GAN实战(1)——Keras使用ACGAN实现数据扩增(含代码)
之前一篇博客介绍了GAN网络的原理,之后对原始GAN网络进行了多次改进,可以实现不同的任务。这篇博客起开始用GAN实现各种任务,直接在实战中学习各种GAN网络。
GAN实战(1)——Keras使用ACGAN实现数据扩增(含代码)
- 1、什么是ACGAN
- 2、数据集准备
- 3、ACGAN网络的结构详解
- 3.1 生成模型
- 3.2 判别模型
- 3.3 模型训练
- 5、主体代码
- 6、模型调用
- 7、总结
- 8、参考
1、什么是ACGAN
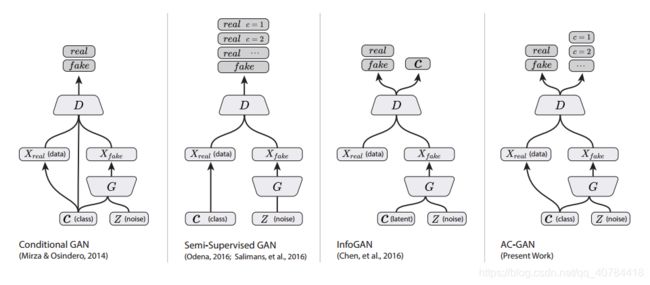
ACGAN是DCGAN(深度卷积生成对抗网络)和CGAN(条件生成对抗网络)一个融合。
DCGAN是在GAN的基础上把生成模型和判别模型用卷积神经网络来构建。
CGAN是在GAN的基础上在生成模型和判别模型中均引入条件变量y,使用额外信息y对模型增加条件,可以指导数据生成过程。
CAGAN是在存在类别标签的情况下,将深度卷积网络带入到GAN当中,提高图片的生成质量;可以看做把纯无监督的 GAN 变成有监督的模型的一种改进。
简单来讲,普通的GAN输入的是一个N维的正态分布随机数,而ACGAN会为这个随机数添上标签,其利用Embedding层将正整数(索引值)转换为固定尺寸的稠密向量,并将这个稠密向量与N维的正态分布随机数相乘,从而获得一个有标签的随机数。
与此同时,ACGAN将深度卷积网络带入到存在标签的GAN中,可以生成更加高质量的图片。
参考链接
2、数据集准备
本文使用的的事交通标志的数据集,选用了四个类别的交通标志,标签标注为00,01,02,03,把图片放入相应的文件夹中,数据集准备完毕。


3、ACGAN网络的结构详解
3.1 生成模型
ACGAN的生成模型有卷积神经网络构成,它的目的是根据输入随机数个标签生成图片:
(1)模型输入:一个带标签的随机数,具体操作方式是生成一个N维的正态分布随机数,再利用Embedding层将正整数(索引值)转换为N维的稠密向量,并将这个稠密向量与N维的正态分布随机数相乘。
(2)模型结构:输入的数进行reshape然后利用一系列的上采样与卷积生成相应尺寸的图像
(3)模型的输出:生成的一张图片。
输入数据操作代码如下:
#随机数
noise = Input(shape=(self.latent_dim,))
#标签数据
label = Input(shape=(1,), dtype='int32')
#利用Embedding层将正整数(索引值)转换为N维的稠密向量
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
#将稠密向量与N维的正态分布随机数相乘得到最终的生成模型的输入
model_input = multiply([noise, label_embedding])
构建生成模型的代码如下:
# 输入一个随机数(100,)和标签(1,),输出一个(32,32,3)的图片
def build_generator(self):
model = Sequential()
# 先全连接到32*8*8的维度上
model.add(Dense(32 * 8 * 8, activation="relu", input_dim=self.latent_dim))
# reshape成特征层的样式
model.add(Reshape((8, 8, 32)))
# 8, 8, 64
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 8, 8, 64 -> 16, 16, 128
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 16, 16, 128 -> 32, 32, 64
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 32, 32, 64 -> 32, 32, 3
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
3.2 判别模型
ACGAN的判别网络由卷积构成,与普通GAN的判别模型相比,它的目的不仅要判断出真伪,还要判断出种类(普通GAN的判别模型的目的是根据输入的图片判断出真伪)。
(1)模型输入:一张图片,可以是真实的,也可以是生成的假图片
(2)模型结构:输入的数进行reshape然后利用一系列的降采样与卷积得到特征图
(3)模型的输出:判断出真伪和种类的结果。输出有两个:一个是0到1之间的数,1代表判断这个图片是真的,0代表判断这个图片是假的;另一个是一个向量,用于判断这张图片属于什么类。
def build_discriminator(self):
model = Sequential()
# 32,32,3 -> 16,16,16
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 16,16,16 -> 8,8,32
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 8,8,32 -> 4,4,64
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 4,4,64 -> 4,4,128
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
img = Input(shape=self.img_shape)
features = model(img)
validity = Dense(1, activation="sigmoid")(features)
label = Dense(self.num_classes, activation="softmax")(features)
return Model(img, [validity, label])
3.3 模型训练
与传统的GAN训练思想大致相同,只不过在此基础上增加了分类的输出。
ACGAN的训练思路分为如下几个步骤:
1、随机选取batch_size个真实的图片和它的标签。
2、随机生成batch_size个N维向量和其对应的标签label,利用Embedding层进行组合,传入到Generator中生成batch_size个虚假图片。
3、Discriminator的loss函数由两部分组成,一部分是真伪的判断结果与真实情况的对比,一部分是图片所属标签的判断结果与真实情况的对比。
4、Generator的loss函数也由两部分组成,一部分是生成的图片是否被Discriminator判断为1,另一部分是生成的图片是否被分成了正确的类。
def train(self, epochs, batch_size=64, sample_interval=50, file_path=None):
# 获得训练数据的图像及标签
X_train, y_train = self.load_data(file_path)
y_train = y_train.reshape(-1, 1)
# 设定标签
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# 训练鉴别模型
# 随机选取batch_size个真实的图片和它的标签。
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs, labels = X_train[idx], y_train[idx]
