【今日CS 视觉论文速览】10 Jan 2019
今日CS.CV计算机视觉论文速览
Thu, 10 Jan 2019
Totally 34 papers

Interesting:
- shape2program,基于几何结构的高层理解,开发出了一套可以抽取三维形状低级与高级特征的程序描述语言,不仅可以从原始形状学习出对应的三维形貌表示程序描述,同时还可以执行这一程序重建出三维形状。(from MIT 普林斯顿)

程序描述生成与重建过程:

绘制过程的实例程序:

自监督进行抽取、理解和重建过程:

重建过程的结果示例:

ref:http://shape2prog.csail.mit.edu/
github:https://github.com/HobbitLong/shape2prog
dataset:ShapeNet
- 从大规模三维点云中进行直线段检测,与传统先抽取3D边界点并连接匹配直线的方法不同,这种方法基于三维点云分割和二维直线检测来实现。首先通过区域增长和融合的方法将点云分割为三维平面,将点投影到对应平面中就形成了二维图像的形式。随后利用二维包络检测和最小二乘等方法进行线段分割,并将结果重投影到三维空间中去。(from 俄亥俄州立)
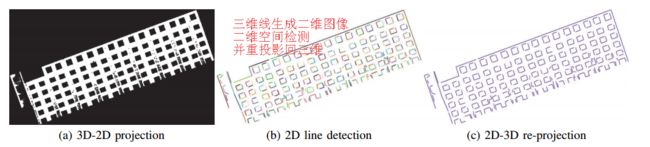
一些检测出的结果:

Github:https://github.com/xiaohulugo/3DLineDetection.
dataset:Semantic3D Shape Repertory
ref:
http://www.semantic3d.net/
http://visionair.ge.imati.cnr.it/ontologies/shapes/
https://github.com/xiaohulugo/3DLineDetection
http://www.libe57.org/data.html
- 单张图片的逆渲染过程,通过单张图片实现场景的逆渲染问题,从输入RGB图像中预测出场景的表面法向量、反射率图和光泽分布,并重建出场景图像。(from 英伟达)
下图是网络架构:

效果如下所示:

文章提出的数据集:

数据集:
SUNCG-PBR
PBRs dataset
SUNCG
ref:
SIRFS:Shape, Illumination, and Reflectance from Shading
ref:Point Cloud Data Distribution and Processing
- MSR,多尺度多形状的文字检测模型,与先前预测四边形不同的是这一工作通过预测文字密集区域的边界点来进行检测。(from 南洋理工)
通过多尺度网络与文本区域回归来进行文字区域边界点预测:
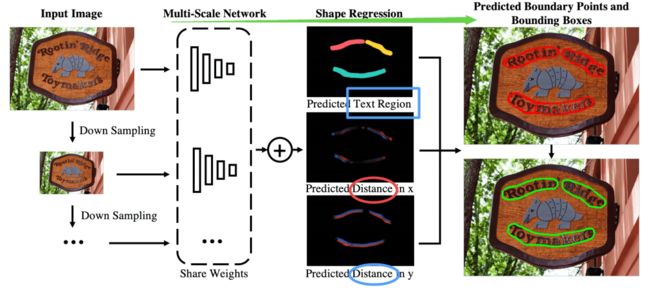

一些结果:
数据集:
MSRA-TD500
SynthText
CTW1500
Total-Text
ICDAR2017
tc11
ref:
curve detect
text-snake
text-box
非规则文本数据
SynthText in the Wild Dataset
- 基于流型学习的三维形状描述,提出了流型空间上的基于拉普拉斯本征值图的尺度不变特征描述子。

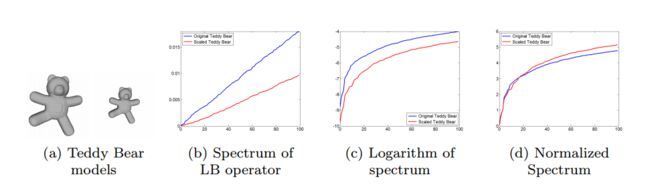
dataset:TOSCA 高精度非刚体三维模型数据集
- GIF2Video,改善GIF动图的颜色质量。GIF格式的动图通常受到生成过程中帧采样、颜色量化和抖动过程的影响。针对这些方面提出了基于学习架构来纠正颜色,并利用了SuperSlomo网络来说实现时域插值。(from 石溪分校)
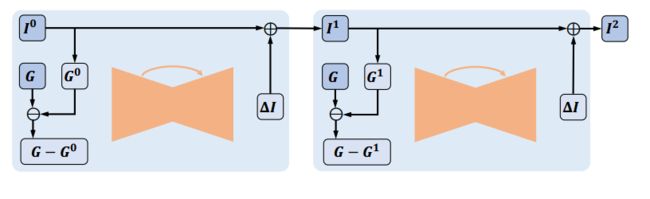
去量化过程:
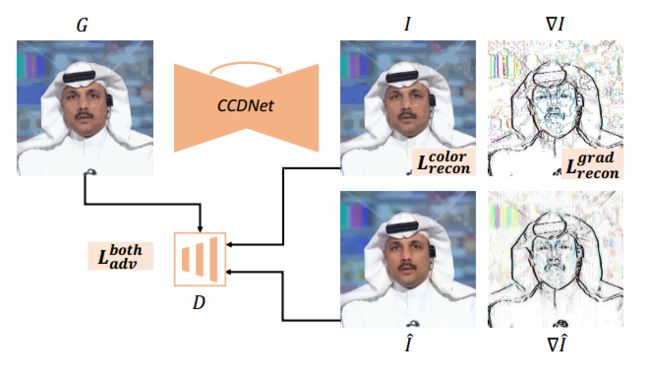
处理过程:

数据集:GIF-Faces GIF-Moments,FaceForensics dataset Video2GIF
ref:https://www.w3.org/Graphics/GIF/spec-gif89a.txt
Video2GIF: Automatic Generation of Animated GIFs from Video
- 基于K均值和主动学习的屏幕截图聚类算法,屏幕截图对了解用户行为很有用,但由于隐私的问题获取截图内容标记成本高昂。研究人员利用无监督和半监督的方法,提出了一种视觉信息和文本特征的联合表示,实现了数据的聚类和标记。(from 宾夕法尼亚大学)
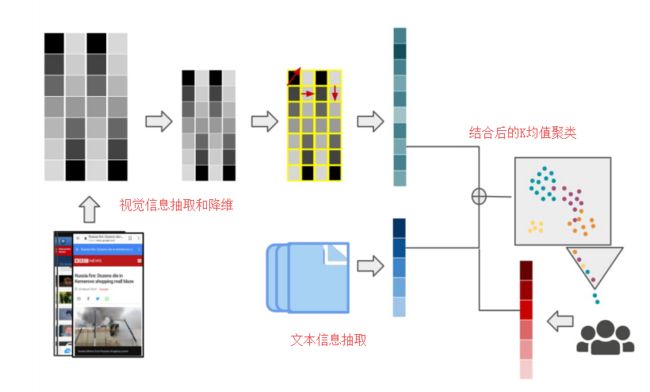
ref:
https://github.com/google/active-learning
http://screenomics.stanford.edu/
- 自动化小行星检测, 还有一篇基于图像的自动检测NEARBY Platform,(from 克卢日-纳波卡技术大学 罗马尼亚)

