YOLO系列算法(v3v4)损失函数详解
YOLO算法是One-Stage目标检测算法的开山之作,一面世就注定不平凡。而在监督学习中,损失函数指导着模型的学习方向,占据着非常重要的地位。今天就由笔者来给大家讲解YOLO系列算法的损失函数。由于原版YOLO算法使用C语言编写,可能晦涩难懂,所以这里笔者选择了百度飞桨PaddleDetection(版本0.3.0)中复现的YOLOv3为例进行讲解,项目地址 https://github.com/PaddlePaddle/PaddleDetection
相信你看完这篇文章,再看YOLOv4的代码或许就突然豁然开朗了,因为损失函数部分是差不多的。好了废话不多说,下面进入正题。本文基于读者对YOLOv3算法有一定了解。
YOLOv3算法,如果你看过关于它的博客或一些第三方实现的话会知道,它有3个输出张量,这三个输出张量的形状是(bz,3*(4+1+80), 13, 13),(bz,3*(4+1+80), 26, 26),(bz,3*(4+1+80), 52, 52)。其中的bz代表批大小,3代表一个格子会出3个预测框,而4+1+80代表一个预测框会携带有85位信息,前4位代表预测框的中心位置xy以及大小wh,第5位代表置信度,表示该预测框是前景的概率,最后的80位代表如果是前景,那么预测框是80种物体的概率(COCO数据集中类别数是80)。然后后面的13、26、52就是代表一行(一列)的格子数了。第一个张量,形状是(bz,3*(4+1+80), 13, 13),代表它输出了13x13个网格,预测框数目是bz*3*13*13;第二个张量,形状是(bz,3*(4+1+80), 26, 26),代表它输出了26x26个网格,预测框数目是bz*3*26*26;第三个张量,形状是(bz,3*(4+1+80), 52, 52),代表它输出了52x52个网格,预测框数目是bz*3*52*52。
这三个张量就构成了YOLOv3的输出。这里也有必要再讲解一个知识点——感受野。感受野即CNN能看到的视野大小。比如,一个3x3的卷积层,卷积核个数=1,步长stride=1,padding=1,一个形状为(N, C, H, W)的张量tensor1,经过这个卷积层之后,变成了形状为(N, 1, H, W)的张量tensor2。那么新张量tensor2一个像素里包含了tensor1多少个像素的信息呢?3x3=9个。张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素9宫格像素的内容,也就是说张量tensor2感受野是3x3大小了。假如我把卷积层换成了1x1卷积层呢?那么只能“看到”原始特征图张量tensor1相同位置像素的内容,也就是说张量tensor2感受野是1x1大小。我再变点花样,tensor1经过了2个卷积层,第一个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,第二个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,tensor1经过了这2个卷积层变成了张量tensor2,敢问张量tensor2感受野大小?5x5,张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素附近5x5像素的内容。我再变点花样,tensor1经过了2个卷积层,第一个卷积层是3x3大小,卷积核个数=1,步长stride=2,padding=1,第二个卷积层是3x3大小,卷积核个数=1,步长stride=1,padding=1,tensor1经过了这2个卷积层变成了张量tensor2,敢问张量tensor2感受野大小?7x7,张量tensor2的一个像素“看到了”原始特征图张量tensor1相同位置像素附近7x7像素的内容。我们可以看到,叠加卷积层可以扩大感受野大小,卷积步长也会影响感受野大小。
回到正题,我们的这3个输出张量中,13x13的张量有大感受野,它会被分配到3个最大尺度的先验框,26x26的张量有中感受野,它会被分配到3个中等尺度的先验框,52x52的张量有小感受野,它会被分配到3个最小尺度的先验框。这样,这一层每个格子都会被分到3个先验框,分别给了这个格子的3个预测框使用。毕竟是监督学习,监督信息也必须要有,我们的label张量也是差不多同样的形状。在PaddleDetection中,训练时会先预处理图片,比如读图片、进行数据增强、坐标归一化、随机尺度、随机插值等,数据预处理最后阶段就是Gt2YoloTarget,Gt2YoloTarget()类里就准备好了我们的label张量,我们看看它的神秘面纱:
...
