PyramidBox:A Context-assisted Single Shot Face Detector(论文阅读笔记)
论文:PyramidBox: A Context-assisted Single Shot Face Detector
原文链接:https://arxiv.org/abs/1803.07737?context=cs
PyramidBox是2018年的人脸检测冠军方案
先上一个效果图,该图据报道有1000人,PyramidBox人脸检测器检测到了880张人脸,图片右侧的颜色条表示检测置信度,可以发现只有少数boxes(人脸)的置信度比较低。颜色越浅,置信度越低。
摘要
人脸检测的一个挑战是检测不受控制条件下小的,模糊的,和部分遮挡的人脸。本文提出了一个上下文辅助的single shot人脸检测器——PyramidBox,来解决人脸检测的难题。我们在下面三个部分改进了上下文信息的利用。1)设计了一种新的上下文anchor来监督由半监督方法学习到的高层上下文特征,我们把它叫做PyramidAnchors。2)提出了一种低层特征金字塔网络(LFPN)整合高层的语义信息和低层的面部特征,他可以使PyramidBox以single shot的方式预测所有尺度的人脸。3)我们引入了一个上下文敏感结构来增加预测网络的容量,以提高输出的最终准确性。PyramidBox在两个人脸检测基准数据集,FDDB和WIDER FACE上取得了state of the art的结果。
引言
如何利用上下文信息来检测人脸没有引起太多关注,但是对于很难检测的人脸,上下文信息扮演了一个很重要的角色。如图一所示,人脸在现实世界中不是独立出现的,通常有肩膀,身体提供丰富的上下文关联源以便被利用,尤其是当面部纹理因低分辨率,模糊和遮挡而无法区分时。我们通过引入一个新的上下文辅助网络框架来处理这些问题,这个框架可以充分利用上下文信号,如下面几个步骤所示。

第一,网络应该可以学习的特征不仅仅是人脸还包括上下文部分,例如头和身体。为了达到这个目标,需要额外的标记,并且应该设计与头和身体匹配的anchors。本文,我们利用一个半监督的方法来为人脸相关的上下分部分生成近似的标签和一系列anchor,我们把它叫做PyramidAnchors,可以很容易地添加到基于anchor的一般架构中。
第二,高层的上下文特征应该和低层的特征充分整合起来。易分和难分的人脸外观可能完全不同,这意味着不是所有的高层语义特征对小目标的检测是有帮助的。我们研究了FPN并把它改成了LFPN(低层特征金字塔网络)。
第三,预测分支网路应该充分利用联合特征。我们引入了一个更深,更宽的网络——上下文敏感预测模块(CPM)来接受目标人脸附近的上下文信息。同时我们为预测模块提出了一个max-in-out层来进一步改善分类网络的能力。
另外,我们提出一个训练策略叫做——Data-anchor-samling来调整训练数据集的分布。为了学习更多可表示的特征,hard-set样本的多样性非常重要,可以通过样本间的数据增强来获得。
本文的主要贡献包含以下五点:
1)提出了一种基于anchor的上下文辅助方法——pyramidAnchor,在为小,模糊和部分遮挡的人脸的上下文特征学习引入监督信息。
2)设计了一种低层特征金字塔网络LFPN来更好的整合上下文和人脸特征,该方法用single-shot的方式来处理不同尺度的人脸。
3)引入一个上下文敏感预测模块,该模块由一个混合网络结构和max-in-out层组成并重合并的特征中学习准去的位置和分类。
