使用Keras构建自动编码器来进行信用卡欺诈检测
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Venelin Valkov
编译:ronghuaiyang
自动编码器来进行欺诈检测?是不是很神奇,一起来看看吧!
信用卡交易中的异常检测是如何工作的?
这是星期天的早晨,很安静,你醒来时脸上带着灿烂的微笑。今天将是伟大的一天!除非你的电话响了,而且是“国际”的。你慢慢地拿起它,听到一些非常奇怪的声音—“你好,我是米歇尔。”哦,抱歉。我是米歇尔,您的私人银行代理人。”瑞士来的人在这个时候给你打电话,怎么会这么急呢?“你是否授权以3,358.65美元的价格购买100份暗黑破坏神3?”你马上就开始想办法向你爱的人解释你为什么要这么做。“不,我没有!”米歇尔的回答很快,而且切中要害—“谢谢,我们正在做这件事。”唷,好险啊!但是米歇尔怎么知道这笔交易是可疑的呢?毕竟,上周你确实从同一个银行账户订购了10部新智能手机—米歇尔当时没有打电话。

根据《尼尔森报告》, 2015年全球年度欺诈损失达到218亿美元。如果你是个骗子,你可能会觉得很幸运。同年,美国每100美元中约有12美分被盗。我们的朋友Michele可能有一个严重的问题要解决。
在本系列的这一部分中,我们将以无监督(或半监督)方式训练一个自动编码器神经网络(在Keras中实现),用于信用卡交易数据中的异常检测。训练后的模型将在预先标记和匿名的数据集上进行评估。
源码和预训练模型在这里:https://github.com/curiousily/Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras
设置
我们将使用TensorFlow 1.2和Keras 2.0.4。让我们开始:
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
from scipy import stats
import tensorflow as tf
import seaborn as sns
from pylab import rcParams
from sklearn.model_selection import train_test_split
from keras.models import Model, load_model
from keras.layers import Input, Dense
from keras.callbacks import ModelCheckpoint, TensorBoard
from keras import regularizers
%matplotlib inline
sns.set(style='whitegrid', palette='muted', font_scale=1.5)
rcParams['figure.figsize'] = 14, 8
RANDOM_SEED = 42
LABELS = ["Normal", "Fraud"]加载数据
我们将要使用的数据集可以从Kaggle下载。它包含了两天内发生的信用卡交易数据,284,807笔交易中有492笔是欺诈行为。
数据集中的所有变量都是数值的。由于隐私原因,数据已使用PCA转换。没有改变的两个特征是时间和数量。Time包含从每个事务到数据集中第一个事务之间经过的秒数。
df = pd.read_csv("data/creditcard.csv")探索
df.shape> (284807,31)
31列,其中2列是时间和数量。其余部分是PCA转换的输出。让我们检查缺失的值:
df.isnull().values.any()> False
count_classes = pd.value_counts(df['Class'], sort = True)
count_classes.plot(kind = 'bar', rot=0)
plt.title("Transaction class distribution")
plt.xticks(range(2), LABELS)
plt.xlabel("Class")
plt.ylabel("Frequency");
我们手头有一个高度不平衡的数据集。正常交易大大超过了欺诈交易。让我们看看这两种类型的事务:
frauds = df[df.Class == 1]
normal = df[df.Class == 0]
frauds.shape> (492,31)
normal.shape> (284315,31)
在不同的事务类中使用的金额有多大的不同?
