不使用数学函数开方运算的情况下,求解开方运算
1 二分法
浮点开方也就是给定一个浮点数x,求![]() 。这个简单的问题有很多解,我们从最简单最容易想到的二分开始讲起。利用二分进行开平方的思想很简单,就是假定中值为最终解。假定下限为0,上限为x,然后求中值;然后比较中值的平方和x的大小,并根据大小修改下限或者上限;重新计算中值,开始新的循环,直到前后两次中值的距离小于给定的精度为止。需要注意的一点是,如果x小于1,我们需要将上限置为1,原因你懂的。代码如下:
。这个简单的问题有很多解,我们从最简单最容易想到的二分开始讲起。利用二分进行开平方的思想很简单,就是假定中值为最终解。假定下限为0,上限为x,然后求中值;然后比较中值的平方和x的大小,并根据大小修改下限或者上限;重新计算中值,开始新的循环,直到前后两次中值的距离小于给定的精度为止。需要注意的一点是,如果x小于1,我们需要将上限置为1,原因你懂的。代码如下:
float SqrtByBisection(float n)
{
float low,up,mid,last;
low=0,up=(n<1?1:n);
mid=(low+up)/2;
do
{
if(mid*mid>n)
up=mid;
else
low=mid;
last=mid;
mid=(up+low)/2;
}while(fabsf(mid-last) > eps);
return mid;
}
2 牛顿迭代法
原理也比较简单,就是将中值替换为切线方程的零根作为最终解。原理可以利用下图解释(frommatrix67):

图一 牛顿迭代法求开方
假设现在要求![]() 的值(图中a=2),我们将其等价转化为求函数
的值(图中a=2),我们将其等价转化为求函数![]() 与x轴大于0的交点。为了获得该交点的值,我们先假设一个初始值,在图一中为
与x轴大于0的交点。为了获得该交点的值,我们先假设一个初始值,在图一中为![]() 。过
。过![]() 的直线与
的直线与![]() 交于一点
交于一点") ,过该点做切线交x轴于
,过该点做切线交x轴于![]() ,则
,则![]() 是比
是比 好的一个结果。重复上述步骤,过
好的一个结果。重复上述步骤,过![]() 直线与
直线与![]() 交于一点
交于一点![]() ,过该点做切线交x轴于
,过该点做切线交x轴于![]() ,则
,则![]() 是比
是比![]() 更好的一个结果……
更好的一个结果……
很明显可以看出该方法斜着逼近目标值,收敛速度应该快于二分法。但是如何由获得![]() 呢,我们需要获得一个递推公式。看图中的阴影三角形,竖边的长度为
呢,我们需要获得一个递推公式。看图中的阴影三角形,竖边的长度为![]() ,如果我们能求得横边的长度l,则很容易得到
,如果我们能求得横边的长度l,则很容易得到![]() 。因为三角形的斜边其实是过的切线,所以我们可以很容易知道该切线的斜率为
。因为三角形的斜边其实是过的切线,所以我们可以很容易知道该切线的斜率为![]() ,然后利用正切的定义就可以获得l的长度为
,然后利用正切的定义就可以获得l的长度为![]() ,由此我们得到递推公式为:
,由此我们得到递推公式为:
![]()
后面我们需要做的就是利用上面的公式去迭代,直到达到精度要求,代码如下:
float SqrtByNewton(float x)
{
float val=x;//初始值
float last;
do
{
last = val;
val =(val + x/val) / 2;
}while(fabsf(val-last) > eps);
return val;
}
上述代码进行测试,结果确实比二分法快,对前300万的所有整数进行开方的时间分别为1600毫秒和1000毫秒,快的原因主要是迭代次数比二分法更少。虽然牛顿迭代更快,但是还有进一步优化的余地:首先牛顿迭代的代码中有两次除法,而二分法中只有一次,通常除法要比乘法慢个几倍,因而会导致单次迭代速度的下降,如果能消除除法,速度还能提高不少,后面会介绍没有除法的算法;其次我们选择原始值作为初始估值,这其实不是一个好的估计,这就导致需要迭代多次才能达到精度要求。当然二分法也存在这个问题,但是上下限不容易估计,只能采用最保守的方式。而牛顿迭代则可以任意选择初始值,所以就存在选择的问题。
我们分析一下为什么牛顿迭代法可以任意选择初值(当然必须要大于0)。由公式
我们可以得出几个结论:
- 当i>1时,