grid_h = int(h / downsample_ratio)
grid_w = int(w / downsample_ratio)
target = np.zeros((len(mask), 6 + self.num_classes, grid_h, grid_w), dtype=np.float32)
for b in range(gt_bbox.shape[0]):
gx, gy, gw, gh = gt_bbox[b, :]
cls = gt_class[b]
...即target,形状是(3,(6+80), grid_h, grid_w),没有批大小那一维是因为是在遍历每一张图片,后面会拼接这一批所有图片的target(不同的输出层分开拼接)。3代表每个格子有3个预测框的注解,(6+80)就有点迷,小编,你刚才不是说每个预测框会输出85位信息的吗?没错,但是我们的label可以带多一些信息,后面你也会看到,我们带多了另外的张量来在训练过程中确定负样本。我们继续看:
...
# x, y, w, h, scale
target[best_n, 0, gj, gi] = gx * grid_w - gi
target[best_n, 1, gj, gi] = gy * grid_h - gj
target[best_n, 2, gj, gi] = np.log(gw * w / self.anchors[best_idx][0])
target[best_n, 3, gj, gi] = np.log(gh * h / self.anchors[best_idx][1])
target[best_n, 4, gj, gi] = 2.0 - gw * gh
# objectness record gt_score
target[best_n, 5, gj, gi] = score
# classification
target[best_n, 6 + cls, gj, gi] = 1.
...找到了!这是某个预测框被选定为正样本时需要做的事。我们看到,0、1位用来监督xy,2、3位用来监督wh,第4位填了一个权重,即2 - gw*gh,由于预处理阶段gw、gh进行了归一化,所以这个权重表示的是“2.0 - gt的面积/输入图片大小的面积”,亦即“2.0 - gt面积占图片面积的比重”。第4位表明,若gt面积越小,权重越接近2,若gt面积越大,权重越接近1。这个权重叫做tscale,在后面的xywh损失、iou损失计算那里都会乘上,注意这些损失都是和预测框的位置有关。而分类损失和预测框位置无关,不用乘tscale。乘以tscale表明,若gt越小,它应该越受到重视,由此改善小目标检测。然后第5位是置信度,是填的score,如果你没用mixup增强,会是1,用了mixup增强,它会是0~1之间的一个数值;由于mixup融合了两张图片,gt它不能100%是它了(因为它变透明了),你可以这样理解。最后填的是类别向量,真实类别处填1,其余保持为0。没有用smooth_onehot。
上面说到如果某个预测框被选定为正样本,将如何填写target张量。那么某个预测框是如何被选定为正样本的呢?抱歉我总是喜欢倒叙。仔细看看代码,你会发现是这样的。遍历所有的gt框,计算它的中心点坐标,它的中心点坐标会落在3个格子里(大感受野输出层、中感受野输出层、小感受野输出层各占1个格子),这3个格子每个格子带有3个先验框共计9个先验框。我们计算这个gt和9个先验框的iou(计算时假设gt和先验框的中心点位置相同),与gt有最大iou的先验框所在的预测框被选定为正样本(哈哈,你就是天选之人!),这样,正样本就确定了。再仔细看看代码,你会发现给正样本框填写label的地方有两处,第二处和self.iou_thresh变量有关,这是怎么回事呢?原来,原版YOLOv3的策略是一个gt只分配给了一个预测框,在这里,PaddleDetection的大佬们为了让YOLOv3预测出更多的物体,允许一个gt分配给多个预测框,具体策略就是,先把gt分配给最高iou先验框所在的预测框,这时候3个格子的所有9个预测框还剩下8个,假如它们持有的先验框与gt的iou>self.iou_thresh,它们也会被选为正样本。
好了,Gt2YoloTarget()类里的最后你发现每张图片(也就是每个sample字典)target有3个,分别对应3个不同感受野的输出层。再然后,PaddleDetection会拼接这一批所有图片的target(不同的输出层分开拼接),也就是说,这一批样本携带有3个target,形状分别是(bz, 3, 86, l_grid, l_grid)、(bz, 3, 86, m_grid, m_grid)、(bz, 3, 86, s_grid, s_grid),由于是多尺度训练, l_grid、m_grid、s_grid和被选到的尺度有关,假如被选到的尺度是416,那么l_grid、m_grid、s_grid就是13、26、52,它们分别是416除以32、16、8得到。13x13的输出层,因为经历过了5个步长是2的卷积,分辨率缩小为原来的1/2^5,即下采样倍率是32。
而且,数据预处理阶段,我们的sample字典(也就是一张图片)一直带有一个gt_bbox,它的形状是(num_max_boxes, 4),num_max_boxes默认是50,在PadBox()预处理那里,如果gt_bbox的数量少于num_max_boxes,那么填充坐标是0的bboxes以凑够num_max_boxes。在这里,我们也拼接了这一批所有图片的gt_bbox,得到一个形状是(bz, num_max_boxes, 4)的label张量gt_bbox,后面看到,我们利用它在训练过程中确定负样本。
我们终于把标记准备好了,现在,图片张量进入了网络进行了前向传播,输出了3个预测张量,这三个预测张量和我们的label张量开始计算损失了!