#Generator中生成batch_size个虚假图片
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
sampled_labels = np.random.randint(0, self.num_classes, (batch_size, 1))
gen_imgs = self.generator.predict([noise, sampled_labels])
# Discriminator的loss函数由两部分组成
d_loss_real = self.discriminator.train_on_batch(imgs, [valid, labels])
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, sampled_labels])
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# 训练生成模型
# Generator的loss函数也由两部分组成
g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
print ("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss[0]))
if epoch % sample_interval == 0:
self.sample_images(epoch)
# 保存
if epoch % 10000 == 0 :
os.makedirs('weights', exist_ok=True)
self.generator.save_weights("weights/gen_epoch%d.h5" % epoch)
self.discriminator.save_weights("weights/dis_epoch%d.h5" % epoch)
5、主体代码
import random
import cv2
import tensorflow as tf
from imutils import paths
from keras.datasets import mnist
from keras.backend.tensorflow_backend import set_session
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D, GlobalAveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
from keras import backend as K
import matplotlib.pyplot as plt
import os
import numpy as np
from keras.preprocessing.image import img_to_array
from keras.utils import to_categorical
class ACGAN():
def __init__(self):
# 输入shape
self.img_rows = 32
self.img_cols = 32
self.channels = 3
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# 分4类
self.num_classes = 4
self.latent_dim = 100
self.Labels = ['001', '002', '003', '004']
# adam优化器
optimizer = Adam(0.0002, 0.5)
# 判别模型
losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=losses,optimizer=optimizer,metrics=['accuracy'])
# 生成模型
self.generator = self.build_generator()
# conbine是生成模型和判别模型的结合
# 判别模型的trainable为False
# 用于训练生成模型
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,))
img = self.generator([noise, label])
self.discriminator.trainable = False
valid, target_label = self.discriminator(img)
# 构建用于训练生成模型的网络
self.combined = Model([noise, label], [valid, target_label])
self.combined.compile(loss=losses,optimizer=optimizer)
# 数据预处理
def load_data(self, path):
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(path)))
random.seed(42)
random.shuffle(imagePaths)
for imagePath in imagePaths:
image = cv2.imread(imagePath)
image = cv2.resize(image, (self.img_rows, self.img_cols))
image = img_to_array(image)
data.append(image)
label = str(imagePath.split(os.path.sep)[-2])
labels.append(label)
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
return data, labels
def build_generator(self):
model = Sequential()
# 先全连接到32*8*8的维度上
model.add(Dense(32 * 8 * 8, activation="relu", input_dim=self.latent_dim))
# reshape成特征层的样式
model.add(Reshape((8, 8, 32)))
# 8, 8, 64
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 8, 8, 64 -> 16, 16, 128
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 16, 16, 128 -> 32, 32, 64
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
# 上采样
# 32, 32, 64 -> 32, 32, 3
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
def build_discriminator(self):
model = Sequential()
# 32,32,3 -> 16,16,16
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