4)提出尺度感知的Data-anchor-sampling策略来改变训练样本的分布,从而更加关注较小的人脸。
5)在FDDB和WIDER FACER两个通用人脸检测基本数据集上取得了最好的性能。
相关工作
基于anchor的人脸检测器:
anchor是由faster rcnn首次提出,后来在two-stage和one-single-shot的目标检测器中广泛应用。基于anchor的目标检测器在近些年取得了很好的效果。FaceBox和S3FD等论文都使用了基于anchor的方法来改善人脸的检测。
尺度不变的人脸检测器:
为了改进人脸检测器处理不同尺度人脸的性能,许多state of the art的网络在同一框架中构造了不同的结构来检测各种尺寸的人脸。其中高层特征用于 检测较大的人脸,而低层特征用于检测较小的人脸。为了整合高层的语义特征和低层的高分辨率特征,FPN提出了一种自上而下的结构在所有尺度上使用高层的语义特征图。近些年,FPN风格的网络结构在目标检测和人脸识别的领域都取得了恨到的性能。
上下文辅助人脸检测器:
许多工作表明上下文信息对人脸检测非常重要,特别是对小的,模糊的,遮挡的人脸检测极其重要。CMS-RCNN利用faster RCNN检测不同尺度的人脸,SSH在每个预测模块上利用大滤波器对上下文信息进行建模。FAN提出了一种anchor层面的注意力机制,通过加强人脸区域的特征来检测模糊的人脸。
PyramidBox:
1、网络结构:
pyramidBOx网络结构继承了VGG16的backbone和S3FD中的anchor尺度设计。pyramidBOx可以等比间隔地生成不同层和anchors的特征图。在backbone中添加了低层FPN和一个上下文敏感测模块,上下文敏感预测模块从每个金字塔检测层中作为分支网络来得到最后的输出。关键在于,我们设计了一种新的金字塔anchor方法来为不同层的每张人脸生成一系列的anchor。网络结构的各部分细节如下:
尺度公平的backbone 层:我们采用基本的卷积层和S3FD中额外的卷积层作为我们的backbone 层,保留了VGG16中从conv1_1到pool5的层,然后把VGG16中的fc6和fc7转化为conv_fc层,并添加了更多的卷积层使网络更深。
低层特征金字塔层:为了改进人脸检测器处理不同尺度人脸的检测器性能,低层高分辨率特征非常重要。因此,许多state of the art工作在同样的框架中构造了不同的结构来检测不同尺度的人脸。其中高层特征用于检测较大的人脸,而低层特征用于检测较小的人脸。为了整合高层语义特征和低层更高分辨率的特征,FPN提出了自上而下的结构以在所有尺度上利用高层的语义信息。近些年,FPN风格的框架在人脸检测和目标检测方面都取得很多好的性能。
我们都知道,所有建立在FPN的工作都是从顶层开始的,但是具有争论的一点是,不是所有的高层特征对于小目标(人脸)的检测是有帮助的。第一,小的,模糊的和遮挡的人脸和较大的,清晰的,完整的人脸相比具有不同的纹理特征。所以直接把所有高层特征用来加强小的人脸的检测性能太过粗暴。第二,高层特征是从没有人脸纹理的区域提取的,可能引入噪声信息。例如,在pyramidBox的backbone层中顶部两层conv7_2和conv6_2的感受野分别是724和468。注意到输入训练图片的尺寸是640,这意味着顶部两层的包含太多的噪声纹理特征,因此他们对检测中等和小的人脸没有贡献。
 PyramidBox网络结构图
PyramidBox网络结构图
