Pytorch实现GoogLeNet解决各类数据集(cifar10/mnist/imagenet)分类
有一段时间没有更新了,这次我给大家带来的是大名鼎鼎的GoogleNet模型。也可以称为Inception v3模型。参考了源代码,写出了可读性与性能更优的模型,在模型上有些许微调,输入的图片大小是224 x 224 x 3.!!! 图片大小可以任意调节,甚至用来训练CIFAR10也可以。本文先放出代码。
完整代码点这里
)
import torch
from torch import nn
NUM_CLASSES = 10
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Inception(nn.Module):
def __init__(self, in_channel, n1_1, n3x3red, n3x3, n5x5red, n5x5, pool_plane):
super(Inception, self).__init__()
# first line
self.branch1x1 = BasicConv2d(in_channel, n1_1, kernel_size=1)
# second line
self.branch3x3 = nn.Sequential(
BasicConv2d(in_channel, n3x3red, kernel_size=1),
BasicConv2d(n3x3red, n3x3, kernel_size=3, padding=1)
)
# third line
self.branch5x5 = nn.Sequential(
BasicConv2d(in_channel, n5x5red, kernel_size=1),
BasicConv2d(n5x5red, n5x5, kernel_size=5, padding=2)
)
# fourth line
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
BasicConv2d(in_channel, pool_plane, kernel_size=1)
)
def forward(self, x):
y1 = self.branch1x1(x)
y2 = self.branch3x3(x)
y3 = self.branch5x5(x)
y4 = self.branch_pool(x)
output = torch.cat([y1, y2, y3, y4], 1)
return output
class GoogLeNet(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super(GoogLeNet, self).__init__()
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.max_pool1 = nn.MaxPool2d(3, stride=2)
self.conv2 = BasicConv2d(64, 192, kernel_size=3, stride=1, padding=1)
self.max_pool2 = nn.MaxPool2d(3, stride=2)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.max_pool3 = nn.MaxPool2d(3, stride=2)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.max_pool4 = nn.MaxPool2d(3, stride=2)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avg_pool = nn.AvgPool2d(7)
self.dropout = nn.Dropout(0.4)
self.classifier = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.max_pool3(x)
x = self.a4(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
x = self.e4(x)
x = self.max_pool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avg_pool(x)
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
读者可以参照以下模型来进行研究
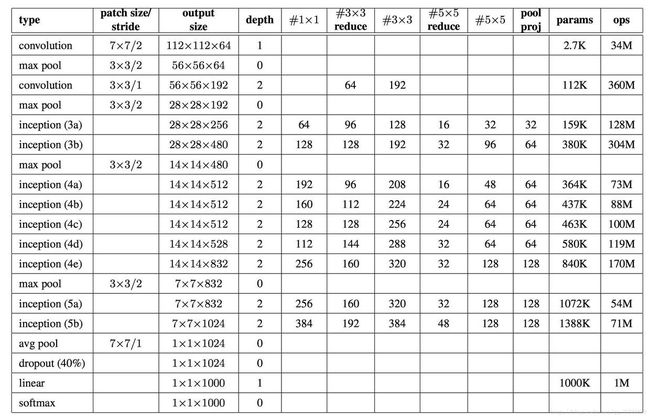
上图为GoogLeNet的网络框图细节,其中“#3x3 reduce”,“#5x5 reduce”代表在3x3,5x5卷积操作之前使用1x1卷积的数量。输入图像为224x224x3,且都进行了零均值化的预处理操作,所有降维层也都是用了ReLU非线性激活函数。

如上图用到了辅助分类器,Inception Net有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Net的训练很有裨益。
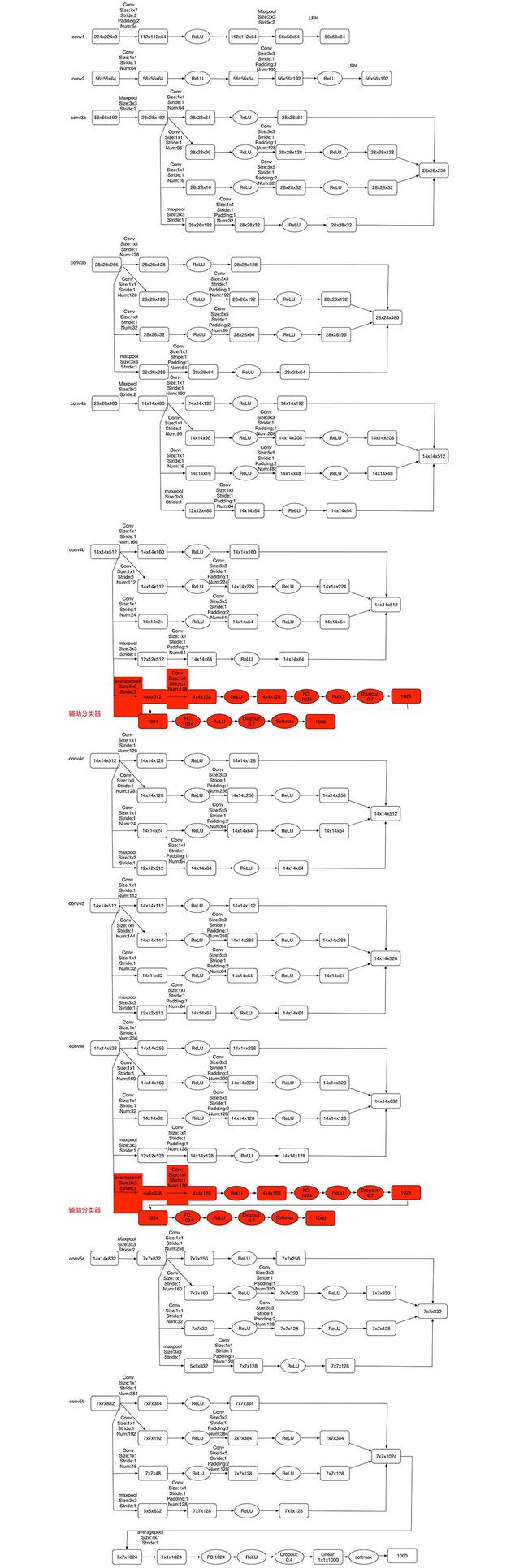
文章引用于 GoogLeNet 论文解读
编辑 Lornatang
校准 Lornatang