FasterRCNN 理解(精简版总结)
RCNN系列的内容已经有非常多同学分享出来了,大多也非常详细。为了避免在长文中迷失方向,这里做个精简版的总结,记录个人的理解。主要是概括算法流程以及特点,方便回顾。先简单介绍下RCNN和Fast RCNN,在详细记录faster rcnn的RPN网络的理解。
RCNN:
1. 流程
(1). 采用传统方法Selective Search产生目标候选框
(2). 对每个候选框,用深度卷积神经网络提取特征得到feature map
(3). 每个框得到的feature map喂给SVM分类器,并通过线性回归调整bounding box的位置和大小,使得更接近 gt
2. 缺点:
(1)CNN网络参数不共享
(2)采用SVM分类器,速度慢
(3)产生后选框ROI的大小不一样,这样导致CNN输出与FC维度不统一

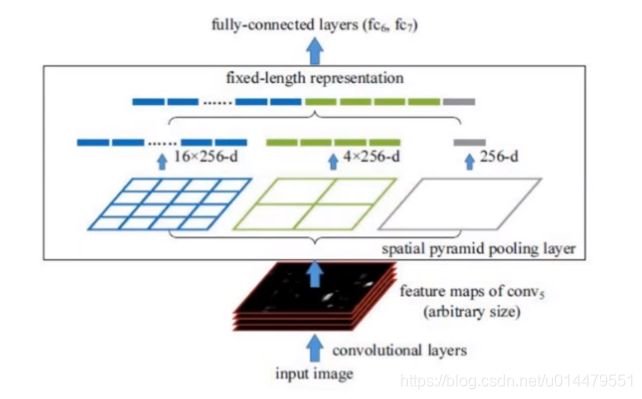
总的来说,RCNN比较笨,比较慢,进而提出SPP-net。SPP-net用CNN一次性提取特征,并利用空间金字塔池化(spatial pyramid pooling)将大小不一致的proposal变成大小一样的。
Fast RCNN
1. 流程:
(1)CNN提取输入图像特征,得到feature map
(2)从feature map得到ROIs
(3)ROI pooling之后通过softmax 对每个ROI进行分类,并通过BBox reg调整bbox的位置
2. 缺点:
(1)通过Selective Search得到ROI十分耗时

Faster RCNN
1. 流程:
(1)同样的用CNN提取输入图像的特征,得到feature map
(2)通过RPN网络从feature map得到候选框ROIs,并对ROIs进行二分类,判别候选框内容是前景还是背景,留下前景的候选框,抛弃背景候选框,并通过回归微调前景的BBox与标注gt接近。关于RPN网络的操作流程及细节,下文会阐述
(3)ROI pooling得到等size的feature,再送入多分类器
(4)通过多分类器对候选框进行多分类,即gt有几类,这个就会分成相应的类别
(5)再进行BBox回归
2. loss的组成部分:
由上述总体流程,可以得知faster rcnn整体的loss由四个部分组成:
(1)RPN网络进行二分类的loss(候选框是前景 or 背景)
(2)RPN网络前景BBox与gt微调的loss,BBox reg loss
(3)多分类的loss,从RPN网络得到的bbox进行多类别判断的loss
(4)最后每个类别BBox reg微调的loss

3. RPN网络
(1)RPN网络的输入是CNN得到的feature map,RPN在feature map上用3*3的滑动窗得到对应原图的多个候选框。
什么意思呢?feature map上的每一个点,都可以映射到原图的一个区域(即感受野)。对feature map 每个点,对应原图的区域,进行不同的形状大小变换,得到不同大小形状的框就是anchor box。这些框的尺寸和大小是预先设置好的。feature map上的每一个点就是原图区域anchoe box的中心点。为了使得覆盖范围更广,检测的物体更多,并保证效率,faster rcnn基于3个不同尺寸大小,3种不同尺度变换的anchor box做变换,对于feature map的每一个点,在原图区域得到9个anchor box。
(2)去掉超出图像边界的anchor box,把所有anchor box送入二分类层,判断每个anchor box是前景还是背景;同时把anchor box送入回归层,调整box与gt接近。


4. 关于RPN的补充
(1)cls 和reg层都是全卷积网络,用1*1的卷积核代替全连接
(2)anchor 具有平移不变性
(3)anchor的二分类时,有两个方法判断为正例:与gt有最大的IOU的anchor认为是正例;与gt的IOU大于0.7的anchor认为是正例
(4)对重复的box,用nms进行合并进行筛选。若box1和box2重复IOU大于0.7,看box1与box2哪个二分类正例的得分高,谁高保留谁
(5)关于感受野理解补充可参考这位博主:https://blog.csdn.net/program_developer/article/details/80958716