【莫烦强化学习】视频笔记(四)2.DQN实现走迷宫
第11节 DQN实现走迷宫——《强化学习笔记》
上一节已经详细介绍了DQN的两大利器:REPLAY BUFFER(经验回放机制)和冻结Q-target(目标网络,两个网络中用来估计真实Q值的网络),这里给出DQN的伪代码,方便后面的编程实现。
11.1 主循环
DQN伪代码如下:

主循环的主要代码就是上面的更新过程,其它诸如DQN类等代码后续补充。主循环要注意的是,这里的两个网络和REPLAY BUFFER的用处,都是为了切断马尔可夫序列元素之间的关联性。
对于网络的编写、网络参数更新主函数都不做考虑,中间存储到REPLAY BUFFER之后的内容属于学习Q网络的内容,都在DQN类的learn函数中。
这里还添加了神经网络误差虚线的绘制函数,可以的话,也可以修改代码,输出两个网络的全部LOSS变化情况。
from maze_env import Maze
from DQN import DeepQNetwork
def run_maze():
step = 0 # 记录步数,用来提示学习的时间
for episode in range(300):
# 初始化环境
observation = env.reset()
while True:
env.render() # 渲染一帧环境画面
action = RL.choose_action(observation) # DQN根据当前状态s选择行为a
observation_, reward, done = env.step(action) # 与环境进行交互,获得下一状态s'、奖励R和是否到达终态
RL.store_transition(observation, action, reward, observation_) # 将当前的采样序列存储到RF中(s, a, R, s')
# 200步之后开始学习,每隔5步学习一次,更新Q网络参数(第一个网络)
if (step > 200) and (step % 5 == 0):
RL.learn()
observation = observation_ # 转移至下一状态
if done: # 如果终止, 就跳出循环
break
step += 1 # 总步数 + 1
# 游戏结束
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze() # 创建环境
RL = DeepQNetwork(env.n_actions, env.n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200, # 每 200 步替换一次 target_net 的参数
memory_size=2000, # 记忆上限
# output_graph=True # 是否输出 tensorboard 文件
)
env.after(100, run_maze)
env.mainloop()
RL.plot_cost() # 神经网络的误差曲线
11.2 DeepQNetwork类
DQN与Q学习和SARSA有很大不同,主类的代码包含参数初始化、创建网络、存储记忆、选择动作、学习和绘制学习曲线这几个模块。
参数初始化
具体参数含义在代码注释中。
import tensorflow as tf
import numpy as np
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=48,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions # 动作空间,有几个动作
self.n_features = n_features # 特征的维度,比如迷宫是在迷宫中的位置(length, height),图像的话有可能是(m*n)大小的图片
self.lr = learning_rate # 学习率,参数更新效率
self.gamma = reward_decay # 奖励衰减因子
self.epsilon_max = e_greedy # epsilon-greedy的参数,数越大随机性越小
self.replace_target_iter = replace_target_iter # 每隔多少步更新目标网络(第二个网络)
self.memory_size = memory_size # 记忆上限
self.batch_size = batch_size # 每次更新从buffer中取出的记忆数目
self.epsilon_increment = e_greedy_increment # epsilon的值随着时间增加,即随机性减小,探索模式参数
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max # 是否开启探索模式,
# 并逐步减少探索次数,epsilon为0证明一开始完全随机
self.learn_step_counter = 0 # 记录学习步数,为了更新目标网络参数
# 初始化全 0 记忆 [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2)) # *2的意思是观测值(状态)是二维的(坐标)
self._build_net() # 创建Q网络和目标网络
# 替换 target net 的参数
t_params = tf.get_collection('target_net_params') # 提取目标网络的参数
e_params = tf.get_collection('eval_net_params') # 提取Q网络的参数
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] # 更新目标网络参数
self.sess = tf.Session()
# 输出日志文件
if output_graph:
# $ tensorboard --logdir=logs 命令行的输入方式,查看tensor board命令
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer()) # 初始化全局参数
self.cost_his = [] # 记录所有loss, 最后画图用
注意上面的Q网络指的是采样和从buffer取出记忆时生成Q值的网络(简称网络一),目标网络指的是学习更新中用来估计真实Q值,更新速度慢于前者的网络(简称网络二),两个网络 结构完全相同 ,但是第二个网络的参数更新步长更大(每隔一定时间将网络一参数赋给网络二)。
创建网络
网络创建这部分代码有一些难度,需要用到tensor flow,这里只有简单的说明和代码,其它部分不做详细解释。网络的具体结构可以在tensor board中查看,tensorboard使用方法:Tensorboard使用详解
具体关于网络结构与Tensorboard可视化的结果请向下看文章。
def _build_net(self):
# ------------------ 创建Q网络 ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # 输入状态s
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # 用来存放目标Q值
with tf.variable_scope('eval_net'):
# c_names:存储参数的集合
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # 参数初始化器
# 第一层,线性多项式,参数再复制给目标网络时使用
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# 第二层