PaddleDetection版YOLOv3是逐层逐图片计算损失,也就是它是先遍历3个输出层,如下图所示:
def _get_fine_grained_loss(self, outputs, targets, gt_box, batch_size,
num_classes, mask_anchors, ignore_thresh):
assert len(outputs) == len(targets), \
"YOLOv3 output layer number not equal target number"
loss_xys, loss_whs, loss_objs, loss_clss = [], [], [], []
if self._iou_loss is not None:
loss_ious = []
if self._iou_aware_loss is not None:
loss_iou_awares = []
for i, (output, target,
anchors) in enumerate(zip(outputs, targets, mask_anchors)):
downsample = self.downsample[i]
an_num = len(anchors) // 2
if self._iou_aware_loss is not None:
ioup, output = self._split_ioup(output, an_num, num_classes)
'''
x: [-1, 3, -1, -1]
obj: [-1, 3, -1, -1]
cls: [-1, 3, -1, -1, 80]
'''
x, y, w, h, obj, cls = self._split_output(output, an_num,
num_classes)
'''
tx: [-1, 3, -1, -1] tx是0到1的数值,0.3表示gt中心点位于格子边长的30%处。从loss_x处可以看出。
tw: [-1, 3, -1, -1] tw是根据yolo的输出公式将gt的w编码后的值。从loss_w处可以看出。
tscale: [-1, 3, -1, -1] tscale填的是 2.0 - gw * gh,也就是2.0 - gt面积/图片面积
tobj: [-1, 3, -1, -1] tobj要么是0要么是1
tcls: [-1, 3, -1, -1, 80] tcls类别向量是one-hot形式,真实类别处填1
'''
tx, ty, tw, th, tscale, tobj, tcls = self._split_target(target)
# tobj带上了面积权重
tscale_tobj = tscale * tobj
loss_x = fluid.layers.sigmoid_cross_entropy_with_logits(
x, tx) * tscale_tobj
loss_x = fluid.layers.reduce_sum(loss_x, dim=[1, 2, 3])
loss_y = fluid.layers.sigmoid_cross_entropy_with_logits(
y, ty) * tscale_tobj
loss_y = fluid.layers.reduce_sum(loss_y, dim=[1, 2, 3])
# NOTE: we refined loss function of (w, h) as L1Loss
loss_w = fluid.layers.abs(w - tw) * tscale_tobj
loss_w = fluid.layers.reduce_sum(loss_w, dim=[1, 2, 3])
loss_h = fluid.layers.abs(h - th) * tscale_tobj
loss_h = fluid.layers.reduce_sum(loss_h, dim=[1, 2, 3])
if self._iou_loss is not None:
loss_iou = self._iou_loss(x, y, w, h, tx, ty, tw, th, anchors,
downsample, self._batch_size)
loss_iou = loss_iou * tscale_tobj
loss_iou = fluid.layers.reduce_sum(loss_iou, dim=[1, 2, 3])
loss_ious.append(fluid.layers.reduce_mean(loss_iou))
if self._iou_aware_loss is not None:
loss_iou_aware = self._iou_aware_loss(
ioup, x, y, w, h, tx, ty, tw, th, anchors, downsample,
self._batch_size)
loss_iou_aware = loss_iou_aware * tobj
loss_iou_aware = fluid.layers.reduce_sum(