frauds.Amount.describe()>
count 492.000000
mean 122.211321
std 256.683288
min 0.000000
25% 1.000000
50% 9.250000
75% 105.890000
max 2125.870000
Name: Amount, dtype: float64>
normal.Amount.describe()>
count 284315.000000
mean 88.291022
std 250.105092
min 0.000000
25% 5.650000
50% 22.000000
75% 77.050000
max 25691.160000
Name: Amount, dtype: float64让我们有一个更图形化的表示:
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True)
f.suptitle('Amount per transaction by class')
bins = 50
ax1.hist(frauds.Amount, bins = bins)
ax1.set_title('Fraud')
ax2.hist(normal.Amount, bins = bins)
ax2.set_title('Normal')
plt.xlabel('Amount ($)')
plt.ylabel('Number of Transactions')
plt.xlim((0, 20000))
plt.yscale('log')
plt.show();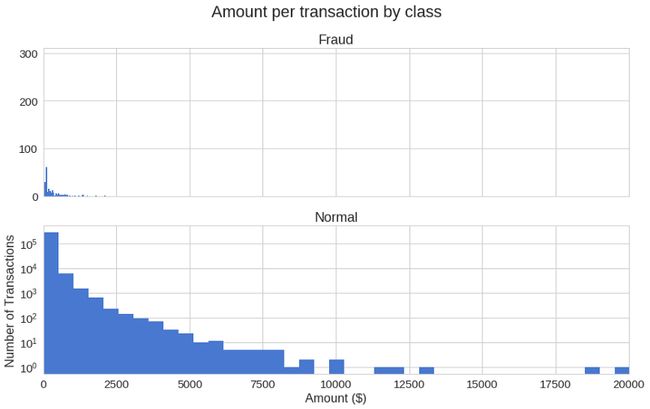
欺诈性交易在一定时间内是否更频繁发生?
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True)
f.suptitle('Time of transaction vs Amount by class')
ax1.scatter(frauds.Time, frauds.Amount)
ax1.set_title('Fraud')
ax2.scatter(normal.Time, normal.Amount)
ax2.set_title('Normal')
plt.xlabel('Time (in Seconds)')
plt.ylabel('Amount')
plt.show()
似乎交易的时间并不重要。
自动编码器
自动编码器一开始看起来很奇怪。这些模型的工作是预测输入,给定相同的输入。令人费解?对我来说绝对是,第一次听到它。
更具体地说,让我们来看看自动编码神经网络。这个自动编码器试图学习近似以下恒等函数:
![]()
虽然刚开始这听起来很简单,但重要的是要注意,我们希望学习数据的压缩表示,从而找到结构。这可以通过限制模型中隐藏单元的数量来实现。这些类型的自动编码器称为“不完全”。
下面是自动编码器可能学到的东西的可视化表示:

重建误差
我们优化了我们的自动编码器模型的参数,使一种特殊的误差-重建误差最小。在实践中,通常使用传统的平方误差:
![]()
准备数据
首先,让我们删除时间列(不打算使用它),并使用scikit的标准缩放来计算数量。定标器减去平均值并将值缩放到单位方差:
from sklearn.preprocessing import StandardScaler
data = df.drop(['Time'], axis=1)
data['Amount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))训练我们的自动编码器会和我们习惯的有点不同。假设你手头有一个包含许多非欺诈事务的数据集。你希望检测新事务上的任何异常。我们将仅通过在正常事务上训练我们的模型来创建这种情况。在测试集中保留正确的类将为我们提供一种评估模型性能的方法。我们将保留20%的数据用于测试:
X_train, X_test = train_test_split(data, test_size=0.2, random_state=RANDOM_SEED)