 ,这可由均值不等式得到,也即点都在精确值的右侧;
,这可由均值不等式得到,也即点都在精确值的右侧; - 由1推出,可以大于
 也可以小于,只需要大于0即可,因为一次迭代之后都会变为结论1;
也可以小于,只需要大于0即可,因为一次迭代之后都会变为结论1;
所以,牛顿迭代存在一个初值选择的问题,选择得好会极大降低迭代的次数,选择得差效率也可能会低于二分法。我们先给出一个采用新初值的代码:
float SqrtByNewton(float x)
{
int temp = (((*(int *)&x)&0xff7fffff)>>1)+(64<<23);
float val=*(float*)&temp;
float last;
do
{
last = val;
val =(val + x/val) / 2;
}while(fabsf(val-last) > eps);
return val;
}
对上述代码重复之前的测试,运行时间由1000毫秒降为240毫秒,性能提升了接近4倍多!为啥改用上面复杂的两句代码就能使速度提升这么多呢?这就需要用到我们之前博客介绍的IEEE浮点数表示。我们知道,IEEE浮点标准用

现在需要对这个浮点数进行开方,我们看看各部分都会大致发生什么变化。指数E肯定会除以2,127保持不变,m需要进行开方。由于指数部分是浮点数的大头,所以对指数的修改最容易使初始值接近精确值。幸运的是,对指数的开平方我们只需要除以2即可,也即右移一位。但是由于E+127可能是奇数,右移一位会修改指数,我们将先将指数的最低位清零,这就是& 0xff7fffff的目的。然后将该转换后的整数右移一位,也即将指数除以2,同时尾数也除以2(其实只是尾数的小数部分除以2)。由于右移也会将127除以2,所以我们还需要补偿一个64,这就是最后还需要加一个(64<<23)的原因。
这里大家可能会有疑问,最后为什么加(64<<23)而不是(63<<23),还有能不能不将指数最后一位清零?答案是都可以,但是速度都没有我上面写的快。这说明我上面的估计更接近精确值。下面简单分析一下原因。首先假设e为偶数,不妨设e=2n,开方之后e则应该变为n,127保持不变,我们看看上述代码会变为啥。e+127是奇数,会清零,这等价于e+126,右移一位变为n+63,加上补偿的64,指数为n+127,正是所需!再假设e为奇数,不妨设e=2n+1,开方之后e应该变为n+1(不精确),127保持不变,我们看看上述代码会变为啥。e+127是偶数等于2n+128,右移一位变为n+64,加上补偿的64,指数为n+1+127,也是所需!这确实说明上述的估计比其他方法更精确一些,因而速度也更快一些。
虽然优化之后的牛顿迭代算法比二分快了很多,但是速度都还是低于库函数sqrtf,同样的测试sqrtf只需要100毫秒,性能是优化之后牛顿迭代算法的3倍!库函数到底是如何实现的!这说明我们估计的初始值还不是那么精确。不要着急,我们下面介绍一种比库函数还要快的算法,其性能又是库函数的10倍!
3卡马克算法
这个算法是99年被人从一个游戏源码中扒出来的,作者号称是游戏界的大神卡马克,但是追根溯源,貌似这个算法存在的还要更久远,原始作者已不可考,暂且称为卡马克算法。啥都不说,先上代码一睹为快:
float SqrtByCarmack( float number )
{
int i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( int * ) &y;
i = 0x5f375a86 - ( i >> 1 );
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) );
y = y * ( threehalfs - ( x2 * y * y ) );
y = y * ( threehalfs - ( x2 * y * y ) );
return number*y;
}
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}

图2 牛顿迭代法求开方倒数
最原始的版本不是求开方,而是求开方倒数,也即![]() 。为啥这样,原因有二。首先,开方倒数在实际应用中比开方更常见,例如在游戏中经常会执行向量的归一化操作,而该操作就需要用到开方倒数。另一个原因就是开方倒数的牛顿迭代没有除法操作,因而会比先前的牛顿迭代开方要快。但是上面的代码貌似很难看出牛顿迭代的样子,这是因为函数变了,由