# 16,16,16 -> 8,8,32
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 8,8,32 -> 4,4,64
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
# 4,4,64 -> 4,4,128
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
img = Input(shape=self.img_shape)
features = model(img)
validity = Dense(1, activation="sigmoid")(features)
label = Dense(self.num_classes, activation="softmax")(features)
return Model(img, [validity, label])
def train(self, epochs, batch_size=64, sample_interval=50, file_path=None):
X_train, y_train = self.load_data(file_path)
y_train = y_train.reshape(-1, 1)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# --------------------- #
# 训练鉴别模型
# --------------------- #
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs, labels = X_train[idx], y_train[idx]
# ---------------------- #
# 生成正态分布的输入
# ---------------------- #
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
sampled_labels = np.random.randint(0, self.num_classes, (batch_size, 1))
gen_imgs = self.generator.predict([noise, sampled_labels])
d_loss_real = self.discriminator.train_on_batch(imgs, [valid, labels])
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, sampled_labels])
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# --------------------- #
# 训练生成模型
# --------------------- #
g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
print ("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[3], 100*d_loss[4], g_loss[0]))
if epoch % sample_interval == 0:
self.sample_images(epoch)
# 保存
if epoch % 10000 == 0 :
os.makedirs('weights', exist_ok=True)
self.generator.save_weights("weights/gen_epoch%d.h5" % epoch)
self.discriminator.save_weights("weights/dis_epoch%d.h5" % epoch)
def sample_images(self, epoch):
r, c = 2, 2
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.arange(0, 4).reshape(-1, 1)
print(sampled_labels)
gen_imgs = self.generator.predict([noise, sampled_labels])
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt,:,:,0])
axs[i,j].set_title("Digit:" + str(self.Labels[cnt]))
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
def test(self, Label, weight_path):
self.generator.load_weights(weight_path, skip_mismatch=True)
noise = np.random.normal(0, 1, (1, 100))
labels = Label
print(noise.shape)
print(labels.shape)
img = self.generator.predict([noise, labels])
plt.imshow(img[0])
plt.show()
if __name__ == '__main__':
if not os.path.exists("./images"):
os.makedirs("./images")
acgan = ACGAN()
path = './flower_photos'
acgan.train(epochs=20000, batch_size=256, sample_interval=500, file_path=path)
本次模型只是简单的卷积神经网络搭建,且模型训练并未有达到最优,但是我们可以看到已经能分辨出交通标志,效果图如下:

6、模型调用
加载生成模型的权重,给定随机数和特定的标签即可调用生成模型生成(32,32,3)的图片,达到数据扩增的目的。
if __name__ == '__main__':
acgan = ACGAN()
weight_path = "./weights/gen_epoch20000.h5"
acgan.test(Label =np.array([[3]]),weight_path = weight_path)
输入标签为3,输出如下:
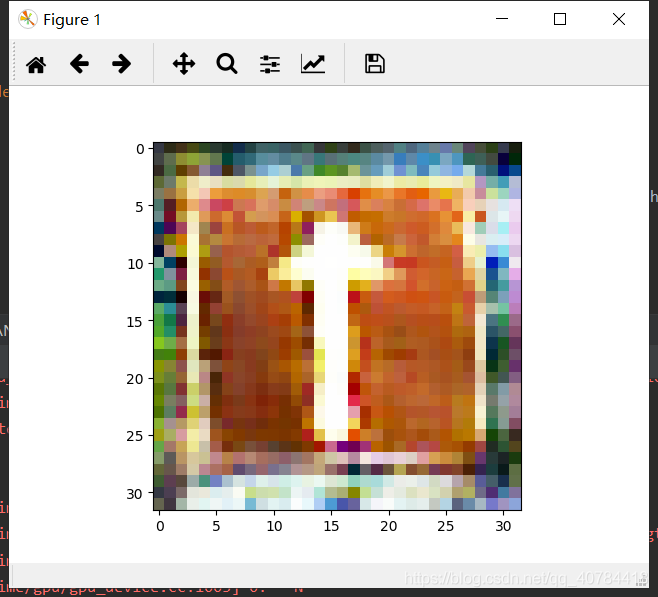
7、总结
(1)ACGAN是DCGAN和CGAN的结合,本篇博客相当于学习了三种GAN网络:DCGAN(深度卷积生成对抗网络)、CGAN(条件生成对抗网络)和ACGAN。
(2)本篇博客的生成模型和判别模型只是基础的卷积叠加,并且没有训练到最优效果。生成图像已初具外表但还不能满足实际应用,可以对模型继续训练或优化生成模型和判别模型结构等提高网络效果。
(3)pix2pix和WGAN通过改进GAN可以提高生成图片的质量,下一篇博客尝试更优的GAN网络实战。
(4)完整代码已上传,需要的点击链接下载。
(5)交通标志的数据集下载连接点击下载,可以在自己的电脑上跑一跑。
8、参考
https://blog.csdn.net/weixin_44791964/article/details/103746380