Daily Computer Vision Papers
[1] Title: Learning to Infer and Execute 3D Shape Programs
Authors:Yonglong Tian, Andrew Luo, Xingyuan Sun, Kevin Ellis, William T. Freeman, Joshua B. Tenenbaum, Jiajun Wu
[2] Title: Adaptive Feature Processing for Robust Human Activity Recognition on a Novel Multi-Modal Dataset
Authors:Mirco Moencks, Varuna De Silva, Jamie Roche, Ahmet Kondoz
[3] Title: GIF2Video: Color Dequantization and Temporal Interpolation of GIF images
Authors:Yang Wang, Haibin Huang, Chuan Wang, Tong He, Jue Wang, Minh Hoai
[4] Title: Learnable Manifold Alignment (LeMA) : A Semi-supervised Cross-modality Learning Framework for Land Cover and Land Use Classification
Authors:Danfeng Hong, Naoto Yokoya, Nan Ge, Jocelyn Chanussot, Xiao Xiang Zhu
[5] Title: The Use of Mutual Coherence to Prove ℓ 1 / ℓ 0 \ell^1/\ell^0 ℓ1/ℓ0-Equivalence in Classification Problems
Authors:Chelsea Weaver, Naoki Saito
[6] Title: Guess What’s on my Screen? Clustering Smartphone Screenshots with Active Learning
Authors:Agnese Chiatti, Dolzodmaa Davaasuren, Nilam Ram, Prasenjit Mitra
[7] Title: Image Recognition of Tea Leaf Diseases Based on Convolutional Neural Network
Authors:Xiaoxiao Sun, Shaomin Mu, Yongyu Xu, Zhihao Cao, Tingting Su
[8] Title: Low-Cost Transfer Learning of Face Tasks
Authors:Thrupthi Ann John, Isha Dua, Vineeth N Balasubramanian, C. V. Jawahar
[9] Title: Deep Semantic Multimodal Hashing Network for Scalable Multimedia Retrieval
Authors:Lu Jin, Jinhui Tang, Zechao Li, Guo-Jun Qi, Fu Xiao
[10] Title: The Cross-Modality Disparity Problem in Multispectral Pedestrian Detection
Authors:Lu Zhang, Zhiyong Liu, Xiangyu Chen, Xu Yang
[11] Title: MOANA: An Online Learned Adaptive Appearance Model for Robust Multiple Object Tracking in 3D
Authors:Zheng Tang, Jenq-Neng Hwang
[12] Title: D 3 {}^3 3TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation
Authors:Chien-Yi Chang, De-An Huang, Yanan Sui, Li Fei-Fei, Juan Carlos Niebles
[13] Title: MSR: Multi-Scale Shape Regression for Scene Text Detection
Authors:Chuhui Xue, Shijian Lu, Wei Zhang
[14] Title: Manipulation-skill Assessment from Videos with Spatial Attention Network
Authors:Zhenqiang Li, Yifei Huang, Minjie Cai, Yoichi Sato
[15] Title: Interactive Image Segmentation using Label Propagation through Complex Networks
Authors:Fabricio Aparecido Breve
[16] Title: Neural RGB->D Sensing: Depth and Uncertainty from a Video Camera
Authors:Chao Liu, Jinwei Gu, Kihwan Kim, Srinivasa Narasimhan, Jan Kautz
[17] Title: Thinking Outside the Pool: Active Training Image Creation for Relative Attributes
Authors:Aron Yu, Kristen Grauman
[18] Title: Collaborative Execution of Deep Neural Networks on Internet of Things Devices
Authors:Ramyad Hadidi, Jiashen Cao, Micheal S. Ryoo, Hyesoon Kim
[19] Title: Fast 3D Line Segment Detection From Unorganized Point Cloud
Authors:Xiaohu Lu, Yahui Liu, Kai Li
[20] Title: A Spatial-temporal 3D Human Pose Reconstruction Framework
Authors:Xuan Thanh Nguyen, Thi Duyen Ngo, Thanh Ha Le
[21] Title: Viewpoint Invariant Change Captioning
Authors:Dong Huk Park, Trevor Darrell, Anna Rohrbach
[22] Title: Multi-stream CNN based Video Semantic Segmentation for Automated Driving
Authors:Ganesh Sistu, Sumanth Chennupati, Senthil Yogamani
[23] Title: Grey matter sublayer thickness estimation in themouse cerebellum
Authors:Da Ma, Manuel J. Cardoso, Maria A. Zuluaga, Marc Modat, Nick. Powell, Frances Wiseman, Victor Tybulewicz, Elizabeth Fisher, Mark. F. Lythgoe, Sebastien Ourselin
[24] Title: Neural Inverse Rendering of an Indoor Scene from a Single Image
Authors:Soumyadip Sengupta, Jinwei Gu, Kihwan Kim, Guilin Liu, David W. Jacobs, Jan Kautz
[25] Title: Face Recognition System
Authors:Yang Li, Sangwhan Cha
[26] Title: SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Authors:Jean Kossaifi, Robert Walecki, Yannis Panagakis, Jie Shen, Maximilian Schmitt, Fabien Ringeval, Jing Han, Vedhas Pandit, Bjorn Schuller, Kam Star, Elnar Hajiyev, Maja Pantic
[27] Title: Selective metamorphosis for growth modelling with applications to landmarks
Authors:Andreas Bock, Alexis Arnaudon, Colin Cotter
[28] Title: Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation
Authors:Al-Hussein A. El-Shafie, Mohamed Zaki, Serag El-Din Habib
[29] Title: UAV-GESTURE: A Dataset for UAV Control and Gesture Recognition
Authors:Asanka G Perera, Yee Wei Law, Javaan Chahl
[30] Title: NEARBY Platform: Algorithm for Automated Asteroids Detection in Astronomical Images
Authors:T. Stefanut, V. Bacu, C. Nandra, D. Balasz, D. Gorgan, O. Vaduvescu
[31] Title: Asteroids Detection Technique: Classic “Blink” An Automated Approch
Authors:D. Copandean, C. Nandra, D. Gorgan, O. Vaduvescu
[32] Title: Lattice Identification and Separation: Theory and Algorithm
Authors:Yuchen He, Sung Ha Kang
[33] Title: Combining nonparametric spatial context priors with nonparametric shape priors for dendritic spine segmentation in 2-phoyon microscopy images
Authors:Ertunc Erdil, Ali Ozgur Argunsah, Tolga Tasdizen, Devrim Unay, Mujdat Cetin
[34] Title: An Application of Manifold Learning in Global Shape Descriptors
Authors:Fereshteh S. Bashiri, Reihaneh Rostami, Peggy Peissig, Roshan M. D’Souza, Zeyun Yu
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com