手把手教你K最近邻分类器分类CIFAR-10
KNN算法全称为k-Nearest Neighbor Classifier,即k最近邻分类器。它可以看作是Nearest Neighbor Classifier最近邻分类器的加强版,无论是最近邻分类器还是k最近邻分类器,其原理都比较简单,其算法在CIFAR-10图像分类的效果上其正确率远低于人类识别图像的正确率(约94%),但也略高于随即猜测的10%的正确率(CIFAR-10有10个分类,随机猜测的正确率为10%)。
基于最近邻分类器的CIFAR-10的图像分类
CIFAR-10可视化 可参考:https://blog.csdn.net/qq_36552550/article/details/105835108
1.最近邻分类器原理
前面的CIFAR可视化将200副图像保存在了10个文件夹当中,观察ship文件夹中的前两幅图片“8.jpg”以及“62.jpg”,如图1所示。直观上来看,天空和大海都是蓝色的,船则是白色的,位于图像正中间;照此推理,相似的类别的图像,比如船,图像大致是类似的。

图5-3-1 ship文件夹中前两幅图像对比
那么,要判断test_batch中的某一幅图像属于哪一个类别,可以将该图像和data_batch1至data_batch5的图像依次比对,找出最相似的一副图像,这样就认为该图像和最相似图像属于一个类别。
具体实现上,将test_batch中的图像的每一个像素的RGB数值依次减去data_batch1至data_batch5的图像的每一个像素的RGB数值,将相减的数求绝对值,然后将所有的绝对值相加,得出和值,依照这个和值的大小来判断两幅图像的相似度;两幅图像相似程度越高,这个和值应该越低。以此,可以推断test_batch中图像属于哪一个类别。
该过程可以视作求取两向量L1距离的过程。因为每幅图像在CIFAR-10中以行向量进行保存,则可认为两幅图像为两个向量I1、I2,求两向量的L1距离即可得出结果:![]()
(L1距离为求差值的绝对值,而L2距离则是求平方和的开平方;这里使用L1距离的好处就是计算量更小)
Numpy的广播机制、sum()函数以及argmin()函数
test_batch文件同样是一行代表一副图片,然后将该行依次减去data_batch_1至5的每一行,如果将data_batch_1至5的图像数据全部拼接在一起,相当于是一个1*3072的数组减去一个50000*3072的数组的每一行。这里面就涉及两个编程实现的问题——1.data_batch_1至5的数据拼接;2.一个1*3072的数组减去一个50000*3072的数组的每一行的实现。
首先,看一下数据拼接的问题。将data_batch_1至5文件中字典dictionary类型里面的图像数据和标签读出,读出后为列表list类型,进行计算的时候需要提前将list类型转换成Numpy的array类型,并且维度也要符合50000*3072需要。
接下来看一个简单的程序例子,如程序1所示。
程序1 数据拼接示例
import numpy as np
x = []
a = [[1,2],[3,4]]
b = [[5,6],[7,8]]
print(a)
print(b)
x.append(a)
print(x)
x.append(b)
print(x)
xb = np.array(x)
print(xb)
print(xb.shape)
xa = np.concatenate(x)
print(xa)
print(xa.shape)首先看第2行至第11行,通过append()函数,列表x依次将列表a和列表b放入自己的列表中;如图2所示。
图2 列表x续接结果示意图
这个时候如果直接转为Numpy的array类型,即13行至15行,那么得到的结果如图3所示,是一个2*2*2的数组。

图3 拼接后直接转数组array类型结果示意图
如果想拼接位一个4行2列的数组怎么办呢?这时候可以使用numpy中的concatenate()函数,具体该函数的用法可以自行查阅资料。程序1中将2*2*2的列表类型转换为了4*2的数组类型。

图4 拼接后
拼接问题解决后,就可以实现一个1*3072的数组减去一个50000*3072的数组的每一行,当然,这里写for语句循环也可以。但是Numpy提供更简单的方法——广播机制。一个示例如果程序2所示。
程序2 广播机制示例
import numpy as np
a = np.array([[1,2],[3,4],[5,6]])
b = np.array([1,1])
c = np.array([[1],[1]])
r1 = a - b
#r2 = a - c #error
r3 = b + c
r4 = b - a
#r5 = c - a #error
print(r1)
print(r3)
print(r4)分别创建数组a,b,c,其维度分别为3*2,1*2,2*1。
第7行a-b可以认为a加上一个负的b,可以看到a数据每一行都加上了一个负的b,如图5所示。