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ 构建目标网络,和Q网络完全相同------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # 输入
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# 第一层
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# 第二层
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
存储记忆
这里REPLAY BUFFER的大小是固定不变的,上面的变量memory_size就是buffer的大小,索引循环指向每一行,新的记忆会覆盖本行旧的记忆。
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'): # 查看变量是否存在
self.memory_counter = 0 # 记录总的记忆数量
# 记录一条 [s, a, r, s_] 记录
transition = np.hstack((s, [a, r], s_)) # 变为水平向量
# 总 memory 大小是固定的, 如果超出总大小, 旧 memory 就被新 memory 替换
index = self.memory_counter % self.memory_size # 类似于循环数组,取余使其循环放置,覆盖之前的内容
self.memory[index, :] = transition # 放置记忆
self.memory_counter += 1 # 记忆条数+1
动作选择
这里首先输入Q网络得到所有动作的Q值,根据 ϵ \epsilon ϵ-Greedy选择动作索引输出即可。
def choose_action(self, observation):
# 在observation前添加一个维度(1, size_of_observation),为了便于tensor flow处理
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon: # epsilon的概率贪婪选择
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation}) # 输入状态,输出所有动作对应的Q值
action = np.argmax(actions_value) # 选择最大的动作
else:
action = np.random.randint(0, self.n_actions) # 随机选择
return action
学习
这里是关键代码,对应上面的伪代码流程。
- 首先通过 ϵ \epsilon ϵ-Greedy获得动作a,与环境交互得到奖励R和下一状态s’。将本次经验序列 ( s , a , R , s ′ , e n d ? ) (s,a,R,s',end?) (s,a,R,s′,end?)放入buffer中,其中 e n d ? end? end?表示是否为终态。
- 更新网络时,从buffer取出一批经验序列,先将其 s ′ s' s′输入到Q网络得到预测的动作Q值对应的最大动作,即为代码中的 m a x a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) max_{a'}\hat{Q}(\phi_{j+1},a';\theta^-) maxa′Q^(ϕj+1,a′;θ−)。再乘以 γ \gamma γ(衰减系数)加上r(奖励)得到估计的 真实值。
- 再将相应的状态 s s s和动作 a a a输入到Q网络中得到 估计值。
- 真实值和 估计值做差得到LOSS,使用LOSS进行梯度下降法更新Q网络参数
- 每隔一定步数更新目标网络
def learn(self):
# 到达一定步数将Q网络的参数复制到目标网络
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# 从 buffer(memory)中随机抽取 batch_size 大小的记忆
if self.memory_counter > self.memory_size: # 超过buffer大小选择范围就是buffer的大小
sample_index = np.random.choice(self.memory_size, size=self.batch_size) # 否则就是已有记忆条数的大小,避免把空的记忆抽取到
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :] # 取到一批记忆用于更新网络
# 获取 q_next (目标网络产生) 和 q_eval(Q网络产生)
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:],
self.s: batch_memory[:, :self.n_features]
})
# 下面这几步十分重要. q_next, q_eval 包含所有 action 的值,
# 而我们需要的只是已经选择好的 action 的值, 其他的并不需要.
# 所以我们将其他的 action 值全变成 0, 将用到的 action 误差值 反向传递回去, 作为更新凭据.
# 这是我们最终要达到的样子, 比如 q_target - q_eval = [1, 0, 0] - [-1, 0, 0] = [2, 0, 0]
# q_eval = [-1, 0, 0] 表示这一个记忆中有我选用过 action 0, 而 action 0 带来的 Q(s, a0) = -1, 所以其他的 Q(s, a1) = Q(s, a2) = 0.
# q_target = [1, 0, 0] 表示这个记忆中的 r+gamma*maxQ(s_) = 1, 而且不管在 s_ 上我们取了哪个 action,
# 我们都需要对应上 q_eval 中的 action 位置, 所以就将 1 放在了 action 0 的位置.
# 下面也是为了达到上面说的目的, 不过为了更方面让程序运算, 达到目的的过程有点不同.
# 是将 q_eval 全部赋值给 q_target, 这时 q_target-q_eval 全为 0,
# 不过 我们再根据 batch_memory 当中的 action 这个 column 来给 q_target 中的对应的 memory-action 位置来修改赋值.
# 使新的赋值为 reward + gamma * maxQ(s_), 这样 q_target-q_eval 就可以变成我们所需的样子.
# 具体在下面还有一个举例说明.
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
"""
假如在这个 batch 中, 我们有2个提取的记忆, 根据每个记忆可以生产3个 action 的值:
q_eval =
[[1, 2, 3],
[4, 5, 6]]
q_target = q_eval =
[[1, 2, 3],
[4, 5, 6]]
然后根据 memory 当中的具体 action 位置来修改 q_target 对应 action 上的值:
比如在:
记忆 0 的 q_target 计算值是 -1, 而且我用了 action 0;
记忆 1 的 q_target 计算值是 -2, 而且我用了 action 2:
q_target =
[[-1, 2, 3],
[4, 5, -2]]
所以 (q_target - q_eval) 就变成了:
[[(-1)-(1), 0, 0],
[0, 0, (-2)-(6)]]
最后我们将这个 (q_target - q_eval) 当成误差, 反向传递会神经网络.