loss_iou_aware, dim=[1, 2, 3])
loss_iou_awares.append(fluid.layers.reduce_mean(loss_iou_aware))
#scale_x_y = self.scale_x_y if not isinstance(
# self.scale_x_y, Sequence) else self.scale_x_y[i]
loss_obj_pos, loss_obj_neg = self._calc_obj_loss(
output, obj, tobj, gt_box, self._batch_size, anchors,
num_classes, downsample, self._ignore_thresh)
loss_cls = fluid.layers.sigmoid_cross_entropy_with_logits(cls, tcls)
loss_cls = fluid.layers.elementwise_mul(loss_cls, tobj, axis=0)
loss_cls = fluid.layers.reduce_sum(loss_cls, dim=[1, 2, 3, 4])
loss_xys.append(fluid.layers.reduce_mean(loss_x + loss_y))
loss_whs.append(fluid.layers.reduce_mean(loss_w + loss_h))
loss_objs.append(
fluid.layers.reduce_mean(loss_obj_pos + loss_obj_neg))
loss_clss.append(fluid.layers.reduce_mean(loss_cls))
losses_all = {
"loss_xy": fluid.layers.sum(loss_xys),
"loss_wh": fluid.layers.sum(loss_whs),
"loss_obj": fluid.layers.sum(loss_objs),
"loss_cls": fluid.layers.sum(loss_clss),
}
if self._iou_loss is not None:
losses_all["loss_iou"] = fluid.layers.sum(loss_ious)
if self._iou_aware_loss is not None:
losses_all["loss_iou_aware"] = fluid.layers.sum(loss_iou_awares)
return losses_allfor i, (output, target, anchors) in enumerate(zip(outputs, targets, mask_anchors))那里就是开始遍历3个输出层,downsample = self.downsample[i]即获取这一输出层的下采样倍率,第0个输出层是32,即一个格子的边长是32像素。an_num = len(anchors) // 2,即本层每个格子有3个预测框。self._split_output()即将本层的输出output切分,获得x, y, w, h, obj, cls,关于它们的形状已经在注释中给出,x : [-1, 3, -1, -1]是每个预测框输出的x,第0维表示是这一批的哪一张图片,第2、3维表示是哪个格子,第1维表示的是是这个格子的第几个预测框(共3个)。obj同理。cls形状是[-1, 3, -1, -1, 80],第4维表示的是这一个预测框的80个类别的概率。以上说的是预测张量的。接着是对label张量进行切分,即self._split_target(),与self._split_output()差不多,只是多了一个tscale,即上文说到的2.0-gt面积/图片面积。
首先计算的是x的损失,用的是二值交叉熵损失,注意这里不用对x做一次sigmoid()操作,因为fluid.layers.sigmoid_cross_entropy_with_logits(x, tx)里会对x做sigmoid()激活操作。还要乘多一个tscale_tobj,这样,就只对正样本计算了损失,而且带上了上文所说的面积权重。负样本不会计算x损失,因为负样本的tobj处是0,0乘任何数都得0,也就是说负样本的x损失是0,而常数0的导数是0,也就是说负样本不会得到梯度。接着是计算y的损失,也是用的二值交叉熵。这里说的x、y指的是预测框中心点坐标的xy,而且这些xy只能是0到1之间的数值,所以解码时要使用sigmoid激活。0~1之间的数值表示的是预测框中心点坐标位于这个格子的百分之多少处。这样就把预测框的中心点限制在了这个格子内。我们在填写target张量时,tx ty填写的是gx * grid_w - gi、gy * grid_h - gj,这也是0~1的数值,代表着同样的意义。单位1表示的都是格子的边长而并非是1像素。
接着是计算wh的损失,用的是绝对值损失,也就是L1损失。YOLOv3的坐标解码公式如下:
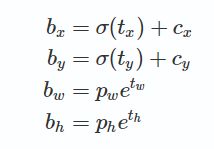
我们这里的w、h即公式里的tw th,我们直接在输出tw th时监督,而不是解码成bw bh时监督,所以才会在填写target张量时在w那里写入ln(bw/pw),在x那里写入(bx-cx)。我们是在未解码w h 时监督的,用的绝对值损失。同样,也只有正样本才计算wh损失,带上了面积权重。
接着是计算iou损失,这一项是为了辅助监督预测框的坐标和大小,作为xywh损失的补充。它同样乘上了tscale_tobj,即只计算正样本的损失。iou损失,即我们希望预测框和gt之间的iou尽可能大,iou即交并比。计算iou损失时,就真的需要把上述的xywh解码成bx by bw bh,用上面的公式。再和gt框计算iou损失。
iou_aware_loss,最新的43.6精度的模型使用了这个损失,由于笔者也没仔细看过,暂时不讲。
最后两个损失是置信度损失和分类损失。先讲分类损失,即loss_cls,它和xy损失是一样的,用的是二值交叉熵。填写target时,真实类别处填了1,其余79位填了0,是onehot形式的。二值交叉熵常用于作为分类损失。和xy损失一样,也只有正样本才计算分类损失。
最后将置信度损失,即loss_obj,这个损失是最复杂的损失,所以放到最后讲。注意,前面讲到的损失都是只有正样本才计算损失,因为只有正样本才会有xywh类别 这些属性,才会监督。而负样本(即背景框)是没有xywh类别 这些属性的,不需要计算这些损失。只有置信度损失才计算负样本的,因为我们希望负样本(即背景框)输出的置信度是接近0的,这样在预测的时候才可以把背景框过滤掉。说到负样本,肯定有正样本(即前景框)了,刚才我们说到的损失,都是只计算了正样本框的损失,而且可能你也发现了,正样本在数据预处理阶段(即Gt2YoloTarget()类里)就已经确定好了,根据gt中心点落在了哪3个格子(每个输出层各1个),和这3个格子持有的共9个先验框计算iou,最高iou的先验框对应的预测框就被选为了正样本,然后填写它的xywh、置信位、面积权重、类别onehot。但是负样本的确定有点不同,在这一批图片经过网络的前向传播后,开始计算损失时,才会确定负样本。而且,不仅仅有负样本,还有一种样本叫做“忽略样本”,“忽略样本”不参与置信度损失的计算。YOLOv3算法,训练时一共这3种样本(对置信度损失而言)。我们来看看源代码,计算置信度损失的代码在函数self._calc_obj_loss()里:
def _calc_obj_loss(self, output, obj, tobj, gt_box, batch_size, anchors,
num_classes, downsample, ignore_thresh):
# A prediction bbox overlap any gt_bbox over ignore_thresh,
# objectness loss will be ignored, process as follows:
# 将output解码为bbox,用博客里提供的公式,这里用了飞桨官方的API fluid.layers.yolo_box()。
# bbox的形状是[batch_size, -1, 4],比如[batch_size, 13*13*3, 4],bbox的坐标表示的是左上角坐标+右下角坐标。img_size 设为 1.0 以归一化bbox,即bbox的坐标都是0~1之间的数值,表示的是在图片宽高的百分之多少处。
# prob的形状是[batch_size, -1, 80],比如[batch_size, 13*13*3, 80],prob是每个预测框的置信位分别乘以自己的80个类别的预测概率得到的。也就是YOLOv3的“分数”公式。fluid.layers.yolo_box()中会对置信位做sigmoid()激活操作,对所有预测框80个类别位做sigmoid()激活操作,二者相乘,就得到了prob
bbox, prob = fluid.layers.yolo_box(
x=output,
img_size=fluid.layers.ones(
shape=[batch_size, 2], dtype="int32"),
anchors=anchors,
class_num=num_classes,
conf_thresh=0.,
downsample_ratio=downsample,
clip_bbox=False)
# 2. 将这一批每张图片切成一个独立的张量,组合成一个list
if batch_size > 1:
preds = fluid.layers.split(bbox, batch_size, dim=0)
gts = fluid.layers.split(gt_box, batch_size, dim=0)
else:
preds = [bbox]
gts = [gt_box]
probs = [prob]
ious = []
# 遍历这一批的每张图片
for pred, gt in zip(preds, gts):
def box_xywh2xyxy(box):
