Sliding Line Point Regression for Shape Robust Scene Text Detection 论文翻译解读
Sliding Line Point Regression for Shape Robust Scene Text Detection
扭曲形状文字检测
摘要:
传统的文本检测方法主要关注四边形文本。为了检测自然场景中任意形状的文本,本文提出了一种新的方法——滑线点回归(SLPR)。SLPR将文本行边缘的多个点回归,然后利用这些点绘制文本的轮廓。所提出的SLPR可以适用于许多目标检测体系结构,如更快的R-CNN和R-FCN。具体来说,我们首先生成包含区域建议书网络(RPN)的文本的最小矩形框,然后使用垂直和水平滑动线等距地将文本边缘上的点还原。为了充分利用信息,减少冗余,我们用矩形框的位置来计算目标点的x坐标或y坐标,只对剩余的y坐标或x坐标进行回归。这样既可以减小系统的参数,又可以抑制生成更多正多边形的点。我们的方法在传统的ICDAR2015附带场景文本基准和曲线文本检测数据集CTW1500上取得了比较好的效果。
1.介绍
文本检测在我们的日常生活中是很重要的,因为它可以应用于很多领域,如文本的数字化,文本翻译等。之前的一些方法[1][2]在许多基于更快R-CNN[3]或SSD[4]的水平场景文本数据集上都取得了较好的效果。一些方法[5][6][7][8][9][10][11]也试图解决任意性文本检测问题。[9]和[11]首先回归水平矩形,然后回归四边形。[12]的目标是生成一个不规则多边形后回归矩形。上面提到的方法主要是将文本行作为一个四边形,可以完全用四个点来表示。然而,在自然场景中,除了四边形之外,还有许多其他不同形状的文本行。因此,最近的研究[13][14]已经开始探索曲线文本行检测。本文研究了任意方向和曲线文本检测。我们的方法,滑线点回归(SLPR)是基于两步目标检测方法使用更快的R-CNN或RFCN。首先提出了具有生成候选区域网络(RPN)的一些有趣的矩形区域,然后对文本边缘的点进行回归。我们生成一些规则来确定哪些点应该回归,这样就会在点之间有相关性。不同于[13]直接退化固定带注释的x坐标和y坐标点和采用RNN[15],[16]学习他们的相关性,我们介绍一些规则,纵向和横向滑线沿着文本,然后倒退滑线的相交点,如图1中所示的文本行。这样,我们只能对这些点进行x坐标或y坐标的回归,然后以矩形的位置计算其他坐标,从而减少不必要的计算,提高性能。
本文的贡献如下:
1。本文研究了文本行边界上的多个回归点,尝试基于更快的R-CNN和R-FCN来处理任意方向和曲线文本检测。
2。引入滑线法确定回归的真值点,充分利用这些点的相关性生成更规则的多边形。
II. 相关工作
近年来,场景文本的检测与识别越来越受到人们的关注。但由于场景文本定位和背景的复杂性,其检测仍然是一个难题。所有的方法都可以分为三类:基于字符的方法、基于词的方法和基于分割的方法。基于字符的方法通常需要综合数据集,因为在文本行中标记字符需要额外的工作。但是,生成的数据与真实数据存在较大的偏差,无法使经过训练的模型在真实数据集上达到最先进的结果,如流行的ICDAR2015附带场景文本基准。为了解决这一问题,[17]采用半监督的方法对真实数据进行了建模,取得了良好的效果。
基于分割的方法在文本检测中也得到了应用。[18]训练了一个完全卷积网络(FCN)[19],[20]来预测文本区域的显著映射,然后结合显著映射和字符组件来跟踪文本行。[21]添加了border类来将文本与其邻居分离。[10]和[8]生成文本映射,并还原相应四边形的大小和角度,即四个顶点同时的坐标。与传统的分割方法相比,他们在ICDAR2015附带场景文本基准上取得了巨大突破。
目标检测的方法很多,如更快的R-CNN [22], SSD [4], R-FCN[23]和YOLO[24]。[2]不规则1×5卷积过滤器,而不是使用标准的3×3卷积过滤器,使网络更适合长文本检测。[25]使用注意图去除背景噪声。近年来,越来越多的研究者提出了基于快速RCNN或R-FCN的两步法。[11]首先生成轴对齐的边框,然后对文本四边形进行回归。他们在roipool层使用了多尺度的池操作。[9]试图同时分割和检测文本。考虑到文本行的特殊性,[26]附加了不同角度的锚,适用于任意方向的文本行。最近,[14]考虑了多边形情况并标记了一个新的曲线文本数据集。[13]还构建了一个曲线文本数据集CTW1500,他们提出了一个新的结构叫做曲线文本检测器(curve text detector, CTD)来解决曲线文本检测问题。
III. 方法
我们的模型可以应用于任何两步目标检测框架,如更快的R-CNN和R-FCN。系统同时回归了包含文本行在内的最小矩形和文本行边界上某些特定点的坐标。更具体地说,以更快的R-CNN为例,我们首先使用RPN得到一些有趣的区域,然后我们不仅返回矩形的位置,而且返回文本行边缘点的坐标,最后我们可以得到任意形状的文本区域。
介绍
- 文本检测模型类型(一般论文的前两段都会介绍)
基于候选框的目标检测识别模型
2.目前模型存在的问题
存在漏检测
3.本文将会解决的问题
1.本文研究了文本行边界上的多个回归点,尝试基于更快的R-CNN和R-FCN来处理任意方向和曲线文本检测。
2.引入滑线法确定回归的真值点,充分利用这些点的相关性生成更规则的多边形。
一、模型
- 模型的主要创新点(简略的描述)
在文本行上引入了一些规则来对直线进行垂直和水平滑动(我们在实验中使用等距滑动),然后对滑动线和文本行边界的交点进行回归。
A:哪些点应该回归?
