CVPR 2020 Oral | 妙笔生花新境界,语义级别多模态图像生成

GAN已经成为图像生成的有力工具,现今GAN已经不再局限于生成以假乱真的图,而是向着更加灵活可操控的方向发展。
今天向大家介绍的CVPR 2020 的文章出自华中科技大学白翔老师组,特别要提醒,文中有视频,相信看过之后你一定会被它的魅力所吸引!

简介
本文所关注的基本任务是使用分割图生成自然图像。同一个分割图可能对应于多张不同的自然图像。
输入一张分割图从而能够产生各种不同的结果是一个非常有挑战性的研究方向,之前的方法主要结合vae(variational auto-encoder)去操控浅层变量,或者在训练的时候加入噪声,测试的时候通过改变噪声去产生不同的结果,但是这些方法都只能对图像进行全局的控制,即噪声一旦发生变化,整张图也会跟着变化。
假设通过一个模型生成的图像效果不错,但是你对其中的某一类不满意,想进行改变,那么之前的方法将无能为力。
因此,本文集中精力在语义级别上对图像进行控制,从而生成只在相同的语义区域上有所变化的不同自然图像,而不改变其它类别的区域。该文把该任务称之为语义级别多模态图像生成(Semantically Multi-modal Image Synthesis,简称SMIS)。
这个任务要求模型能够支持更彻底的用户控制,如果能集合在一些工具和软件之中,甚至可以为设计师和艺术家提供更多的便利。
针对SMIS,可能的方法是对不同的类使用单独的Generator,最后再用一个融合模型将不同类的生成结果合并为一张图像。
这种方法不仅生成效果较差,而且当类别数很大的时候(比如ADE20K有150类),为了保证每一类都能充足训练,会造成极高的算力和显存消耗。
因此本文提出了一种GroupDNet的网络架构,其核心思想是在Decoder中采用组数逐渐递减的分组卷积。
因为组数递减,从而能够大量降低算力和显存消耗,而且,由于很多类别具有互补性,将各个类逐渐地进行融合,从而可以最大限度地利用这种互补去提高图像的生成质量。

图一:本文的方法在SMIS任务上面的展示
可以看到,如图一所示,本文的方法能够较好的完成SMIS任务。同时本文还针对这个任务,提出了两个评价指标,分别是mCSD(mean Class-Specific Diversity)和mOCD(mean Other-Classes Diversity)。
一个能够很好地完成SMIS任务的模型应该具有较高的mCSD和较低的mOCD。
此外,本文的方法还可以实现各种各样的有趣的应用,比如对生成的人像(自然场景)指定类别进行更改,还可以将生成的样式迁移到其他图像,有一个很炫酷的视频展示(全屏看视频,内容更精彩):
模型框架
本文的模型框架如图二所示,整个网络包含一个Encoder,一个Decoder,一个Discriminator(图中未画出),Encoder采用组数等于类别数的分组卷积,由 6个卷积模块堆叠而成,输入的时候,通过分割标签将图像按类别进行分离,找到其中该类别的区域缩放到原图大小,然后将不同类别的图像concat输入到Encoder中,这样是为了得到不同类别的lantent code。
具体来说,Encoder编码得到两个特征图,通过reparameterization trick得到一个feature map,其中不同的通道表示不同类别的编码,这个就是生成过程中不同类别的控制器,如图二中Latent code Z。Decoder采用组数逐渐递减的分组卷积。

图二:模型架构图,其中GConv代表分组卷积
整个Decoder网络由多个CG-Block堆叠而成,每个CG-Block主要包含三个CG-Norm,对于每一个CG-Norm,首先将分割标签缩放为该层特征图的大小,然后使用分组卷积得到和特征图,将两者作为系数对输入的特征图进行变换。

基于这个Decoder的网络架构,在大部分数据集上取得了最好的图像生成质量。相当于开始对每个类别都有自己的生成器,然后将不同的类别逐渐进行融合,这样可以让网络逐渐学习融合的过程,这比使用多个Generator加几个卷积的融合方式效果要好。
并且因为将把编码进行分离,而且Decoder 的每个类别在其他类别的感受也比全都使用普通卷积的网络结构要小,因此在生成过程中对其他类别的生成效果影响也较小,这样能够实现SMIS任务。
Discriminator的结构和Encoder类似,采用了多尺度的Discriminator。
损失函数如下所示:
![]()
采用的是Hinge版本的GAN损失。
LFM是Feature Mapping损失,即计算真实图像和生成图像在Discriminator中的特征图的L1距离。
LP是perceptual损失,即使用一个预训练的VGG网络提取真实图像和生成图像的特征,计算两个特征图的L1距离。
LKL是KL散度损失,公式如下,其中N(0,1)代表高斯分布。
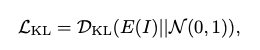
实验
本文在DeepFashion,Cityscapes和ADE20K数据集上进行了实验,图三展示了图像生成质量的对比。

图三:不同数据集的生成效果对比
在SMIS任务上,本文提出了新的评价指标mCSD(mean Class-Specific Diversity)和mOCD(mean Other-Classes Diversity),该指标基于LPIPS(用于衡量生成图像的多样性),mCSD和mOCD计算公式如下,
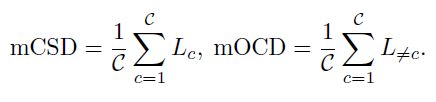
其中表示类别c的LPIPS,表示除了类别c外的LPIPS。这两个指标表示了该变化区域的多样性和不该变化区域的多样性。在SMIS任务上mCSD越大越好,而mOCD则越小越好。
应用
本文的方法具有多种应用,如图四(a)中所示,能够控制只改变生成图像的衣服(或者裤子),(b)展示了将不同类别的不同编码可以一起使用,实现对各个类别的指定生成。
(c)展示了更改分割标签得到新的图像,(d)展示了在编码之间进行插值,实现一种样式到另一种样式的逐渐变化。
 图四:本文的方法的一些应用
图四:本文的方法的一些应用
结论
本文提出了一种语义上控制图像生成(SMIS)的任务,并且提出了GroupDNet的网络架构,在多个数据集取得了最好的图像生成质量,并且较好的完成了SMIS任务。利用该方法可以实现多种应用。
论文地址:
https://arxiv.org/abs/2003.12697
在我爱计算机视觉后台回复“SMIS”,即可收到论文下载。
代码地址:
https://github.com/Seanseattle/SMIS(即将开源)
项目主页:
https://seanseattle.github.io/SMIS/
参考文献
1. Shuyang Gu, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen, and Lu Yuan. Mask-guided portrait editing with con- ditional gans. In Proc. CVPR, pages 3436–3445, 2019.
2. Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive nor- malization. In Proc. CVPR, pages 2337–2346, 2019.
3. Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proc. ECCV, pages 694–711, 2016.
4. Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Dar- rell, Alexei A. Efros, Oliver Wang, and Eli Shechtman. Toward multimodal image-to-image translation. In Proc. NeurIPS, pages 465–476, 2017.
5. Dingdong Yang, Seunghoon Hong, Yunseok Jang, Tianchen Zhao, and Honglak Lee. Diversity-sensitive conditional gen- erative adversarial networks. In Proc. ICLR, 2019.
END

备注:GAN

GAN交流群
关注最新最前沿的图像生成、对抗网络技术,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号 : aicvml
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 