X_train = X_train[X_train.Class == 0]
X_train = X_train.drop(['Class'], axis=1)
y_test = X_test['Class']
X_test = X_test.drop(['Class'], axis=1)
X_train = X_train.values
X_test = X_test.values
X_train.shape> (227451,29)
构建模型
我们的自动编码器使用4个全连接的层分别连接14,7,7和29个神经元。前两层用于编码器,后两层用于解码器。此外,在训练中使用L1正则化:
input_dim = X_train.shape[1]
encoding_dim = 14
input_layer = Input(shape=(input_dim, ))
encoder = Dense(encoding_dim, activation="tanh",
activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoder = Dense(int(encoding_dim / 2), activation="relu")(encoder)
decoder = Dense(int(encoding_dim / 2), activation='tanh')(encoder)
decoder = Dense(input_dim, activation='relu')(decoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)让我们用32个样本的批大小训练100个epoch的模型,并将性能最好的模型保存到一个文件中。Keras提供的模型检查点对于这类任务非常方便。此外,训练进度将以TensorBoard能够理解的格式导出。
nb_epoch = 100
batch_size = 32
autoencoder.compile(optimizer='adam',
loss='mean_squared_error',
metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath="model.h5",
verbose=0,
save_best_only=True)
tensorboard = TensorBoard(log_dir='./logs',
histogram_freq=0,
write_graph=True,
write_images=True)
history = autoencoder.fit(X_train, X_train,
epochs=nb_epoch,
batch_size=batch_size,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1,
callbacks=[checkpointer, tensorboard]).history并加载保存的模型(只是为了检查它是否工作):
autoencoder = load_model('model.h5')评估
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right');
我们的训练数据和测试数据的重构误差似乎很好地收敛。够低吗?让我们仔细看看误差分布:
predictions = autoencoder.predict(X_test)
mse = np.mean(np.power(X_test - predictions, 2), axis=1)
error_df = pd.DataFrame({'reconstruction_error': mse,
'true_class': y_test})
error_df.describe()
没有欺诈的重建误差
fig = plt.figure()
ax = fig.add_subplot(111)
normal_error_df = error_df[(error_df['true_class']== 0) & (error_df['reconstruction_error'] < 10)]