显然,如何确定恢复多边形的点集是非常重要的。我们相信规则越简单,神经网络就越容易学习。由于自然景物的形状和角度变化很大,所有形状的固定特征点的顺序都很难确定,所以我们不对多边形上的顶点等不动点进行回归。虽然对于四边形,我们可以通过回归相应的四个顶点来完美的恢复它,但是四个顶点的顺序的确定需要一个复杂的规则,这是神经网络难以学习的。另外,如图2所示,我们在文本行上引入了一些规则来对直线进行垂直和水平滑动(我们在实验中使用等距滑动),然后对滑动线和文本行边界的交点进行回归。另一方面,由于滑移线的约束,不同相交点的坐标之间存在相关性。不需要同时对所有点的x坐标和y坐标进行回归。如果是水平滑动,那么文本边界上的点的x坐标可以通过矩形的坐标来计算,所以我们只需要对这些点的y坐标进行回归。同样,如果是垂直滑动,我们只需要收回这些点的x坐标。该方法不仅降低了网络的计算复杂度,而且将回归点作为先验知识加以约束,防止生成形状怪异的多边形,进一步提高了精度。对于滑动行数,我们观察到该参数对四边形文本行不敏感。但为了很好地恢复其他形状文本行,在平衡了性能和网络复杂度之后,我们决定分别使用7条滑移线进行垂直方向和水平方向的处理。因此,总共产生了14条具有28个交点的直线。
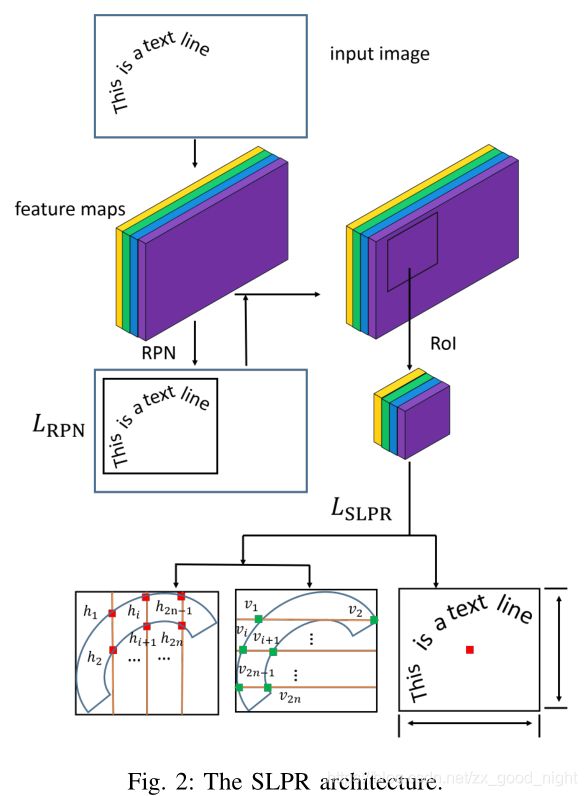
B.多任务学习
为优化神经网络参数,如图2所示,我们采用多任务学习的方法将损失函数L定义为:

其中LRPN为区域提案丢失,LRCLS为区域提案分类丢失,LRB为box回归丢失。LSLPR是RPN后第二步的损失。同样,前两项LCLS和LB分别为分类损失和box回归损失。λRλB和λS相关权重因素,在这项研究中都设置为1。LSLPRB是SLPR提出的新的亏损项目:
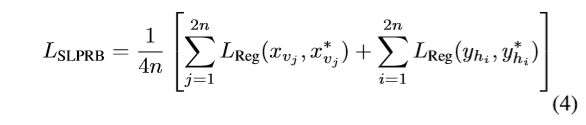
LReg是box regression task的L1平滑损耗:

在Eq.(4)中,n表示在一个方向上的滑动线的数量,我们在实验中设n = 7。通常,每行都有两个与文本行边框相交的点。如果有两个以上的交点,我们取最小的和最大的坐标。xvj为垂直滑移线和文本线边界交点vj的x坐标,yhi为水平滑移线和文本线边界交点hi的y坐标。x和y∗∗vj是神经网络输出相应的点估计。对于水平滑动的直线,我们只对其交点的y坐标进行回归。对于垂直滑移线,我们只对其交点的x坐标进行回归。其他坐标可以通过矩形的坐标恢复:
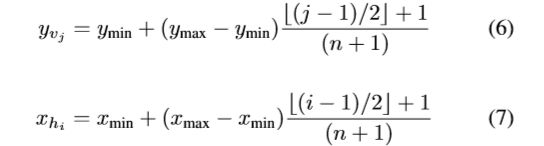
xmin和ymin表示矩形边界的最小x坐标和y坐标,xmax和ymax表示矩形边界的最大x坐标和y坐标。b·顺楼层功能。综上所述,为了回归多边形的坐标,需要考虑32个参数,包括矩形的4个参数和文本线边界上相交点的x、y坐标的28个参数。
C、多边形恢复
通过上述SLPR方法,我们可以从神经网络的输出中得到多个点。为了恢复最终的四边形或多边形,我们采用了以下两种方法进行比较:
1)只使用长边点(PLS):文本线总是延伸到长边,沿着长边滑动的线能更好地反映文本的形状。实际上,我们可以通过扫描长边来恢复多边形,如图3所示。具体来说,我们首先通过回归矩形判断文本行是水平的还是垂直的,然后通过相应方向上的点恢复多边形。以竖直方向为例在图3中,因为我们不回归矩形边界的交点,我们首先扩展边界附近的四行找到四个相交点的矩形,然后连接四个新的点和其他交集点生成多边形。