x = box[:, 0]
y = box[:, 1]
w = box[:, 2]
h = box[:, 3]
return fluid.layers.stack(
[
x - w / 2.,
y - h / 2.,
x + w / 2.,
y + h / 2.,
], axis=1)
pred = fluid.layers.squeeze(pred, axes=[0]) # [3*grid_h*grid_w, 4],即去掉第0维。
gt = box_xywh2xyxy(fluid.layers.squeeze(gt, axes=[0])) # [50, 4],即去掉第0维,且将xywh(中心点坐标+宽高)变成xyxy(左上角坐标+右下角坐标)。
# 返回张量的形状为[3*grid_h*grid_w, 50]。两组矩形所有框对的iou。
ious.append(fluid.layers.iou_similarity(pred, gt))
# iou形状是[batch_size, 3*grid_h*grid_w, 50],即拼接了ious,所有图片这一层的ious汇合。
iou = fluid.layers.stack(ious, axis=0)
# 3. Get iou_mask by IoU between gt bbox and prediction bbox,
# Get obj_mask by tobj(holds gt_score), calculate objectness loss
# [batch_size, 3*grid_h*grid_w] 只留下了与gt的最大iou
max_iou = fluid.layers.reduce_max(iou, dim=-1)
# [batch_size, 3*grid_h*grid_w] 负样本框
iou_mask = fluid.layers.cast(max_iou <= ignore_thresh, dtype="float32")
if self.match_score:
max_prob = fluid.layers.reduce_max(prob, dim=-1)
iou_mask = iou_mask * fluid.layers.cast(
max_prob <= 0.25, dtype="float32")
# [-1, 255, -1, -1]
output_shape = fluid.layers.shape(output)
an_num = len(anchors) // 2
# [batch_size, 3, grid_h, grid_w]
iou_mask = fluid.layers.reshape(iou_mask, (-1, an_num, output_shape[2],
output_shape[3]))
iou_mask.stop_gradient = True
# NOTE: tobj holds gt_score, obj_mask holds object existence mask
# [batch_size, 3, grid_h, grid_w] 正样本框,正样本处是1,其他位置是0
obj_mask = fluid.layers.cast(tobj > 0., dtype="float32")
obj_mask.stop_gradient = True
# For positive objectness grids, objectness loss should be calculated
# For negative objectness grids, objectness loss is calculated only iou_mask == 1.0
# 正样本框、忽略框、负样本框的loss
loss_obj = fluid.layers.sigmoid_cross_entropy_with_logits(obj, obj_mask)
# 只留下正样本框的loss
loss_obj_pos = fluid.layers.reduce_sum(loss_obj * tobj, dim=[1, 2, 3])
# 只留下负样本框的loss,因为被分配到gt的正样本框中有的可能与gt最高iou不足0.7
loss_obj_neg = fluid.layers.reduce_sum(
loss_obj * (1.0 - obj_mask) * iou_mask, dim=[1, 2, 3])
