PyTorch搭建神经网络——MNIST手写数据集
文章目录
- MNIST数据集介绍
- 搭建网络过程
- Step1
- Step2
- Step3
- Step4
- Step5
- Step6
- Step7
之前自己写的网络一直放在为知笔记里,现在把它们移到这边来。
MNIST数据集介绍
MNIST数据集是学习模式识别和各大深度学习框架的基础数据库,共含有60000个训练样本和10000个测试样本,60000个训练样本又拆分为55000个训练样本和5000个验证样本,验证样本为每张28×28的灰度图片
MNIST数据集可以在:http://m.cnwest.com/data/html/content/11271894.html获取,它一共包含了四个部分:
1、Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
2、Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
3、Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
4、Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
解压后如下:

搭建网络过程
Step1
仿照莫烦PYTHON里面的分类问题和批训练两节内容,搭建一个只有一个隐藏层且有100个神经元的神经网络
代码如下:
import torch
import torch.nn.functional as nn
import torch.utils.data as data
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
num_epoch = 10
BATCH_SIZE = 100
#MNIST数据集加载
train_dataset = datasets.MNIST(
root= '/home/cxm-irene/mnist',
train= True,
transform= transforms.ToTensor(),
download= False
)
train_loader = data.DataLoader(
dataset= train_dataset,
batch_size= BATCH_SIZE,
shuffle= True
)
test_dataset = datasets.MNIST(
root= '/home/cxm-irene/mnist',
train= False,
transform= transforms.ToTensor(),
download= False
)
#搭建网络
class Net_MNIST(torch.nn.Module):
def __init__(self, n_features, n_hidden, n_output):
super(Net_MNIST, self).__init__()
self.hidden = torch.nn.Linear(n_features, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = nn.relu(self.hidden(x))
x = self.predict(x)
return x
input_size = 28*28
num_class = 10
hidden_layer = 100
#定义网络
net_mnist = Net_MNIST(input_size, hidden_layer, num_class)
print(net_mnist)
#进行优化
optimizer = torch.optim.SGD(net_mnist.parameters(), lr = 0.005)
loss_function = torch.nn.CrossEntropyLoss()
#开始训练
for epoch in range(num_epoch):
print('epoch = %d' % epoch)
for i, (batch_x, batch_y) in enumerate(train_loader):
batch_x = Variable(batch_x.view(-1, 28*28))
batch_y = Variable(batch_y)
optimizer.zero_grad()
x = net_mnist(batch_x)
loss = loss_function(x, batch_y)
loss.backward()
optimizer.step()
if i % 50 == 0:
print('loss = %.5f' % loss.data[0])
prediction = torch.max(x, 1)[1]
pred_y = prediction.data.numpy().squeeze()
target_y = batch_y.data.numpy()
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
print('Accuracy=%.2f' % accuracy)
在step1里面,batch_size设置的是100,然后epoch设置的是10,优化器选择的是SGD,学习率设定的是0.005,
网络结构如下图:

图片是28*28的,中间隐藏层有100个神经元,然后最后输出的是10个分类
训练结果如下(截取了三个)
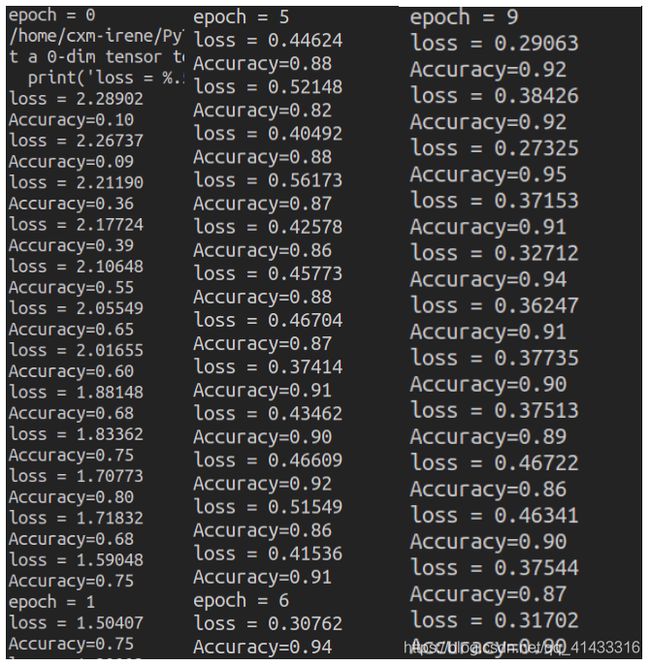
可以看到的是,loss值整体上是下降的,但是到后期这个趋势就没那么明显了,准确度到最后大概是0.9左右
Step2
两层隐藏层,每层隐藏层都是100个神经元,修改部分如下:
class Net_MNIST(torch.nn.Module):
def __init__(self, n_features, n_hidden1, n_hidden, n_output):
super(Net_MNIST, self).__init__()
self.hidden = torch.nn.Linear(n_features, n_hidden1)
self.hidden2 = torch.nn.Linear(n_hidden1, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = self.hidden(x)
x = nn.relu(x)
x = self.predict(x)
return x
input_size = 28*28
num_class = 10
hidden_layer1 = 100
hidden_layer2 = 100
#定义网络
net_mnist = Net_MNIST(input_size, hidden_layer1, hidden_layer2, num_class)
print(net_mnist)
网络结构:

这次多加了一个从测试集里面挑出10个数字进行测验的步骤,然后loss的输出也简化了一下:
…………
test_dataset = data.MNIST(……)
test_x = torch.unsqueeze(test_dataset.test_data, dim=1).type(torch.FloatTensor)
test_y = test_dataset.test_labels
…………
…………
…………
…………
test_output = net_mnist(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
print(pred_y[:10], 'prediction number')
print(test_y[:10].numpy(), 'real number')
结果如下:
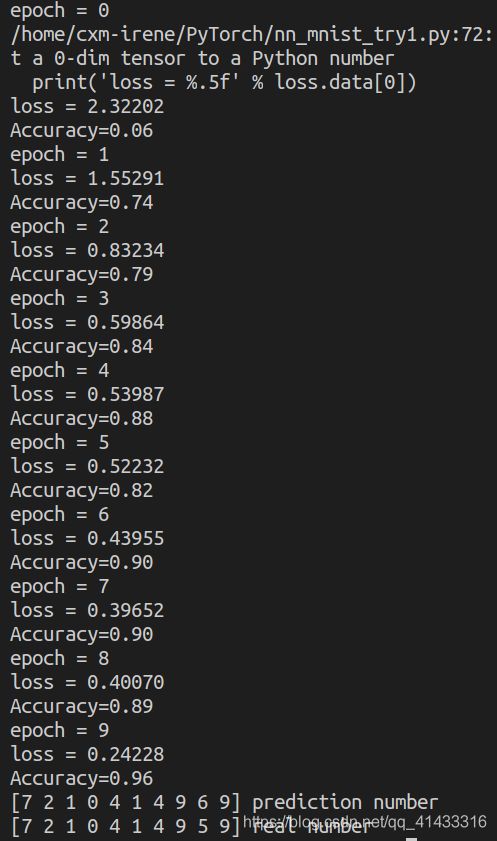
虽然最后准确率有0.96,但其实差不多也就是0.9附近,错了一个
把step1中只有一层隐藏层的结果也重新输出一遍,与第一次的结果差不太多,最后是0.88的准确率
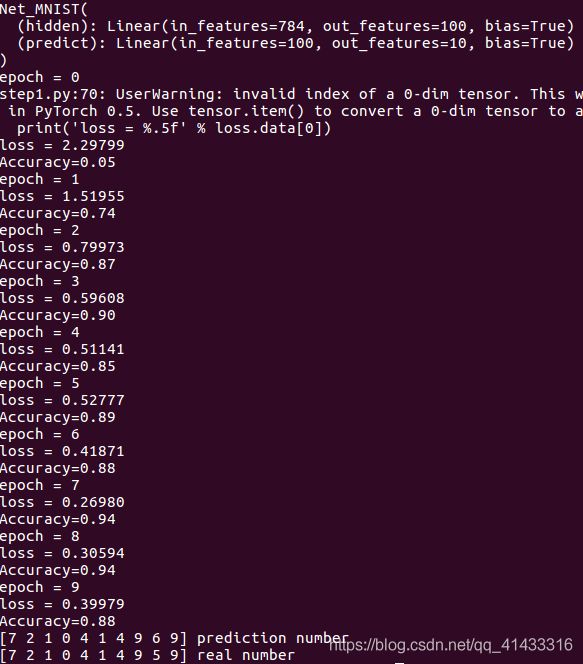
可以看到还是错了一个数字
Step3
这次不加层了,添加标准化
使用nn.Sequential()函数快速搭建网络,目前先试一下一层隐藏层,200个神经元,修改部分如下:
class Net_MNIST(torch.nn.Module):
def __init__(self, n_features, n_hidden, n_output):
super(Net_MNIST, self).__init__()
self.hidden = nn.Sequential(nn.Linear(n_features, n_hidden), nn.BatchNorm1d(n_hidden), nn.ReLU(True))
self.predict = nn.Linear(n_hidden, n_output)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.hidden(x)
x = self.predict(x)
return x
input_size = 28*28
num_class = 10
hidden_layer = 200
#定义网络
net_mnist = Net_MNIST(input_size, hidden_layer, num_class)
网络结构如下:

精确度如下:
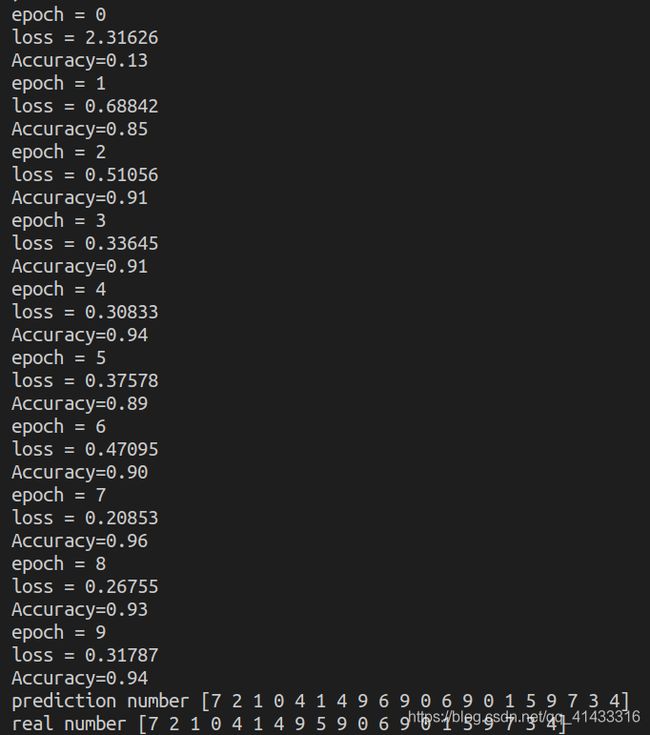
相比不加标准化的稳定了许多,精确度也高了一些,虽然它依旧把第八个数字识别错了。。。
Step4
只是加了一些隐藏层,这次试一下三层隐藏层,每层都是200个神经元,修改部分如下:
class Net_MNIST(torch.nn.Module):
def __init__(self, n_features, n_hidden1, n_hidden2, n_hidden3, n_output):
super(Net_MNIST, self).__init__()
self.hidden1 = nn.Sequential(nn.Linear(n_features, n_hidden1), nn.BatchNorm1d(n_hidden1), nn.ReLU(True))
self.hidden2 = nn.Sequential(nn.Linear(n_hidden1, n_hidden2), nn.BatchNorm1d(n_hidden2), nn.ReLU(True))
self.hidden3 = nn.Sequential(nn.Linear(n_hidden2, n_hidden3), nn.BatchNorm1d(n_hidden3), nn.ReLU(True))
self.predict = nn.Linear(n_hidden3, n_output)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.hidden3(x)
x = self.predict(x)
return x
input_size = 28*28
num_class = 10
hidden_layer1 = 200
hidden_layer2 = 200
hidden_layer3 = 200
#定义网络
net_mnist = Net_MNIST(input_size, hidden_layer1, hidden_layer2, hidden_layer3, num_class)
这是它的网络结构:
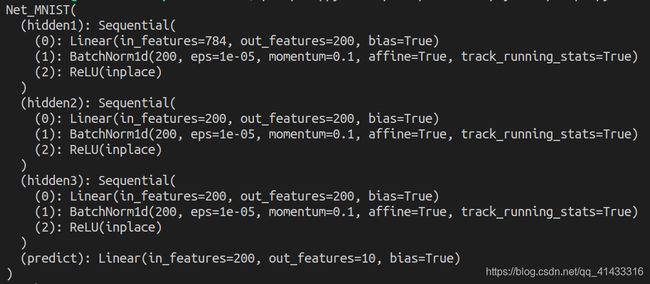
然后,,,和之前一样,结果如下:
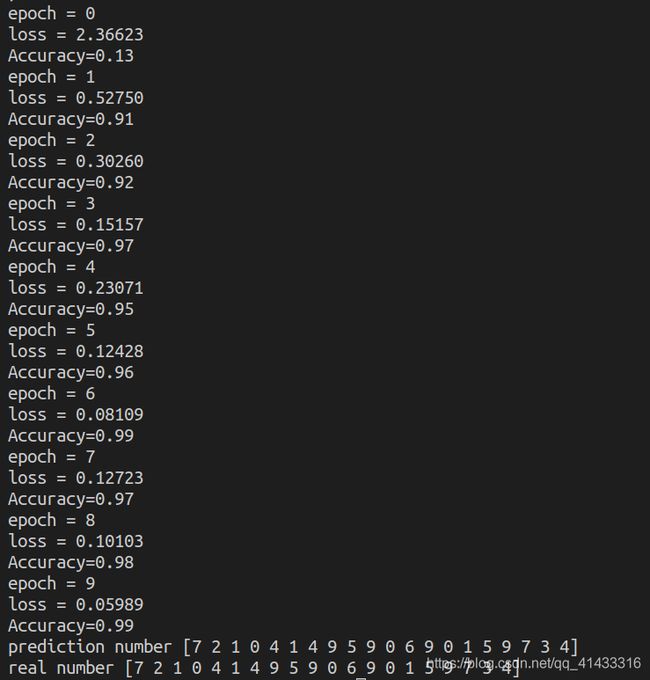
精确度很明显比之前高很多了,并且,终于第八个数字识别对了,hhhhh(不过后面重新训练了几次发现又错了。。。)
#修改
我发现我之前做的精确度一直是针对训练集做的,于是修改了一下,在训练完后针对测试集做了一个评估,代码如下:
total = 0
correct = 0
for batch_x, batch_y in test_loader:
batch_x = batch_x.view(-1, 28*28)
x = net_mnist(batch_x)
_, prediction = torch.max(x, 1)
total += batch_y.size(0)
correct += (prediction == batch_y).sum()
print('Accuracy=%.2f' % (100 * correct / total))
这样的话,那么,把先前的四个都重弄一下叭…
这是第一次的结果:

准确率只有百分之90
第二次:

依旧是90,这个之前我取了100个数据进行对比。。。
第三次:

提升到了93了
第四次:

提升到96了,但是这次依旧把5识别成了6。。。
Step5
正则化来防止过拟合,修改部分如下:
class Net_MNIST(torch.nn.Module):
def __init__(self, n_features, n_hidden, n_output):
super(Net_MNIST, self).__init__()
self.hidden = nn.Sequential(nn.Linear(n_features, n_hidden), nn.Dropout(0.5), nn.ReLU(True))
self.predict = nn.Linear(n_hidden, n_output)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.hidden(x)
x = self.predict(x)
return x
这个是在step1的基础上加的,注意的是拿测试集进行测试的时候需要eval()一下:
net_mnist.eval()
total = 0
correct = 0
for batch_x, batch_y in test_loader:
batch_x = batch_x.view(-1, 28*28)
x = net_mnist(batch_x)
_, prediction = torch.max(x, 1)
total += batch_y.size(0)
correct += (prediction == batch_y).sum()
print('Accuracy=%.2f' % (100 * correct / total))
网络结构为:
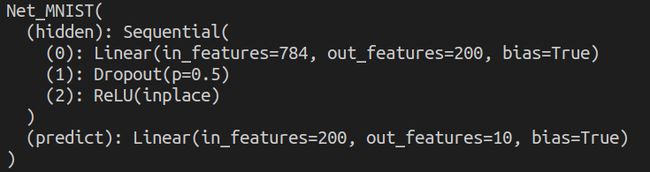
结果如下:

结果一样的(其实我觉得之前也没有过拟合。。。)
Step6
主要用来换一下优化器之类的
先前用的是SGD,试一下Adam
修改:
optimizer = torch.optim.Adam(net_mnist.parameters(), lr = 0.005, betas= (0.9, 0.99))
结果是:


提高了1%
再试一下Momentum
修改:
optimizer = torch.optim.SGD(net_mnist.parameters(), lr = 0.005, momentum= 0.8)
Momentum用的也是SGD,但后面多了个参数
结果是:


也是97%,并且这次前二十个都识别对了。。。
最后试一下RMSprop
修改:
optimizer = torch.optim.RMSprop(net_mnist.parameters(), lr = 0.005, alpha= 0.9)
结果是:


就目前来看,RMSprop识别的正确的个数多一丢丢,但也差不太多。。。反正都比SGD的效果要好
其实这些优化器后面的参数都是能改的,不过我没具体尝试过了
step6h之后,我尝试用RMSprop优化器并多加了三层看看效果,结果如下:
这是网络结构:

正确率如下:
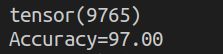
个数还没有三层的多
Step7
搭建CNN神经网络,添加卷积层和池化层
修改部分如下:
self.layer = nn.Sequential(
nn.Conv2d(),
nn.ReLU(),
nn.MaxPool2d(),
)
Conv2d为卷积层,激活函数之后,MaxPool2d为池化层
Conv2d:
nn.Conv2d(
in_channels= 1, 输入进来的维度
out_channels= 16, 输出后的维度
kernel_size= 5, 核大小
stride= 1, 跳度
padding= 2, 图片最外围扩大(以0为像素扩大)
),
MaxPool2d:
nn.MaxPool2d(
kernel_size = 2
)
卷积层还有一种AvgPool2d,它是选取kernel_size的平均值,一般用MaxPool2d
最后forward中需要进行扩展、展平(将三维的数据展平成二维的数据)的操作:
x = x.view(x.size(0), -1)
层结构如下:
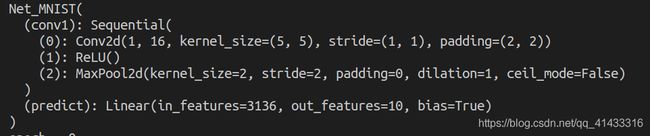
结果如下:

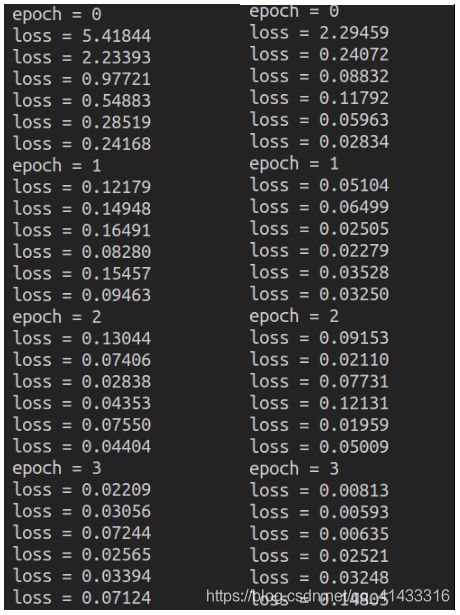
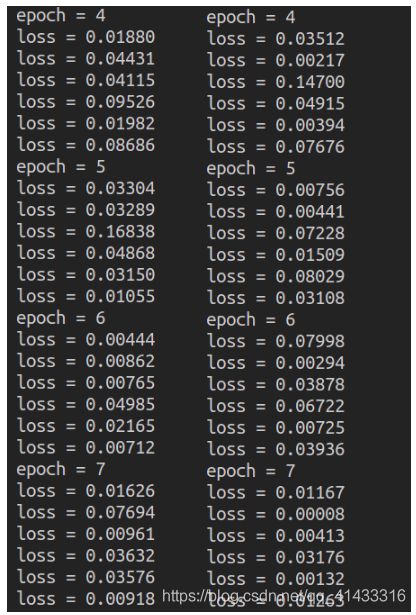
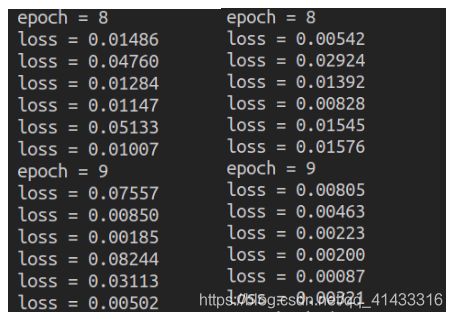
将中间训练中返回的loss值与之前三层全连接神经网络的拿来比较,其实可以看到一层的卷积池化比三层的全连接网络效果好很多
左边是全连接的loss值,右边是卷积加池化的
两层卷积池化:
结构:
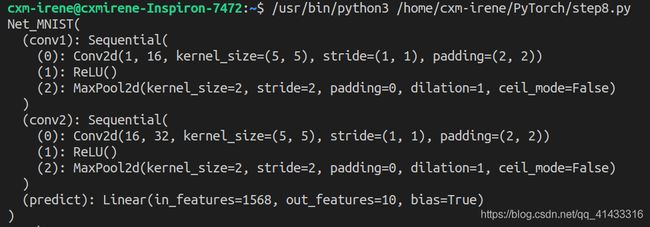
结果如下:

最后三次迭代的loss值如下:
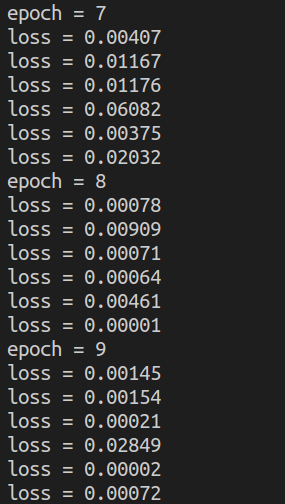
比之前小了一个小数点
再加一层:
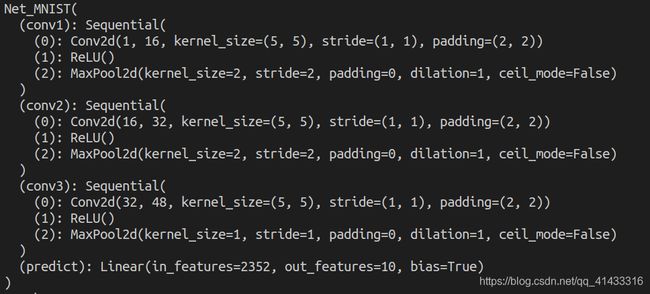
结果:

估计是过拟合了,最后的loss值越来越大
还有一个就是发现,卷积池化的计算速度会比单纯的全连接慢很多,可以用GPU用来加速,但我没有
两次操作加上一层隐藏层的批标准化
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels= 1,
out_channels= 16,
kernel_size= 5,
stride= 1,
padding= 2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size= 2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels= 16,
out_channels= 32,
kernel_size= 5,
stride= 1,
padding= 2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size= 2),
)
self.hidden = nn.Sequential(nn.Linear(32 * 7 * 7, n_hidden), nn.BatchNorm1d(n_hidden), nn.ReLU(True))
self.predict = nn.Linear(n_hidden, 10)