5 a-b结果示意图
同理,b-a可以认为b加上一个负的a,如图6所示。

图6 b-a结果示意图。
可以看到,广播机制可以自动补齐数组,以方便进行俩数组的加减。第9行1*2数组b和2*1数组c亦可以进行加减。但是,第8行以及第11行的无法通过填补实现广播机制。
完成两个数组的减法后,还需要对获得的每一行的数值进行求绝对值的和,并且在求和后的结果中找到最小的那个数。这需要用到两个求和函数sum()以及获取数组中最小数值的下标函数argmin(),如程序3所示。
程序3 sum()以及argmin()使用示例
import numpy as np
arr1 = np.array([[10,20],[-3,-4],[5,6],[0,1]])
arr2 = np.abs(arr1)
print(arr2)
arr_row_sum = np.sum(arr2,axis = 1)
print(arr_row_sum)
print(arr_row_sum.shape)
min_sum = np.argmin(arr_row_sum)
print(min_sum)程序结果如图7所示。
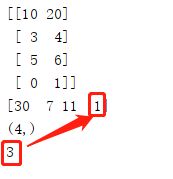
图7 程序3结果示意图
创建4行3列数组arr1,对arr1求绝对值获得arr2,打印arr2;第7行调用sum()函数实现对arr2进行求和,其中第二个参数axis等于0时对列求和,等于1时对行求和;打印arr_row_sum可看到结果为[30 7 11 1],虽然是横向显示,但查看该数组的shape属性,可以看到是4行的数组,而非4列。最后调用argmin()函数获取arr_row_sum中的最小值的下标,可以看到结果返回了3,对应的数字1。
实现CIFAR-10图像分类
测试计算机装Window 10系统,4G内存,安装有常用软件;但一次性读取data_batch1至data_batch5时直接内存爆炸。
为了防止将五个训练集文件全部读取造成内存不足的情况出现,该小节程序只选择了data_batch1以及data_batch2作为训练集。
CIFAR-10图像分类实现如程序4所示。
程序4 基于最近邻分类器实现CIFAR-10图像分类
import pickle
import os
import numpy as np
n = 2
def unpickle_as_array(filename):
with open(filename, 'rb') as f:
dic = pickle.load(f,encoding='latin1')
dic_data = dic['data']
dic_labels = dic['labels']
dic_data = np.array(dic_data).astype('int')
dic_labels = np.array(dic_labels).astype('int')
return dic_data, dic_labels
def load_batches(root,n):
train_data = []
train_labels = []
for i in range(1,n+1,1):
f = os.path.join(root,'data_batch_%d' %i)
data, labels = unpickle_as_array(f)
train_data.append(data)
train_labels.append(labels)
train_data_r = np.concatenate(train_data)
train_labels_r = np.concatenate(train_labels)
del train_data, train_labels
test_data, test_labels = unpickle_as_array(os.path.join(root, 'test_batch'))
return train_data_r, train_labels_r, test_data, test_labels
def nn_classification(train_d, test_d, train_l):
count = 0
result = np.zeros(10000)
for i in range(10000):
d_value = test_d[i] - train_d
distance = np.sum(np.abs(d_value), axis=1)
min_dis = np.argmin(distance)
result[i] = train_l[min_dis]
print('the %dth image\'s label: %d' % (count, result[i]))
count = count + 1
return result
train_data, train_labels, test_data, test_labels = load_batches('E:/cifar/cifar-10-batches-py', n)
result = nn_classification(train_data, test_data, train_labels)
print('the algorithm\'s accuracy: %f' % (np.mean(result == test_labels)))第5行的n表示使用多少个训练集,如计算机内存较小,一次使用5个容易造成内存爆炸,在本程序中设置为2,如果想读取5个进行测试可将n赋值改为5即可;其次,训练集越大,需要计算的时间也越长。
(跑完以上程序的参考时间:Intel(R) Core(TM) i5-6200U CPU @ 2.3GHz 2.40GHz,64位系统,完成以上程序耗时大约70分钟)
16至28行代码实现了函数load_batches(),将n个训练集文件读入,root为文件的根路径,函数实现使用了append()以及concatenate()函数,前文已经讲过,这里不再累述。
30至40行 代码实现了最近邻分类器——nn_classification()函数,结果保存在一个10000行的result中, 因为测试集总共10000副图片,对应10000行,所以需要循环10000次得到所有结果,for循环语句内通过广播机制、求绝对值的和值、找到最小值下标等操作,得到result。
为了获取最近邻分类器的准确度,通过将测试集最终结果result和测试集真实的标签之间进行比对,然后求其均值,得到最终的准确度。
以上程序输出结果如图8所示。