return loss_obj_pos, loss_obj_neg部分解释已经写在了代码里。我们看看ious,它存放的是所有预测框(比如3*13*13个)和所有gt(这里是50个)两两之间的iou,用的是fluid.layers.iou_similarity(pred, gt)来计算的,返回张量的形状为[3*grid_h*grid_w, 50]。代表着每一个预测框分别和50个gt框的iou。接着我们用fluid.layers.reduce_max(iou, dim=-1)获得一个max_iou张量,即每一个预测框分别和50个gt框的iou中,只留下了最大的iou。“若某预测框和所有gt的iou不大于设定的阈值ignore_thresh=0.7,而且本身不是正样本框的话,那么它就作为负样本框。”。这里我们只留下了最大iou的原因是,只要最大iou小于阈值ignore_thresh,那么就确保了该预测框和所有gt的iou小于阈值ignore_thresh。接着是iou_mask = fluid.layers.cast(max_iou <= ignore_thresh, dtype="float32"),即iou_mask里的元素是1的话表示该位置的预测框和所有gt的iou不大于设定的阈值ignore_thresh,但现在还不能说它就是负样本,因为有可能正样本框和所有gt的iou不大于设定的阈值ignore_thresh,即它有可能本身是正样本。我们后面会进一步确定。obj_mask = fluid.layers.cast(tobj > 0., dtype="float32"),即obj_mask里的元素是1的话表示该位置的预测框是正样本。为什么不直接用tobj表示obj_mask呢?因为如果你用了mixup增强,tobj不会是非0即1,正样本的score是一个0到1之间的数值。loss_obj = fluid.layers.sigmoid_cross_entropy_with_logits(obj, obj_mask),这一步,我们计算了所有框(正样本框、负样本框、忽略样本框)的损失,用obj_mask作为label,即正样本输出的置信度应该接近于1,负样本和忽略样本输出的置信度应该接近于0。不是说不计算忽略样本的损失?别急,这不是我们需要的损失,只是先暂时表达出来,后面我们会取感兴趣的损失出来。loss_obj_pos = fluid.layers.reduce_sum(loss_obj * tobj, dim=[1, 2, 3]),我们把正样本的损失取了出来,因为负样本和忽略样本的tobj处是0,所以loss_obj * tobj起到了过滤掉负样本损失和忽略样本损失的作用。loss_obj_neg = fluid.layers.reduce_sum(loss_obj * (1.0 - obj_mask) * iou_mask, dim=[1, 2, 3]),我们把负样本的损失取了出来,首先(1.0 - obj_mask)某元素是1的话表示的是不是正样本 ,iou_mask某元素是1的话表示的是该位置的预测框和所有gt的iou不大于设定的阈值ignore_thresh,所以loss_obj * (1.0 - obj_mask) * iou_mask起到了过滤掉正样本损失和忽略样本损失的作用。最后,return loss_obj_pos, loss_obj_neg 即置信度损失只计算了正样本的和负样本的。为什么要有“忽略样本”这种机制呢?“忽略样本”框一般是gt框附近的框,或者是gt框所在格子的另外两个框。这种框,若作为负样本进行训练,可能对于正样本的检出率有负面影响,比如你看到了一只狗的大部分,但你不足以作为正样本,总不能说你看到的这一大部分是“背景”,作为负样本训练的话,会影响卷积层的权重,就是说你认为你看到的这一大部分是背景,可能会降低正样本的检出率。而如果作为正样本进行训练的话,可能会是低质量的正样本,因为可能连物体中心点的坐标都预测不准,你还指望预测框能很好地包围物体吗?预测时在nms阶段可能也过滤不掉这些低质量的正样本。所以,索性就不管它们了,置信位爱输出什么输出什么。当然,上述只是笔者的猜想和理解。
希望大家看完这篇笔者写的文章后,能对YOLO算法的损失函数有更深的理解。
最后,笔者打一个广告,欢迎大家来GitHub关注笔者的账号miemie2013,给笔者的仓库点star,笔者复现了很多算法哦,包括YOLOv4,笔者复现的YOLOv4损失函数也和上面所讲解的没有太大出入。
Keras版YOLOv3: https://github.com/miemie2013/Keras-DIOU-YOLOv3
Pytorch版YOLOv3:https://github.com/miemie2013/Pytorch-DIOU-YOLOv3
PaddlePaddle版YOLOv3:https://github.com/miemie2013/Paddle-DIOU-YOLOv3
PaddlePaddle完美复刻版版yolact: https://github.com/miemie2013/PaddlePaddle_yolact
Keras版YOLOv4: https://github.com/miemie2013/Keras-YOLOv4
Paddle版YOLOv4:https://github.com/miemie2013/Paddle-YOLOv4
Keras版SOLO: https://github.com/miemie2013/Keras-SOLO
Paddle版SOLO: https://github.com/miemie2013/Paddle-SOLO
写完这篇文章,小编累得只剩下半口气了,果然写文章真的不比写代码轻松,小编感觉自己还是更喜欢更适合写代码一点。如果你有什么想和小编说的,欢迎在评论区留言和小编互动哦!