卷积神经网络训练花卉识别分类器
介绍
本部分是花卉分类器,后续会有更为详细的更新。
花卉分类器使用语言:Python,使用深度学习框架:PyTorch,方法:训练卷积神经网络
关于PyTorch的基本用法可以参考博客:PyTorch笔记
Gitee仓库:花卉识别
Github仓库:花卉识别
Git相关用法可以参考博客:Git使用笔记
数据集
目前选用了20种花卉数据用于分类
data文件夹内存放了我使用的20种花卉数据集。日后会继续扩增。
数据来源主要取决于3个方面:
- 5种花卉数据集,每类花卉包含600张到900张不等的图片
- 来源于Oxford 102 Flowers数据集,该数据集包含102类英国花卉数据,每个类别包含 40 到 258 张图像
- 最后一部分来源于百度图片,使用python程序批量采集花卉图像数据
有些花卉的name是我自己写的,采用的是花卉的学名,通常是拉丁文。
我选用的20种花卉数据如下所示:
| 编号 | name | 名称 | 数量 |
|---|---|---|---|
| 1 | daisy | 雏菊 | 633 |
| 2 | dandelion | 蒲公英 | 898 |
| 3 | roses | 玫瑰花 | 641 |
| 4 | sunflowers | 向日葵 | 699 |
| 5 | tulips | 郁金香 | 799 |
| 6 | Nymphaea | 睡莲 | 226 |
| 7 | Tropaeolum_majus | 旱金莲 | 196 |
| 8 | Digitalis_purpurea | 毛地黄 | 190 |
| 9 | peach_blossom | 桃花 | 55 |
| 10 | Jasminum | 茉莉花 | 60 |
| 11 | Matthiola | 紫罗兰 | 54 |
| 12 | Rosa | 月季 | 54 |
| 13 | Rhododendron | 杜鹃花 | 57 |
| 14 | Dianthus | 康乃馨 | 48 |
| 15 | Cerasus | 樱花 | 50 |
| 16 | Narcissus | 水仙花 | 52 |
| 17 | Pharbitis | 牵牛花 | 46 |
| 18 | Gazania | 勋章菊 | 108 |
| 19 | Eschscholtzia | 花菱草 | 82 |
| 20 | Tithonia | 肿柄菊 | 47 |
花卉样式:

数据扩展
收集到的每种花卉数量不是很多,而像樱花、水仙花等都是每类50张左右,数据量过少,若直接拿去训练模型的话,正确率不会太高,且会发生严重的过拟合。
目前使用的数据扩展方法分为三种:镜像翻转、上下翻转和椒盐噪声。
镜像翻转:将图片左右翻转,生成新的数据

上下翻转:将图片上下翻转,生成新的数据

椒盐噪声:为图片增加噪声,生成新的数据

扩展后的花卉数量如下所示:
| 编号 | name | 名称 | 数量 | 增量后数量 |
|---|---|---|---|---|
| 1 | daisy | 雏菊 | 633 | 2496 |
| 2 | dandelion | 蒲公英 | 898 | 3588 |
| 3 | roses | 玫瑰花 | 641 | 2400 |
| 4 | sunflowers | 向日葵 | 699 | 2796 |
| 5 | tulips | 郁金香 | 799 | 3196 |
| 6 | Nymphaea | 睡莲 | 226 | 1808 |
| 7 | Tropaeolum_majus | 旱金莲 | 196 | 1568 |
| 8 | Digitalis_purpurea | 毛地黄 | 190 | 1360 |
| 9 | peach_blossom | 桃花 | 55 | 440 |
| 10 | Jasminum | 茉莉花 | 60 | 480 |
| 11 | Matthiola | 紫罗兰 | 54 | 432 |
| 12 | Rosa | 月季 | 54 | 432 |
| 13 | Rhododendron | 杜鹃花 | 57 | 456 |
| 14 | Dianthus | 康乃馨 | 48 | 384 |
| 15 | Cerasus | 樱花 | 50 | 400 |
| 16 | Narcissus | 水仙花 | 52 | 416 |
| 17 | Pharbitis | 牵牛花 | 46 | 368 |
| 18 | Gazania | 勋章菊 | 108 | 464 |
| 19 | Eschscholtzia | 花菱草 | 82 | 656 |
| 20 | Tithonia | 肿柄菊 | 47 | 376 |
数据切分
数据集准备好了,要切分为训练集、验证集和测试集。
在PyTorch的torchvision包内有一个关于计算机视觉的数据读取类ImageFolder,它的调用方式是torchvision.datasets.ImageFolder,主要功能是读取图片数据,且要求图片是下图这种存放方式。
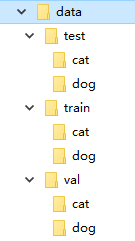
然后这样来调用类:
train_dataset = ImageFolder(root='./data/train/',transform=data_transform)
root表示根目录,transform表示数据预处理方式。
这种方式将train目录下的cat和dog文件夹内的所有图片作为训练集,而文件夹名cat和dog作为标签数据进行训练。
因此我们就要像ImageFolder要求的那样切分数据集。

我切分的比例是3:1:1。实际上,如果不想切分出验证集的话,可以将验证集的代码部分注掉,直接使用训练集和测试集也是可以的。
#比例
scale = [0.6, 0.2, 0.2]
至此,数据部分准备完成了。
模型训练
目前采用的是AlexNet和VGG16两种网络,其实两种网络比较相似,不同的是VGG16较于AlexNet更“深”
AlexNet网络结构如下:
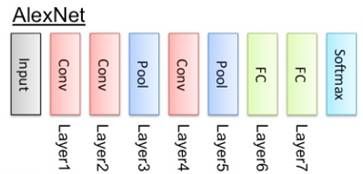
VGG16网络结构如下:
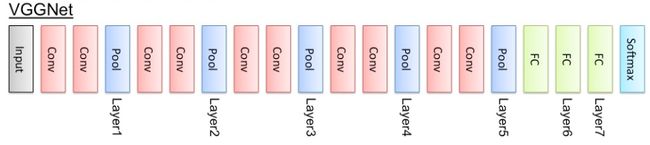
二者相比较,VGG16准确率更高一些,可见更深的网络对于提高准确率有一定的帮助。
AlexNet训练过程中的准确率变化如下:

VGG16经历200个epoch训练的准确率变化如下:

AlexNet经历了500个epoch训练后最终能达到83%的准确率
VGG16经历了200个epoch训练后最终能达到90%的正确率
以上两种训练的模型参数我都保存到了仓库内

模型验证
除了验证测试集以外,还可以用图片去验证模型的训练效果。
选用的是验证效果比较好的VGG16网络,读取的参数是200个epoch训练后的参数


可以看到,测试的效果还是非常好的,模型可以非常准确的判断花卉的种类。
一个补充
如果你恰好有个云服务器,又想做一个web服务器的话,可以尝试flask框架(当然在本地也可以使用flask,不过这个就没有多大意义了)
按照flask文件夹中的程序,在服务器上运行之后,然后打开一个新网页,输入IP:端口?图片地址就可以做识别了。

其中sjcup.cn是我的一个域名,这里可以替换为自己服务器的公网IP
另外还有一个坑就是图片名称不可为中文名称,否则会检测不到
公网IP无法访问的问题可以根据博客做一些修改
下一步计划
- 扩增数据集,可以识别更多类别的花卉
- 采用新的网络训练,如Inception V3