另外我们从中间层自上而下构建了低层特征金字塔网络(LFPN),它的感受野应该接近输入图片尺寸的一半。同样,每个LFPN block结构和FPN是一样的,细节见图三。


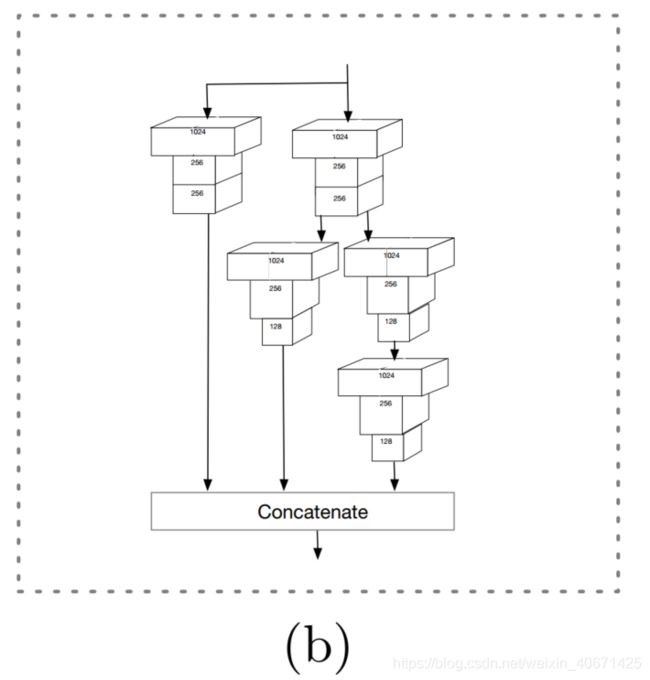
金字塔检测层:选择lfpn_2,lfpn_1,lfpn_0,conv_fc7,conv6_2和conv7_2作为检测层,对应的anchor size为16,32,64,128,256和512.其中lfpn_2,lfpn_1和lfpn_0是分别对应基于conv3_3,conv4_3和conv5_3的LFPN输出层。类似于SSD的方法,采用L2正则从新调整LFPN层的范数。
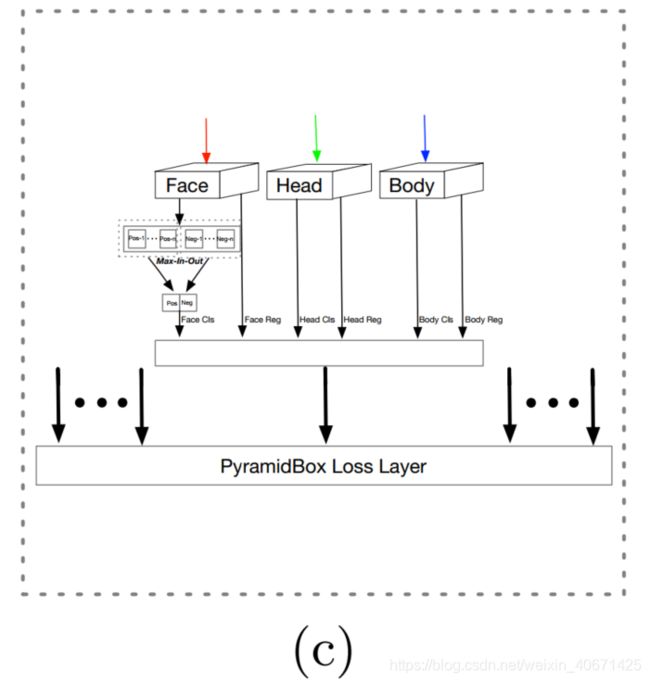
预测层:每个检测层后面接一个上下文敏感预测模块(CPM),CPM的输出用于监督金字塔anchors,这些anchors可以近似覆盖人脸,人头和身体区域。第 l 个CPM的输出尺寸是![]() ,其中
,其中  是对应特征图的尺寸,对所有的l=0,1,...,5通道尺寸 cl 等于20。这里,每个通道的特征分别用于人脸,人头和身体的分类与回归。其中人脸分类需要4个通道(cpl+cnl),cpl和cnl分别是前景和背景标签的max-in-out,满足下面公式。
是对应特征图的尺寸,对所有的l=0,1,...,5通道尺寸 cl 等于20。这里,每个通道的特征分别用于人脸,人头和身体的分类与回归。其中人脸分类需要4个通道(cpl+cnl),cpl和cnl分别是前景和背景标签的max-in-out,满足下面公式。
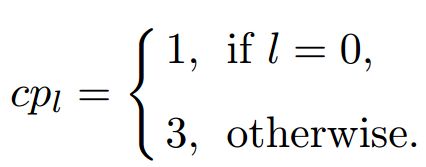
对于人头和身体的分类各需要两个通道,对每个人脸,人头和身体的定位需要4个通道。(20=4+2+2+4*3)
pyramidbox损失层:对于目标人脸,有一系列pyramid anchor同时监督分类和回归任务。我们设计了pyramidBox损失,分类采用softmax 损失回归采用平滑L1损失。
2,上下文敏感预测模块
预测模块:类似于SSD和YOLO的原始基于anchor的检测器,目标函数直接用于特征图的选择。MS-CNN中提出每个任务的子网络可以改善准确率。目前,SSH通过在顶层放置不同步长更宽的卷积预测模块增加了感受野。DSSD为每个预测模块增加了残差block。实际上SSH和DSSD分别使预测模块变得更深和更宽,因此预测模块可以获得更好的特征用来分类和定位。
受到 Inception-RenNet 的启发,很明显,可以采用更宽和更深的网络获取增益。我们设计了上下文敏感预测模块(CPM),图三(b)。我们用DSSD中无残差预测模块替换SSH中的上下文卷积模块。这样可以使CPM获得DSSD模块方法的所有优点,同时保留SSH中丰富的上下文模块信息。
Max-in-out:Maxout第一次由Goodfellow等人提出,最近,S3FD采用max-out背景标签来降低小负样本的假阳性。本文,我们在正样本和负样本中都采用这种策略,max-in-out定义如图三(c)所示。首先,对每个预测模块预测cp+cn的得分,然后选择最大的cp作为正得分。同样地,选择让cn的最大得分最为负得分。在实验中,第一个预测模块设置cp=1,cn=3,因为小anchor具有更复杂的背景,而对于其他的预测模块为了召回更多人脸,设置cp=3,cn=1。
3、PyramidAnchors
