【读书笔记unix操作系统设计】文件系统的调用
文章目录
- 读完本文你可以了解到什么
- 概述
- 一、读取已经存在的文件
- 1.1系统调用open
- 1.2系统调用read
- 1.3系统调用write
- 1.4文件输入输出位置的调整lseek
- 二、文件的创建
- 2.1文件的建立
- 2.2特殊文件的建立
- 三、更改进程当前目录
- 四、stat和fstat--查询文件状态
- 五、管道--进程间通信
- 5.1无名管道的打开
- 5.2有名管道的打开
- 5.3管道的读和写
- 5.4管道的关闭
- 六、系统调用dup
- 七、文件系统的安装与拆卸
- 7.1文件系统安装
- 7.2跨越安装点来查找文件
- 7.3文件系统的拆卸
- 八、link与unlink
- 8.1link创建硬链接
- 8.2unlink清除一个硬链接
- 九、文件系统的一致性
- 十、文件系统的抽象
- 十一、文件系统的维护
读完本文你可以了解到什么
在文件的内部标识这一章中我们从索引节点和数据块的角度了解了文件创建删除、查询时进行的操作。
在本章中,我们继续讲解文件系统的最后一部分,文件系统的系统调用。这一章内容是基于文件内部标识所提供的的算法,说明创建删除、读取写入文件所需要执行的操作。
在文件的内部标识这一部分讲到的算法都是提供给内核使用的,开发人员无法使用的,但这一章文件系统的系统调用基本都是为开发人员提供的系统调用接口,在unix操作系统中可以利用man命令查到的(man手册第二章为系统API接口,可以用man 2 命令名称查询)。
概述
上一章文件的内部标识讨论了文件系统的内部数据结构和对这些数据结构进行操作的算法。本章用上一章给出的概念,讨论文件系统的系统调用。
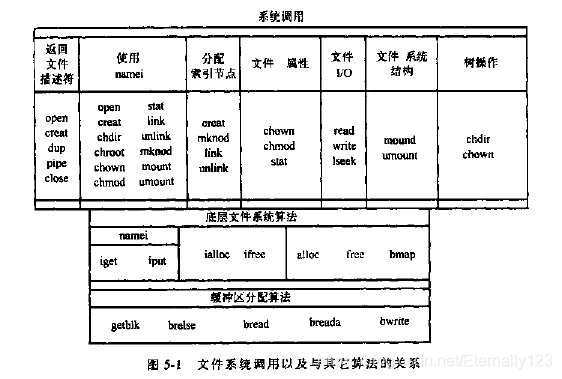
首先讨论存取已经存在的文件系统的系统调用open、read、write、lseek、close;然后介绍创建文件的系统调用create、mkmod;然后给出管理索引节点和文件系统的系统调用chdir、chroot、chroot、chmod、stat、fstat;后面还会探讨更加高级的系统调用pipe和dup,它们对实现shell中的管道是很重要的;系统调用mount和umount扩充了用户可见的文件目录树;link和unlink (硬链接)修改文件系统的层次结构。
下面一张图展示了这些系统调用的关系:(本图适合学完这一章再看)
一、读取已经存在的文件
1.1系统调用open
系统调用open是进程要存取一个文件中的数据必须采取的第一步。其语法格式为:
fd = open(pathname,flags,modes);
//pathname是文件名;
//flags指示打开的类型(如读或写);
//modes给出文件的许可权(如果文件正在被建立)??????
//系统调用open返回一个称为文件描述符的整数。进程用文件描述符操作文件
系统调用open的算法描述如下:(其实在第一步用namei算法找到索引节点后,还需要用iget算法加载索引节点,这个操作包含索引节点表引用数的变化)