图8 基于最近邻分类器实现CIFAR-10图像分类结果截图
可以看出,最终的识别准确率虽然只达到了33.85%,但比随机猜测的10%要高出来很多。
2.k最近邻分类器
k最近邻分类器原理
当使用最近邻分类器进行test_batch中图像的预测时,只选取了最类似图像的标签。除此之外,还可以使用k最近邻分类器。有了最近邻分类器,这个k最近邻分类器就很简单了:最近邻分类器是在训练集中找到最接近的1个图像,而k最近邻分类器则是找到最接近的K个图像,最接近的K个图像中最多的那个标签类别即分类结果。可知,当k=1时,K最近邻分类器即最近邻分类器。
k最近邻分类的函数实现
这里只需要更改程序1中的NNClassTest()函数即可,新的KNNClassTest()函数如下2所示。
程序5 K最近邻分类器的函数实现
import pickle
import os
import numpy as np
n = 2
def unpickle_as_array(filename):
with open(filename, 'rb') as f:
dic = pickle.load(f,encoding='latin1')
dic_data = dic['data']
dic_labels = dic['labels']
dic_data = np.array(dic_data).astype('int')
dic_labels = np.array(dic_labels).astype('int')
return dic_data, dic_labels
def load_batches(root,n):
train_data = []
train_labels = []
for i in range(1,n+1,1):
f = os.path.join(root,'data_batch_%d' %i)
data, labels = unpickle_as_array(f)
train_data.append(data)
train_labels.append(labels)
train_data_r = np.concatenate(train_data)
train_labels_r = np.concatenate(train_labels)
del train_data, train_labels
test_data, test_labels = unpickle_as_array(os.path.join(root, 'test_batch'))
return train_data_r, train_labels_r, test_data, test_labels
def knn_classification(train_d, test_d, train_l, k):
count = 0
result = np.zeros(10000)
for i in range(10000):
d_value = test_d[i] - train_d
distance = np.sum(np.abs(d_value), axis=1)
dis_sort = np.argsort(distance)
vote_label = np.zeros(10)
for j in range(k):
vote_label[train_l[dis_sort[j]]] += 1
result[i] = np.argmax(vote_label)
print('the %dth image\'s label: %d' % (count, result[i]))
count = count + 1
return result
train_data, train_labels, test_data, test_labels = load_batches('E:/cifar/cifar-10-batches-py', n)
result = knn_classification(train_data, test_data, train_labels,3)
print('the algorithm\'s accuracy: %f' % (np.mean(result == test_labels)))K最近邻分类器程序实现只需在程序4上进行部分修改即可。程序5 的30行以前代码和4一致,这里不再在书中显示。
程序5在30行开始实现了knn_classification()函数,多了一个参数k,因为这里需要找到差值绝对值之和最小的k个图像。
那么,首先要对所求的差值进行排序,在36行代码中使用argsort()函数——返回数组值从小到大的索引值。
创建vote_label 数组,对差值绝对值之和最小的k个图像对应的标签进行记录。
第37至40行是关键——假定k=3,那么for循环循环3次,j分别为0,1,2;那么dis_sort[0],dis_sort[1],dis_sort[2]分别表示前3个最小的差值绝对值之和图像的索引,有了图像索引,就可以通过索引去找到该图像对应的标签,即train_l[dis_sort[j]]获得了对应的标签,那么就可以在该标签投一票;假如train_l[dis_sort[0]],train_l[dis_sort[1]],train_l[dis_sort[2]]分别为3,6,3(也就是对应标签为3,6,3);那么标签3就有了两票,而6有了一票;其他标签0票,即 在for循环中,vote_label[train_l[dis_sort[j]]] 要加一,表示对应标签上面投一票,3次循环结束,vote_label应为[0,0,0,2,0,0,1,0,0,0];可以看出vote_label中最大的值为2,再通过argmax()函数获取数组中最大值对应的下标,这里应该为3了,那么结果即为3。
47行调用knn_classification()函数,其中第四个参数k值为3,程序运行结果如图9所示。
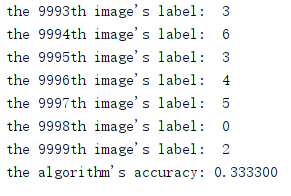
图9 基于k最近邻分类器实现CIFAR-10图像分类结果截图
在某些场景下k-NN算法的效果要好于NN算法,但可以看出在本例中其准确度为0.3333,低于NN算法的准确度。
可以看到以上方法有着一些明显的缺点: 最近邻分类的过程是通过比对所有数据集中训练集的图片来完成的,所以必须将所有图片读取在内存中,容易造成内存爆炸;其次,对一幅图像进行判断类别,需要比对所有训练集的图像,识别的过程消耗计算量巨大;最重要的是,该方法的识别正确率也差强人意,对于CIFAR-10数据集只有30%左右。