目前,基于anchor的目标检测器和人脸检测器取得了显著进展,被证明是,为每个尺度平衡anchors对检测小的人脸是非常必要的。但是它仍然忽略了每个尺度的上下文特征,因为这些anchor是为人脸区域设计的。为了解决这个问题,我们提出了一个新的可选的anchor方法——PyramidAnchors。
对于目标人脸,PyramidAnchors为大区域相关的人脸生成一系列对应的anchors,这些anchor包含了更多的上下文信息,例如人头,肩膀,和身体。我们通过匹配区域尺度和anchor尺度来选择一些层来设置这类anchors。他们可以监督更高层来为较低层的人脸学习更可表示的特征。为人头,肩膀或者身体给定额外的标签,我们可以准确的匹配anchor和ground truth来生成loss。因为它是不公平的增加额外的标签,我们通过半监督的方式来实现,假设具有同样的比率和偏移的不同人脸区域具有相同的上下文特征。因此,我们可以设置一些统一的boxes来近似表示人头,肩膀和身体的真实区域,只要这些boxes的特征在不同的人脸上是相似的。对一个目标人脸在原图中处于 ![]() ,考虑到
,考虑到 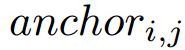 表示第 i 个特征层的第 j 个anchor,步长为
表示第 i 个特征层的第 j 个anchor,步长为![]() ,我们按照下面的公式来定义第k个pyramid-anchor的标签:
,我们按照下面的公式来定义第k个pyramid-anchor的标签:
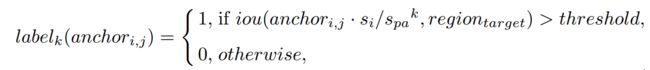
其中,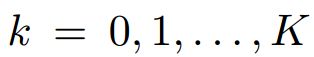 ,
,![]() 是pyramid anchors的步长,
是pyramid anchors的步长,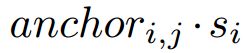 表示原始图片中
表示原始图片中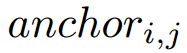 对应的区域,
对应的区域,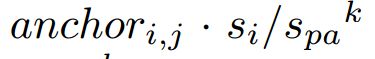 表示以步长为
表示以步长为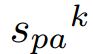 对应的下采样区域。threshold和其他基于anchor的检测器是一样的。在实验中超参数
对应的下采样区域。threshold和其他基于anchor的检测器是一样的。在实验中超参数![]() ,因为邻近预测模块的步长是2。再者,threshold=0.35,K=2。label0,label1,label2分表是人脸,人头,和身体的标签。可以看出一个人脸将会在三个连续的预测模块中生成3个目标,这三个连续的预测模块分别表示人脸,和对应于人脸的人头和身体。图4显示一个列子。
,因为邻近预测模块的步长是2。再者,threshold=0.35,K=2。label0,label1,label2分表是人脸,人头,和身体的标签。可以看出一个人脸将会在三个连续的预测模块中生成3个目标,这三个连续的预测模块分别表示人脸,和对应于人脸的人头和身体。图4显示一个列子。
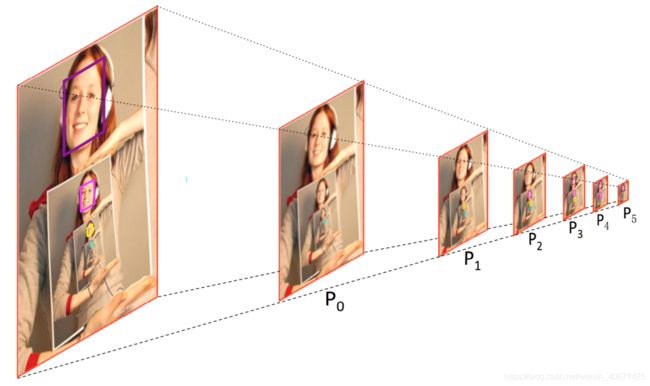 PyramidAnchors的解释
PyramidAnchors的解释
