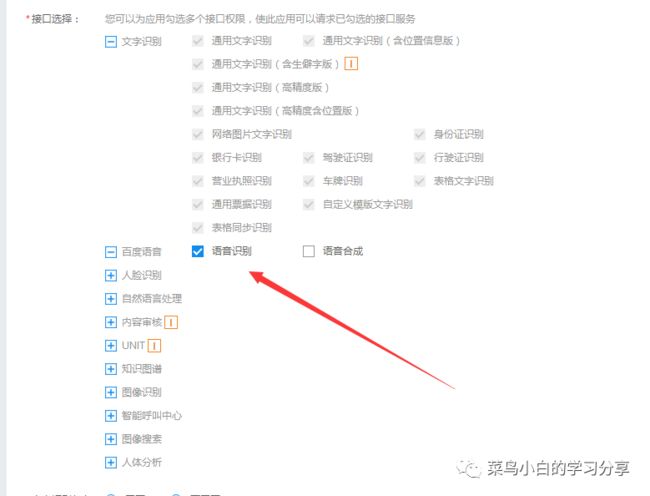
最终通过这样的方式我解决了这个问题,那个私信我的小伙伴,你现在是否清楚了呢。
今日编码分析
参数获取
今天我就将今天的代码改编做一下说明吧。首先我新增了参数获取函数,用于存放AK和SK信息(因为程序打包之后,这个信息就需要小伙伴申请后在程序外面保存,然后我们通过参数获取函数去读取)
def getconf():
config = {}
with open('config.txt', 'r') as f:
lines = f.read().splitlines()
for i in lines:
if i:
key, values = i.split(':')
config[key] = values
return config
文字识别和身份证识别
然后我们将昨天写的内容中参数获取这一块做了变化,将读取的参数传递给文字识别函数和身份证读取函数
#通用文字识别
def general_word(config):
#通用文字识别接口url
general_word_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
access_token = get_access_token(config)
image_names = input("请输入需要解析的图片(多张图片用英文,隔开):").split(",")
for i in image_names:
# 二进制方式打开图片文件
f = open(i, 'rb')
img = base64.b64encode(f.read())
params = {"image":img,
"language_type":"CHN_ENG"}
request_url = general_word_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
res = response.json()["words_result"]
file_name = "菜鸟小白的学习分享_图片"+i.split(".")[0]+".txt"
with open(file_name, 'w', encoding='utf-8') as f:
for j in res:
f.write(j["words"]+"\n")
#身份证识别
def idcard(config):
idcard_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/idcard"
access_token = get_access_token(config)
image_names = input("请输入需要识别的身份证图片(多张图片用英文,隔开):").split(",")
for i in image_names:
# 二进制方式打开图片文件
f = open(i, 'rb')
img = base64.b64encode(f.read())
params = {"id_card_side":"front","image":img}
request_url = idcard_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
res = response.json()["words_result"]
file_name = "菜鸟小白的学习分享_图片"+i.split(".")[0]+".txt"
with open(file_name, 'w', encoding='utf-8') as f:
f.write("住址:"+res["住址"]["words"]+"\n")
f.write("出生日期:" + res["出生"]["words"] + "\n")
f.write("姓名:" + res["姓名"]["words"] + "\n")
f.write("公民身份号码:" + res["公民身份号码"]["words"] + "\n")
f.write("性别:" + res["性别"]["words"] + "\n")
f.write("民族:" + res["民族"]["words"] + "\n")
银行卡识别
菜鸟小白还补充了一个银行卡的识别函数
#银行卡识别#银行卡识别
def bankcard(config):
#银行卡识别接口url
general_word_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/bankcard"
access_token = get_access_token(config)
image_names = input("请输入需要识别的银行卡图片(多张图片用英文,隔开):").split(",")
for i in image_names:
# 二进制方式打开图片文件
f = open(i, 'rb')
img = base64.b64encode(f.read())
params = {"image":img,}
request_url = general_word_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
res = response.json()["result"]
file_name = "菜鸟小白的学习分享_图片"+i.split(".")[0]+".txt"
with open(file_name, 'w', encoding='utf-8') as f:
f.write("卡号:" + res["bank_card_number"] + "\n")
f.write("有效期:" + res["valid_date"] + "\n")
f.write("银行:" + res["bank_name"] + "\n")```
主函数
最后我们根据读取的参数完成主函数的编写
if __name__ == '__main__':
config = getconf()
if config["Action Type"] == "1":
general_word(config)
elif config["Action Type"] == "2":
idcard(config)
elif config["Action Type"] == "3":
bankcard(config)
粉丝福利
菜鸟小白特意为支持我的小伙伴提供了腾讯视频会员月卡一张,关注公众号即可参与抽奖哦~
源码获取
老规矩,关注公众号“菜鸟小白的学习分享”回复“文字识别”即可获取最新源码。
好了,今天分享结束了。如果你也认同菜鸟小白的学习分享的话,那就给菜鸟小白一个关注、在看、点赞+赞赏吧,你们的支持,是我持续不断的动力。非常感谢大家的支持,我们明天再会~
![]()
往期推荐
python实现图片文字提取,准确率高达99%,强无敌!!!
通过server酱实现定时推送天气情况,再不用担心你的糊涂蛋女友忘带伞了~~
想做一个天气推送程序,却被和风天气API的示例代码调试得快吐了
六十来行python代码完成一个文件分类器
PDFtoWORD_V1.1版本支持PDF文档中的文字和图片一起转化到word文档中了~
媳妇儿让我给她找一个PDF转word免费工具,找了半天我决定给她写一个出来-
关注菜鸟小白的学习分享更多精彩等你发现!
一个人的学习——孤单
一群人的学习——幸福