。为啥这样,原因有二。首先,开方倒数在实际应用中比开方更常见,例如在游戏中经常会执行向量的归一化操作,而该操作就需要用到开方倒数。另一个原因就是开方倒数的牛顿迭代没有除法操作,因而会比先前的牛顿迭代开方要快。但是上面的代码貌似很难看出牛顿迭代的样子,这是因为函数变了,由![]() 变为
变为![]() ,因而求解公式也需改变,但是递推公式的推导不变,如图二所示。按照之前的推导方式我们有:
,因而求解公式也需改变,但是递推公式的推导不变,如图二所示。按照之前的推导方式我们有:
由这个公式我们就很清楚地明白代码y =y*(threehalfs-(x2*y*y)); 的含义,这其实就是执行了单次牛顿迭代。为啥只执行了单次迭代就完事了呢?因为单次迭代的精度已经达到相当高的程度,代码也特别注明无需第二次迭代(达到游戏要求的精度)。图三给出了对从0.01到10000之间的数进行开方倒数的误差(from维基百科),可以看出误差很小,而且随着数的增大而减小。
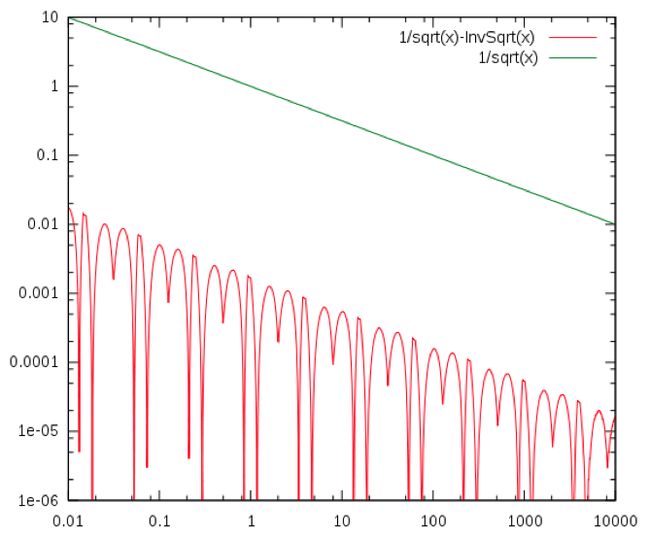
图三 卡马克算法的误差
为什么单次迭代就可以达到精度要求呢?根据之前的分析我们可以知道,最根本的原因就是选择的初值非常接近精确解。而估计初始解的关键就是下面这句代码:
i = 0x5f3759df - ( i >> 1 );是由于这句代码,特别是其中的“magic number”使算法的初始解非常接近精确解。具体的原理又用到前面博客介绍的地址强转:首先将float类型的数直接进行地址转换转成int型(代码中long在32位机器上等价于int),然后对int型的值进行一个神奇的操作,最后再进行地址转换转成float类型就是很精确的初始解。
在前面的博客中,我们曾经针对float型浮点数和对应的int型整数之间的关系给出一个公式:
![]()
算法的最终目的是要对浮点数开平方,而原始的卡马克算法求的是开方倒数,所以我们最初的代码返回的结果是原始值乘以开方倒数。该算法性能非常高,而且精度也很高,三次迭代精度就和系统函数一样,但是速度只有系统函数sqrtf的十分之一不到,相当了得。
4 改进的牛顿迭代
卡马克算法也启发我们能不能对原始的牛顿迭代开方算法进行类似的修改。之前我们已经提供了一种方法去估计初始值,而且获得了不错的性能提升,我们希望通过按照卡马克算法的思路修改初始值的估计来获得更大的性能提升。要求这样的结果让人感到沮丧,按理说应该会比卡马克算法慢,但是依旧差20多倍就不能理解了,难道初始解选择的还不好?一怒之下,我将循环去掉,也改成只迭代三次,得到的结果和系统函数得到的结果一样,只是速度上慢了一倍而已!这个结果很令人吃惊,这说明do循环的开销其实很大。这个结论可以通过在卡马克算法中也添加do循环得到:如果在卡马克算法中添加for循环之后,运行速度立刻降了10倍!为什么do循环会如此慢呢?一个原因可能是只需fabsf的原因,其他原因还不详。
通过速度慢一倍我们能得到什么结论呢?原始的牛顿迭代用了两次除法(加法忽略),而卡马克算法则用了三次乘法(在返回结果时还有一次),都是迭代三次,它们的性能相差一倍,我们可以推出除法的运行时间大约是乘法的三倍多。这个结论启示我们,优化掉除法是提速的一个重要途径。
在猜测如果将我最开始估计初始值的do循环也去掉,则三次迭代精度达不到要求,说明我自己臆想出来的初始值还是太差,初始值估计确实是一门学问。总结一下牛顿迭代和卡马克算法,我们能得到什么经验教训呢?首先,为了获得最好的性能,代码中尽量不要有循环,这也就是循环展开存在的意义;其次,两个算法最后的对比完全是除法和乘法的对比,尽量通过数学变换消除代码中的除法,这也会带来不少的性能提升;深入了解浮点数在计算机中的存储结构很重要,在不少问题上会给我们带来很多极致性能的解法。
6 总结
本博客对浮点开方常用的方法进行了一一介绍,希望能对大家产生些积极的影响。最后,将我的所有实验结果贴出来,供大家参考。我的CPU型号为双核32位酷睿2 T5750,内存2G,测试的内容是对1到300w内的整数进行开方运算,运行时间如下:
后来又在公司的服务器上重测了一遍,直接伤心了。服务器CPU为24核64位至强E5-2630,内存128G,编译器为花钱购买的icc编译器。测试的内容是对1到1000w内的整数进行开方运算,运行时间如下:

看到这个结果,我只能说系统函数无敌了(没有算错)!上面写的全部作废,以编译器实测为准……