上述算法中涉及的用户文件描述符表和文件表以及索引节点表如下图所示:
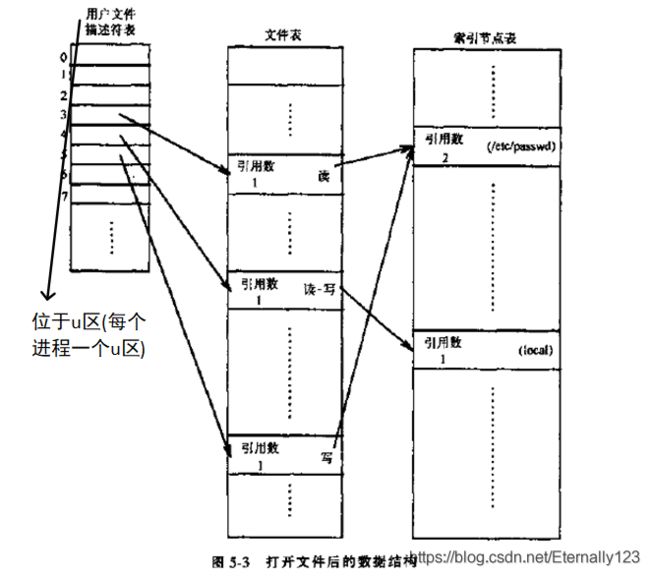
用户文件描述符表前三个描述符(0、1和2)分别叫做标准输入、标准输出和标准错误文件描述符。
需要注意的是:每个open调用都导致用户描述附表和内核文件表中分配一个唯一的表项,但在内核的索引节点表中,每个文件只对应一个表项。看到这里,你可以会有疑问,既然是这样,那文件表中的引用数不就永远是1吗,还需要这一项么?答案是肯定的。引用数不为1的例子会在后面的dup函数和进程管理的fork函数中提到。
1.2系统调用read
在用open打开文件后,就可以对文件进行读写操作了。本节讲述读操作。其语法格式为
number = read(fd,buffer,count);
//fd是由open返回的文件描述符
//buffer是用户进程中的一个数据结构的地址
//count是用户要读的字节数
//返回值number是实际读到的字符数
在考虑读文件算法前,先考虑这样一个问题:read函数提供了读取几个字节的参数,但内核如何知道该从文件的哪个位置开始读呢?换句话说,内核应该将当前读取文件的文件指针偏移量存放在哪个数据结构中呢?应该放在文件表中(肯定不能放索引节点,因为多个文件都可以指向同一个索引节点,但为什么不能放在用户文件描述符表中?)
下面是read调用的算法:

看完read算法后,给我们编程能够带来一些深层次的理解:文件系统读取文件一般都是从边界开始读取的,这种情况下,大小为块的整数倍的IO操作就具有很多优点,能够使内核避免额外的重复算法read中的循环,提高效率。
1.3系统调用write
系统调用write的语法格式为:
number = wirite(fd,buffer,count);
//write和read的参数意义几乎一样,这里不过多赘述
和读取操作不同的是,写操作可能带来磁盘块的扩张。这里就要用到alloc分配一个新的块并将其放在索引节点正确的位置上。同时,写结束后,如果文件变大了,内核将修改索引节点中表示文件大小的字段。
像read算法一样,内核在每次内层循环期间向磁盘写一块,每次循环期间,内核决定写一部分还是写整块。如果写整块,则内核不必读取磁盘数据,因为一定会被覆盖。如果写一部分,内核则需要读取磁盘数据进行修改。
写操作还用到了延迟写,在写入完成后,万一其他进程又用到了这块磁盘块,可以直接从高速缓冲区取,提高效率。
1.4文件输入输出位置的调整lseek
系统调用read和write实现了顺序访问文件。但是进程可能需要lseek指定IO的位置。
position = lseek(fd,offset,reference);
//将文件指针放到reference的offset位置上
在系统调用时,内核只需要调整文件表中的字节偏移量。
二、文件的创建
2.1文件的建立
系统调用create在系统中创建一个新的文件
fd = create(pathname,modes);
//以上参数和open中参数含义一样,不赘述
如果以前不存在这个文件,则创建;如果已经存在,则清空该文件(释放所有存在数据库并将文件大小置0)
以下是文件建立算法:

2.2特殊文件的建立
系统调用mknod用来在文件系统中建立一些特殊文件,包括名管道、设备文件和目录。该调用与create相似之处是,内核分配一个索引节点。
mknod(pathname,type and permissions,dev);
//type和permissions给出节点的类型(如目录)和要被建立的文件的访问许可权
//dev为特殊文件和字符特殊文件规定主设备号和次设备号
算法如下:(第一条if语句的含义)

三、更改进程当前目录
系统初启动时,进程0在初始化期间使文件系统的根称为他的当前目录。当系统调用fork建立一个新的进程时,新进程集成老进程在u区的当前目录,内核将该节点的引用数加1。
chdir(pathname);

四、stat和fstat–查询文件状态
stat和fstat允许进程查询文件的状态,它们返回文件类型、文件所有者、大小、联结的数目(硬链接)、索引节点号等信息。两者的区别
stat(pathname,statbuffer);
fstat(fd,statbuffer);
//statbuffer存放返回信息
五、管道–进程间通信
管道允许在进程之间按先进先出的方式传送数据,管道也能使进程同步执行。
管道的实现使进程之间能够通信,尽管它们不知道管道的另一端是什么进程。
管道的传统实现方法是采用文件系统做数据存储。有两种类型的管道:有名管道和无名管道。进程对有名管道使用系统调用open,但使用系统调用pipe来建立无名管道。这两种方式除了进程最初存取它们的方式不同以外,两个管道是一样的。
对无名管道:只有相关的进程:即发出pipe调用的进程及其后代,才能共享对无名管道的存取。

对有名管道:所有进程都能按照通常的文件许可权存取有名管道。
5.1无名管道的打开
pipe(fdptr);
//fdptr是指向一个整形数组的指针。这个数组将含有读写管道用的两个文件描述符。
pipe系统调用时内核要做什么:
- 为管道分配索引节点及数据块(在管道设备中–管道设备就是一个文件系统),用于索引文件及存放数据。
- 为管道分配一对用户文件描述符及相应的文件表项:一个用于读,一个用于写。
具体算法如下:

5.2有名管道的打开
一个有名管道是一个文件,但这个文件有目录项并可以通过路径来存取。进程以与打开正规文件相同的方式打开有名管道。因此,关系不密切的进程也可以进行通信。
有名管道在文件系统树中永久得存在,而无名管道是临时性的:当所有进程都结束使用某个管道时,内核便收回它的索引节点。
打开一个有名管道的算法和打开一个正规文件的算法基本相同。然而,在完成系统调用前,内核增加索引节点中的度计数和写计数,它表示为了读或写而打开管道的进程数。
为了读而打开的有名管道的进程将进入睡眠,知道另一个进程以写的方式打开管道,反之亦然。
5.3管道的读和写
应该把管道看做好像是某些进程写入该管道的一段,而另外一些进程从另一端读该管道。进程以先进先出的方式从管道中存取数据。
管道中的读进程数目不一定和写进程数目一样。如果读或写的进程数目大于1,则这些进程必须以其它机制协调对管道的使用。
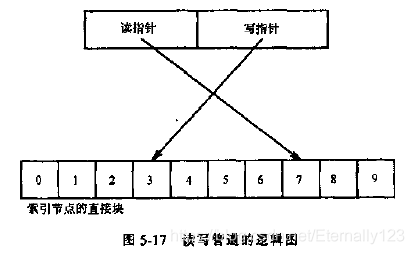
内核将索引节点的直接块作为一个循环队列来管理,内部的修改读写指针,从而保持先进先出的顺序。
下面考虑四种读写管道的情况:
- 写管道:管道中尚有空间存放欲写的数据
- 读管道:管道中有足够的数据满足读操作
- 读管道:管道中没有足够的数据满足读操作
- 写管道:管道中没有足够空间存放要写数据
对于第一种:内核采用与正规文件读写一样的算法那。每次write之后,内核自动的增加管道的大小。(这一点与一般读写文件不同,一般情况下是当在文件尾部追加数据时,才增加文件大小);对于第二种:每读一块后,减少管道的大小,如果有必要的话,调整u区的偏移值,使其绕回管道的开始;对于第三种:read将返回管道中当前所有的数据,成功的技术,及时没有满足用户需求,如果管道为空,进程进入睡眠,知道另一个进程写入;对于第四种:内核将该做引接点标记,进程进入睡眠,等待数据从管道排出。当有进程读时,内核唤醒写进程,然后将尽可能多的数据写入,在进入睡眠(如果有必要的话),循环往复。
5.4管道的关闭
关闭管道和关闭文件过程一样,只不过内核在释放管道的索引节点之前要做一些特殊处理:
- 如果写进程数目降为0,内核唤醒所有读进程,让他们从读调用中空手返回,不读任何数据。
- 如果读进程数目降为0,内像等待该管道的所有谢金成发送一个软中断,指出一个错误情况(第七章)。
总的来说,如果一个进程在等待读一个无名管道,并且不再有写进程,那么用于不会再有写进程了,需要将读进程唤醒(接触阻塞状态)。
六、系统调用dup
系统调用dup将一个文件描述符拷贝到该用户文件描述符表中,给用户返回一个新的文件描述符。
newfd = dup(fd);
因为dup复制了文件描述符,所以它使得对应的文件表象的引用值加1。
在构建复杂程序时,dup起着重要的作用,例如在构造shell管道线时(第七章)
复制文件描述符后,两个文件描述符使用了一个文件偏移量(文件偏移量位于文件表中)。这有什么用?
七、文件系统的安装与拆卸
一个物理磁盘设备是由一些被磁盘驱动程序划分的逻辑段组成的,每个逻辑段都有一个设备文件名。磁盘的一个段可以含有一个逻辑的文件系统,由之前所述的引导块、超级块、索引节点表和数据块组成。
系统调用mount将在一个磁盘的指定段中的文件系统连接到一个已经存在的文件系统目录树中,系统调用umount将一个文件系统从该文件系统目录树中拆卸下来。
7.1文件系统安装
mount(special pathname,directory pathname,options);
首先要了解安装表(位于内核中),每个被安装的文件系统在该文件表中都占有一个表项。每个安装表项含有如下字段:
- 设备号:用来标识被安装的文件系统
- 指向含有被安装文件系统超级块的缓冲区的指针
- 指向被安装文件系统的根索引节点的指针
- 指向安装点的目录的索引节点
下面给出安装文件系统的算法:

安装点目录的索引节点的引用数不能超过1?
7.2跨越安装点来查找文件
这一小节将讨论查找路径时,路径名中跨越安装点的情况。
算法如下:

7.3文件系统的拆卸
umount(special filename);
在拆卸一个文件系统时,内核取要拆卸的设备的索引节点号,查找特殊文件的设备号,释放对应索引节点。并在安装表中找到设备号等于该特殊文件的设备号的表项。同时注意,拆卸之前,内核会检查如果该文件系统中有活动的文件,拆卸失败。
算法如下:

八、link与unlink
8.1link创建硬链接
系统调用link创建一个硬链接(将文件系统中给一个文件联结关联到另一个新文件名上)
link(source file name,target file name);
//source file name是已经存在的文件名,target file name是新的文件名
对目录进行链接只允许超级用户进行操作。
link算法如下:

8.2unlink清除一个硬链接
unlink(pathname);
如果被拆除的文件是该文件的最后一个联结,那么,内核最终将释放它的数据块。但是,如果该文件中有多个联结,通过它的其他名字,仍能修改文件。
算法如下:

九、文件系统的一致性
四种情况