所有为 0 的 action 值是当时没有选择的 action, 之前有选择的 action 才有不为0的值.
我们只反向传递之前选择的 action 的值,
"""
# 训练 eval_net
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost) # 记录 cost 误差
# 逐渐增加 epsilon, 降低行为的随机性
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
绘制学习曲线
def plot_cost(self): # 可视化学习结果
import matplotlib.pyplot as plt # 用到了 pyplot可视化库
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
11.3 运行效果与tensorboard
具有NVIDIA显卡的话可以使用显卡运行代码,速度会快很多,具体方法请自行查找百度。下面是运行界面效果:
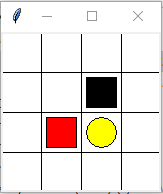
如果使用的是PYCHARM,那么可以点击下方控制台的terminal,调出终端,输入tensorboard --logdir logs,显示以下内容:
(base) F:\强化学习\DQN>tensorboard --logdir logs
TensorBoard 1.14.0 at http://电脑信息号(这里不方便给出):6006/ (Press CTRL+C to quit)
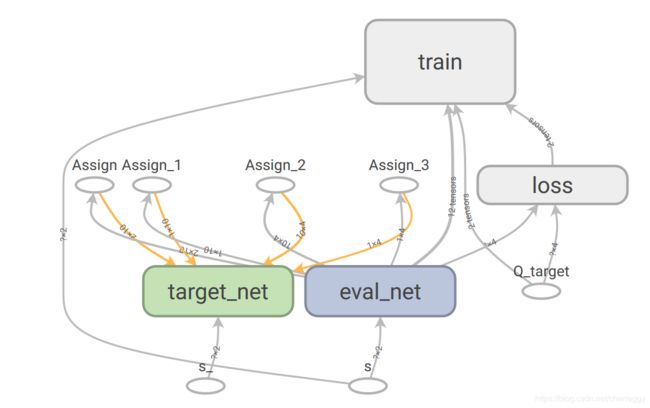
打开任意浏览器,地址栏输入localhost:6006,访问即可看到tensorboard界面显示的网络结构图:
 LOSS变化如下:
LOSS变化如下:

11.4 关于双网络与Replay Buffer的理解
从上面的网络结构图可以很清晰的看出以下几点:
- Q网络(eval_net)输入状态s,目标网络(target_net)输入状态s’,两者输出得到LOSS
- Q网络会将其参数值传递给目标网络
- 只有Q网络在进行参数更新
而Replay Buffer的存在,之前也介绍过目的是减弱时间序列之间的相关性,我绘制了一幅图片来表现Replay Buffer的作用以及过程:
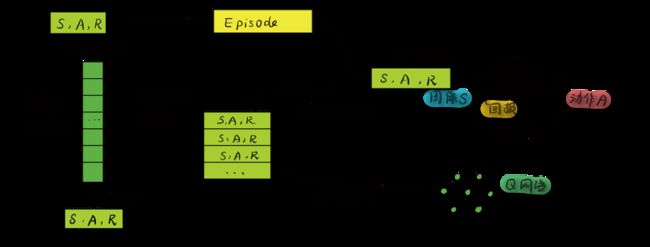
实际上代码中固定大小的存储空间可以当作循环队列使用,效果就是让新的记忆覆盖旧的的记忆。那么成批的记忆是如何同时进行更新的呢?维度的变化是如何的?
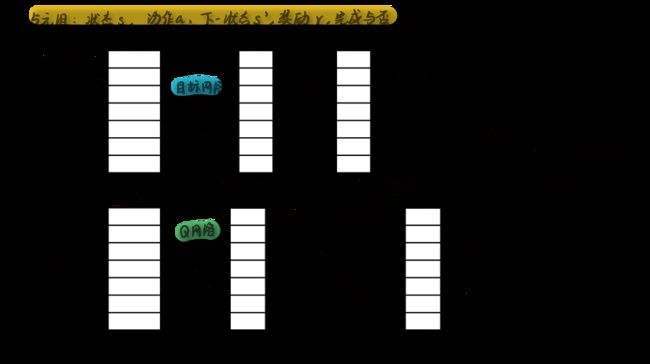
这里我也绘制了一幅图像来展示其过程中维度的变化(但是这个图中对应的不是迷宫的例子,是之前写过的Atari游戏的例子,输入的是图像,当然网络结构也不同):
当然,还有很多值得探索的地方,比如说网络的结构(但是网络结构是在是很复杂,范围很广泛)、batch_size和replay buffer的大小对运行结果的影响等,都可以在代码中尝试。也可以尝试其他环境,在OpenAI Gym中有很多环境,具体使用方法详见:OpenAI gym 环境库
上一篇:【莫烦强化学习】视频笔记(四)1.什么是DQN?
下一篇:【莫烦强化学习】视频笔记(五)1.什么是策略梯度?