Hbase region in transition多个场景解决
1、问题描述:
hbase在使用过程中,后来创建了两个表,跑任务的时候,出现下面图片中的问题:region in transition
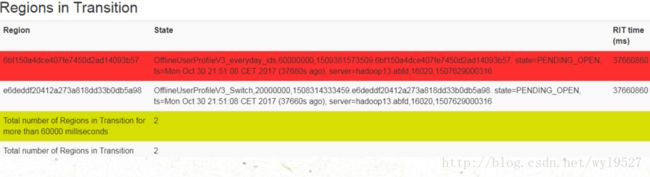
2、什么是RIT状态?
As regions are managed by the master and region servers to, for example, balance the load across servers, they go through short phases of transition. This applies to opening, closing, and splitting a region. Before the operation is performed, the region is added to the “Regions in Transition” list on the WEB UI, and once the operation is complete, it is removed.
只要有region处于RIT状态,balacer就无法运行。
3、解决方案一:
1、首先执行 hbase hbck -repair 修复指令,但是没有效果。然后想把出错的两个表给删除。但是发现怎么也删不掉,没办法,只有强制删除。
2、强制删除,首先找到hdfs上该表所在的位置,然后删除。

3、这时候,还要找到zk上的hbase中该表的节点位置,然后删除,否则当你在创建的 时候可能会报该表依然存在的问题
![]()
4、然后再执行修复指令
[hadoop@namenode2 ~]$ hbase hbck -repair
几分钟后可以看到region in transition的问题已经没有了。
5、最后你可能遇到下面的负载均衡的问题
The Load Balancer is not enabled which will eventually cause performance degradation in HBase as Regions will not be distributed across all RegionServers. The balancer is only expected to be disabled during rolling upgrade scenarios.解决方案:
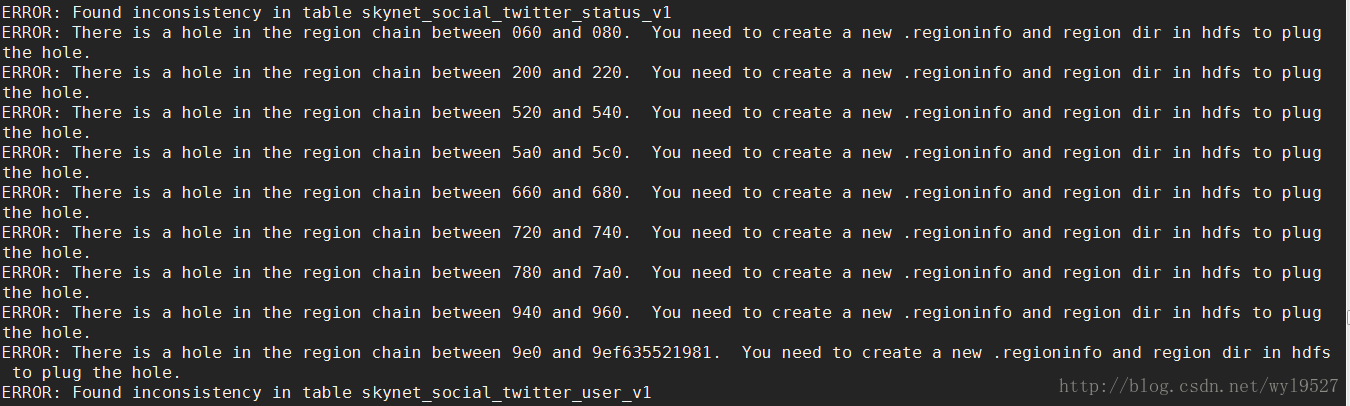
4、第二种出现的情况日志如下:
下面的两个截图日志是hbase hbck查看的。
[hadoop@namenode2 hbase]$ hbase hbckERROR: Region { meta => skynet_social_twitter_user_v1,200,1497323242783.92a07b5621834f8cea20c8cc58caa159., hdfs => hdfs://abfdhadoop/hbase/data/default/skynet_social_twitter_user_v1/92a07b5621834f8cea20c8cc58caa159, deployed => , replicaId => 0 } not deployed on any region server
ERROR: There is a hole in the region chain between 24000000 and 26000000. You need to create a new .regioninfo and region dir in hdfs to plug the hole.
解决方案:
之前采用hbck的各种修复都无果,看到matser上的日志信息,看到有可能跟hadoop7这个机器上的regionserver服务有关,所以就重启了该服务,结果发现ok了,也不太清楚啥情况,后续再研究研究。。。
重启三步骤:
- 第一步:关闭balance,防止在停掉服务后,原先节点上的分片会迁移到其他节点上,到时候在移回来,浪费时间。
hbase(main):001:0> balance_switch false
false - 第二步:平滑的重启单个节点的regionserver。
[hadoop@namenode2 hbase]$ bin/graceful_stop.sh hadoop7.abfd- 第三步:重启
[hadoop@namenode2 hbase]$ bin/graceful_stop.sh --restart hadoop7.abfd
查看matser上的日志:
具体的一些细节问题可参考以下博客链接:
http://community.cloudera.com/t5/Storage-Random-Access-HDFS/HBase-Region-in-Transition/td-p/26703
http://blog.csdn.net/liliwei0213/article/details/53639275
http://eclecl1314-163-com.iteye.com/blog/1704249
http://hbasefly.com/2016/09/08/hbase-rit/