最后四层loss和最后结果
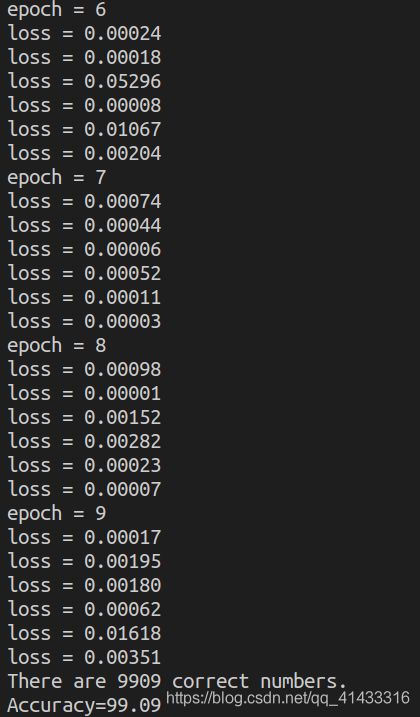
虽然也还可以,但是多加的这个隐藏层带来的效果不如没有的,从那个loss值的变化可以看到,最后一次迭代里其loss值反而变得比之前大了,大概是在第7到8次迭代的里面效果好一点,将epoch改成8,同时把batch_size改小一点,改成50试试看
结果差不多:
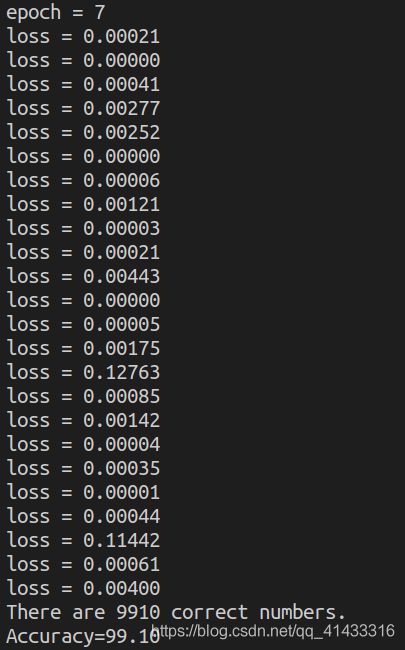
最后附上正确率最高的一次的代码:
import torch
import torch.nn as nn
import torch.utils.data as data
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
num_epoch = 10
BATCH_SIZE = 100
#MNIST数据集加载
train_dataset = datasets.MNIST(
root= '/home/cxm-irene/mnist',
train= True,
transform= transforms.ToTensor(),
download= False
)
train_loader = data.DataLoader(
dataset= train_dataset,
batch_size= BATCH_SIZE,
shuffle= True
)
test_dataset = datasets.MNIST(
root= '/home/cxm-irene/mnist',
train= False,
transform= transforms.ToTensor(),
download= False
)
test_loader = data.DataLoader(
dataset= test_dataset,
batch_size= BATCH_SIZE,
shuffle= True
)
test_x = torch.unsqueeze(test_dataset.test_data, dim=1).type(torch.FloatTensor)
test_y = test_dataset.test_labels
#搭建网络
class Net_MNIST(torch.nn.Module):
def __init__(self):
super(Net_MNIST, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels= 1,
out_channels= 16,
kernel_size= 5,
stride= 1,
padding= 2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size= 2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels= 16,
out_channels= 32,
kernel_size= 5,
stride= 1,
padding= 2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size= 2),
)
self.predict = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
#x = self.hidden(x)
x = self.predict(x)
return x
#hidden_layer = 100
#定义网络
net_mnist = Net_MNIST()
print(net_mnist)
#进行优化
optimizer = torch.optim.RMSprop(net_mnist.parameters(), lr = 0.005, alpha= 0.9)
loss_function = nn.CrossEntropyLoss()
for epoch in range(num_epoch):
print('epoch = %d' % epoch)
for i, (batch_x, batch_y) in enumerate(train_loader):
x = net_mnist(batch_x)
loss = loss_function(x, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print('loss = %.5f' % loss)
#对测试集的评估
total = 0
correct = 0
for batch_x, batch_y in test_loader:
x = net_mnist(batch_x)
_, prediction = torch.max(x, 1)
total += batch_y.size(0)
correct += (prediction == batch_y).sum()
print('There are ' + str(correct.item()) + ' correct numbers.')
print('Accuracy=%.2f' % (100.00 * correct.item() / total))