2)同时使用水平点和垂直点(BHVP):实际上,如果我们同时使用水平点和垂直点来恢复多边形,我们可以使用[27]中的方法粗略地计算经过这些点的多边形或四边形,如图4所示。这样我们就可以在水平方向和垂直方向上得到足够密集的点,而不需要像PLS方法那样计算矩形的交点。然而,我们发现BHVP对于多边形的效果不如PLS。因此,我们只在四边形数据集(ICDAR2015附带场景文本)上使用这种方法。
D. Polygonal non-maximum suppression 多边形非极大值抑制
非极大值抑制(Non-maximum suppression, NMS)是非极大值抑制(Non-maximum suppression, NMS)是目标检测中常用的一种基本方法,其目的是去除重复的方框。传统的NMS方法是基于矩形盒的,这不是其他形状的最佳选择。近年来研究了其他NMS方法,如感知位置的NMS[10]、倾斜的NMS[11]、Mask-NMS[9]和多边形NMS[13]。在本研究中,当我们考虑多边形时,我们在实验中比较了NMS和PNMS。
结果:
1) ICDAR2015附带场景文字:表I显示了不同设置下SLPR系统的结果。首先,对于文本区域的四边形的恢复,BHVP使用所有的点比PLS使用长边点的效果更好。其次,即使我们的目标是检测该数据集中的四边形,PNMS仍然优于NMS。最后,使用多尺度是提高不同目标尺寸检测性能的一种方法。我们还测试了我们的系统在(850,1000)的多尺度结果,得到了大约1%的Hmean度量的绝对改进。图5列出了ICDAR2015附带场景文本数据集上几个具有挑战性的检测结果示例。表2给出了在ICDAR2015附带场景文本上的SLPR与最新结果的比较。可以看出,我们的方法在该数据集上取得了比较好的效果。
2) CTW1500:表3显示了我们的方法在不同NMS设置下的结果。与ICDAR2015附带场景文本的观测结果不同,我们的方法在NMS0.3上取得了最好的结果,即传统的NMS方法以0.3为阈值计算IoU (Intersectionover-Union)。表4列出了我们的方法与CTD和CTD+TLOC相比较的结果。我们从[13]中删除了TLOC作为我们的基础网络,这和CTD是一样的。显然,与CTD方法相比,我们的SLPR方法的Hmean性能可以提高5.3%,证明了我们简单规则设置回归点的有效性。即使与增加了LSTM网络的CTD+TLOC方法相比,SLPR仍能使Hmean性能提高1.4%。图6给出了CTD、CTD+TLOC和SLPR检测结果的几个例子。可以看出,与CTD相比,我们的方法产生了更平滑的区域和更好的检测结果,这意味着所提出的SLPR能够更好地处理任意方向的情况,这是因为采用滑动线的水平对称和垂直对称扫描的新设计。
在本文中,我们提出了一种新的文本检测方法——任意形状的SLPR方法。与CTD+TLOC[13]的文本检测方法相比,SLPR在不使用LSTM的情况下更加简洁,获得了更好的性能。在传统的四边形数据集(ICDAR2015附带场景文本)中,SLPR也实现了最先进的性能。
总结
不做连线的话只能水平方向,连线可以多方向,但可能是扭曲的不规则形状