_ = ax.hist(normal_error_df.reconstruction_error.values, bins=10)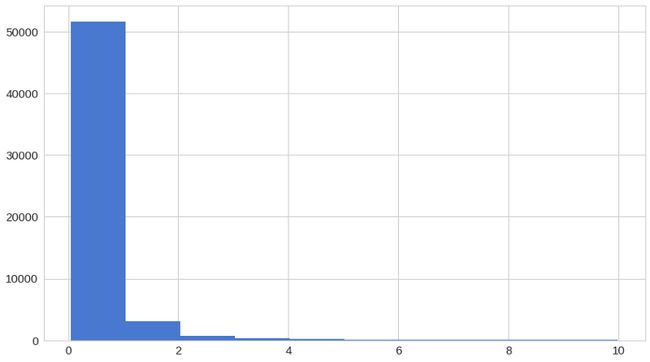
有欺诈的重建误差
fig = plt.figure()
ax = fig.add_subplot(111)
fraud_error_df = error_df[error_df['true_class'] == 1]
_ = ax.hist(fraud_error_df.reconstruction_error.values, bins=10)
from sklearn.metrics import (confusion_matrix, precision_recall_curve, auc,
roc_curve, recall_score, classification_report, f1_score,
precision_recall_fscore_support)ROC曲线是了解二值分类器性能的非常有用的工具。然而,我们的情况有点不同寻常。我们有一个非常不平衡的数据集。尽管如此,让我们看看我们的ROC曲线:
fpr, tpr, thresholds = roc_curve(error_df.true_class, error_df.reconstruction_error)
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, label='AUC = %0.4f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.001, 1])
plt.ylim([0, 1.001])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show();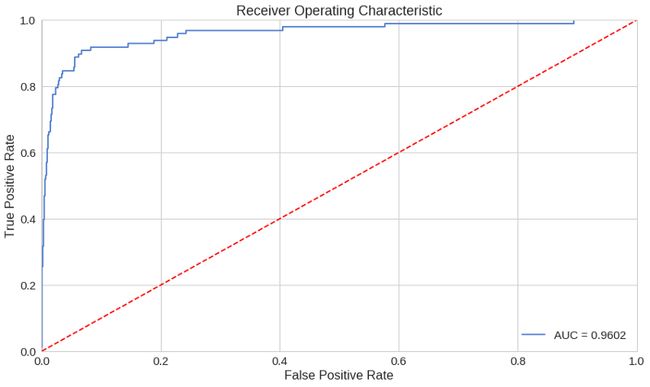
ROC曲线显示了不同阈值下的真阳性率与假阳性率。基本上,我们希望蓝线尽可能靠近左上角。虽然我们的结果看起来很好,但我们必须记住数据集的性质。ROC看起来对我们不是很有用。
精确率vs召回率
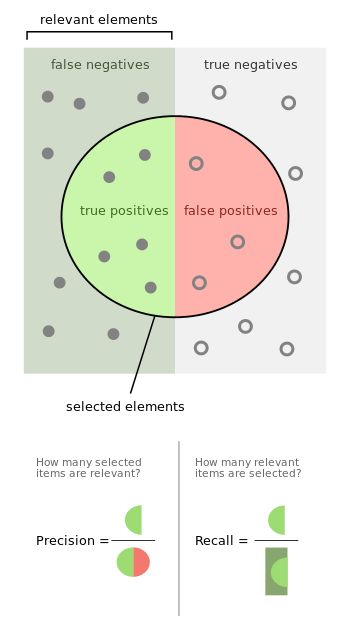
精确率和召回率定义如下:


让我们以信息检索为例,以便更好地理解什么是精确度和召回率。精确度衡量所得结果的相关性。另一方面,Recall度量返回多少相关结果。两个值都可以取0到1之间的值。你想要的是一个两个值都等于1的系统。
让我们从信息检索返回到我们的示例。高召回率低精确率意味着很多结果,其中大多数结果的相关度较低或不相关。当精确度高而召回率低时,我们得到的结果正好相反—返回的结果很少具有很高的相关性。理想情况下,你需要高精确度和高召回率—许多结果与之高度相关。
precision, recall, th = precision_recall_curve(error_df.true_class, error_df.reconstruction_error)
plt.plot(recall, precision, 'b', label='Precision-Recall curve')
plt.title('Recall vs Precision')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.show()
曲线下的高区域表示高召回率和高精度,其中高精度与低假阳性率有关,高召回率与低假阴性率有关。这两种方法的得分都很高,这表明分类器返回的结果是准确的(高精确度),同时返回的大部分结果都是正面的(高召回率)。
plt.plot(th, precision[1:], 'b', label='Threshold-Precision curve')
plt.title('Precision for different threshold values')
plt.xlabel('Threshold')
plt.ylabel('Precision')
plt.show()
