强化学习实例3:Q-Learning和Q-Network
The Frozen Lake environment,有4 x 4网格代表湖面,有16个状态,其中S,H,F和G代表不同的格子块,4个行为(上下左右)
- S:开始块
- F:冰块
- H:洞
- G:目标块

Q-Learning
包括Q-table(16x4)和Q-value

import gym
import numpy as np
import time
env = gym.make("FrozenLake-v0")
s = env.reset()
print(s)
env.render()
print(env.action_space)
print(env.observation_space)
print("Number of actions : ",env.action_space.n)
print("Number of states : ",env.observation_space.n)
def epsilon_greedy(Q, s, na):
epsilon = 0.3
p = np.random.uniform(low=0, high=1)
if p > epsilon:
return np.argmax(Q[s,:])
else:
return env.action_space.sample()
Q = np.zeros([env.observation_space.n, env.action_space.n])
lr = 0.5
y = 0.9
eps = 100000
for i in range(eps):
s = env.reset()
t = False
while (True):
a = epsilon_greedy(Q, s, env.action_space.n)
s_, r, t, _ = env.step(a) # r为立即回报,1为到达终点,否则为0
if (r==0):
if t==True: # 进洞
r = -5
Q[s_] = np.ones(env.action_space.n) * r
else:
r = -1
if (r==1):
r = 100
Q[s_] = np.ones(env.action_space.n) * r
Q[s,a] = Q[s,a] + lr*(r + y*np.max(Q[s_,a]) - Q[s,a])
s = s_
if (t == True): # 是否结束,掉进洞或到达终点
env.render()
break
print("Q-table")
print(Q)
# 测试
s = env.reset()
env.render()
while (True):
print(s)
a = np.argmax(Q[s])
s_, r, t, _ = env.step(a)
env.render()
s = s_
if (t == True):
break
Q-Network
使用神经网络代替Q-table,这里使用简单的全连接网络,输入1x16,输出1x4
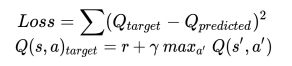
import gym
import numpy as np
import tensorflow as tf
import random
from matplotlib import pyplot as plt
env = gym.make("FrozenLake-v0")
print("构建网络。。。")
tf.reset_default_graph()
# 输出观察状态
inputs = tf.placeholder(shape=[None, env.observation_space.n], dtype=tf.float32)
W = tf.get_variable(name="W", dtype=tf.float32,
shape=[env.observation_space.n, env.action_space.n],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.zeros(shape=[env.action_space.n]), dtype=tf.float32)
qpred = tf.add(tf.matmul(inputs, W), b)
apred = tf.argmax(qpred, 1) # 最大行为
# y label
qtar = tf.placeholder(shape=[1, env.action_space.n], dtype=tf.float32)
loss = tf.reduce_sum(tf.square(qtar - qpred))
train = tf.train.AdamOptimizer(learning_rate=0.001)
minimizer = train.minimize(loss)
init = tf.global_variables_initializer()
# 学习参数
y = 0.5
e = 0.3
episodes = 100000
slist = []
rlist = []
print("训练网络。。。")
sess = tf.Session()
sess.run(init)
for i in range(episodes):
s = env.reset()
r_total = 0
while (True):
# Q-network, 相对于Q[s,a]
a_pred, q_pred = sess.run([apred, qpred],
feed_dict={inputs: np.identity(env.observation_space.n)[s:s+1]})
if np.random.uniform(low=0, high=1) < e: # epsilon greedy
a_pred[0] = env.action_space.sample()
# 下一个状态和行为
s_, r, t, _ = env.step(a_pred[0])
if r==0:
if t==True: # 进洞
r = -5
else:
r = -1
if r==1: # 到达目标块
env.render()
r = 5 # 目标状态
# 下一个状态的回报 相对于Q[s_,a]
q_pred_new = sess.run(qpred,
feed_dict={inputs: np.identity(env.observation_space.n)[s_:s_+1]})
targetQ = q_pred
max_qpredn = np.max(q_pred_new)
targetQ[0: a_pred[0]] = r + y*max_qpredn
# 最小化
_ = sess.run(minimizer,
feed_dict={
inputs: np.identity(env.observation_space.n)[s:s+1],
qtar: targetQ})
r_total += r
s = s_
if t == True: # 结束游戏
break
# 测试
s = env.reset()
env.render()
while(True):
a = sess.run(apred,
feed_dict={inputs: np.identity(env.observation_space.n)[s:s+1]})
s_, r, t, _ = env.step(a[0])
env.render()
s = s_
if t == True:
break相比之下Q-Network提供更灵活的tweaks