你可以看到随着重建误差的增加我们的精度也提高了。让我们来看看这次召回率:
plt.plot(th, recall[1:], 'b', label='Threshold-Recall curve')
plt.title('Recall for different threshold values')
plt.xlabel('Reconstruction error')
plt.ylabel('Recall')
plt.show()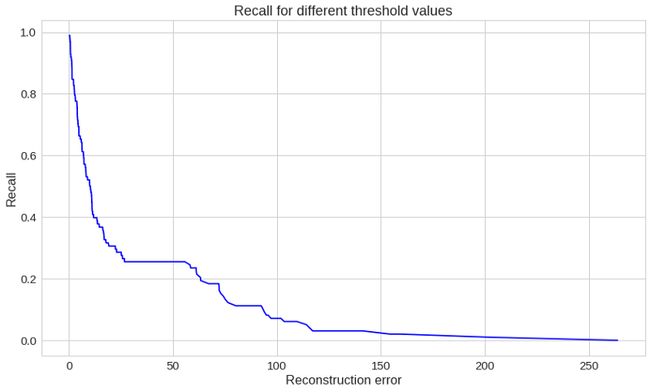
这里的情况正好相反。重构误差越大,召回率越小。
预测
这次我们的模型有点不同。它不知道如何预测新值。但我们不需要。为了预测一个新的/不可见的事务是正常的还是欺诈的,我们将从事务数据本身计算重构误差。如果误差大于预定义的阈值,我们将把它标记为欺诈(因为我们的模型在正常事务上的错误应该很低)。让我们选择这个值:
threshold = 2.9看看我们如何划分这两种类型的交易:
groups = error_df.groupby('true_class')
fig, ax = plt.subplots()
for name, group in groups:
ax.plot(group.index, group.reconstruction_error, marker='o', ms=3.5, linestyle='',
label= "Fraud" if name == 1 else "Normal")
ax.hlines(threshold, ax.get_xlim()[0], ax.get_xlim()[1], colors="r", zorder=100, label='Threshold')
ax.legend()
plt.title("Reconstruction error for different classes")
plt.ylabel("Reconstruction error")
plt.xlabel("Data point index")
plt.show();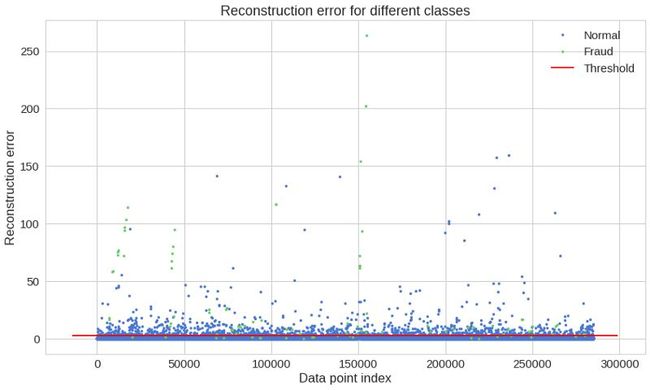
我知道,那个图表可能有点骗人。让我们看看混淆矩阵:
y_pred = [1 if e > threshold else 0 for e in error_df.reconstruction_error.values]
conf_matrix = confusion_matrix(error_df.true_class, y_pred)
plt.figure(figsize=(12, 12))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()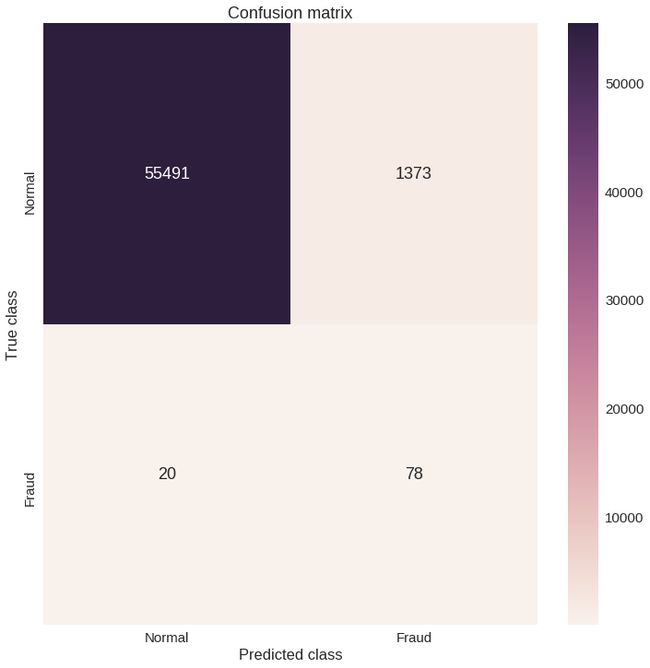
我们的模型似乎抓住了许多欺诈案件。当然,这里有一个陷阱(看到我在那里做了什么吗?)被归为欺诈的正常交易数量确实很高。这真的是个问题吗?很可能是这样。你可能想要增加或减少阈值,这取决于问题。这取决于你。
结论
我们在Keras中创建了一个非常简单的深层自动编码器,它可以重建非欺诈事务的外观。一开始,我有点怀疑这整件事是否会成功,但最终还是成功了。考虑一下,我们给一个模型提供了很多一个类的例子(普通事务),它(在一定程度上)学会了如何区分新的例子是否属于同一个类。这不是很酷吗?不过,我们的数据集有点神奇。我们真的不知道最初的功能是什么样子的。
Keras为我们提供了非常干净和易于使用的API来构建一个非平凡的深层自动编码器。你可以搜索TensorFlow实现,并亲自查看你需要多少样板文件才能训练一个。你能把相似的模型应用到不同的问题上吗?
 —
END—
—
END—
英文原文:https://medium.com/@curiousily/credit-card-fraud-detection-using-autoencoders-in-keras-tensorflow-for-hackers-part-vii-20e0c85301bd

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!