图4解释了PyramidAnchors。例如,对于最大的紫色人脸尺寸为128,在p3,p4,p5处具有pyramid-anchors,其中P3处的anchors是由face-self(人脸本身)标记的conv_fc7生成的。P4处的anchors是由目标人脸的人头(尺寸大约为256)标记的conv6_2生成的。P5处的anchors是由目标人脸的身体(尺寸大约为512)标记的conv7_2生成的(注:作者的图片和文字描述不一,笔者认为图片中紫色框P2,P3,P4应该是P3,P4,P5)。同样的,为了检测最小的尺度为16得蓝绿色人脸,可以从P0处的金字塔anchors获得一个监督特征,P0是由原始人脸标注得到。P1上的金字塔anchors由对应尺度为32的人头标注,P2上的金字塔anchors由对应尺度为64的身体进行标注。
受益于PyramidBox,我们的人脸检测器可以更好的处理小的,模糊的和部分遮挡的人脸。注意pyramid anchors是自动生成的,没有额外的标签,并且半监督学习帮助PyramidBox提取近似的上下文特征。在预测阶段,我们只使用人脸分支的输出,因此对比基于anchor的人脸检测器,运行时没有额外的计算代价。
4、训练
训练数据集:PyramidBox在WIDER FACE数据集上训练了12880张图片,包括颜色蒸馏,随机裁剪和水平翻转。
Data-anchor-sampling:数据采样在统计学,机器学习和模式识别中是一个经典的学科,在近些年取得巨大的发展。对于目标检测任务,focal loss通过改进交叉熵损失函数处理类不平衡问题。
这里,我们利用数据增强采样方法——Data-anchor-sampling。简单来说,data-anchor-sampling通过reshape图片中一张随机人脸到一个随机更小的anchor 尺寸来resize训练图片。准确地说,首先,在样本中随机选择一个尺度为 ![]() 的人脸。PyramidBox中的anchors尺度为:
的人脸。PyramidBox中的anchors尺度为: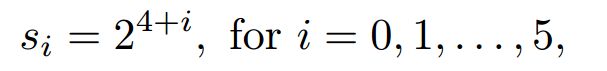 。使得
。使得 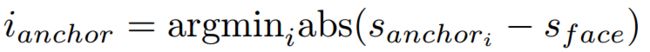 为所选人脸的最近anchor尺度的索引。然后在集合
为所选人脸的最近anchor尺度的索引。然后在集合 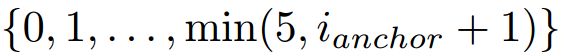 中随机选择一个索引
中随机选择一个索引![]() 。最后,resize 尺度为
。最后,resize 尺度为 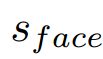 的人脸到:
的人脸到: 。因此,图片的缩放尺度为
。因此,图片的缩放尺度为
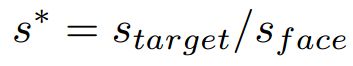
通过尺度 s* 缩放原始图片并裁剪到包含随机选择人脸的640*640标准尺度,我们就得到了anchor-sampled训练数据。例如,我们先随机选择一张人脸,假设它的尺寸为140,然后离它最近的anchor尺寸为128。那么我们需要从16,32,64,128和256中选择一个目标尺寸。通常来说,假设我们选择32,那么利用缩放因子为32/140=0.2285来resize原始图片。最终,从最后resize的包含原始所选人脸的图片中裁剪一个640*640的子图,我们就得到了采样后的训练数据。
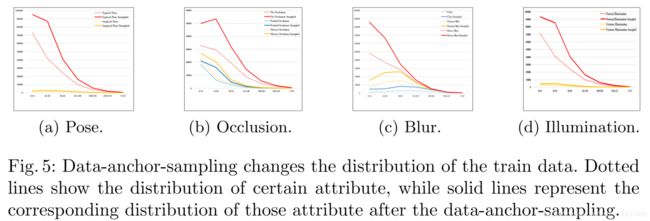
如图5所示,data-anchor-sampling以下面的方式改变了训练数据的分布:1)小脸的比例大于大脸2)通过较大的人脸样本生成较小的人脸样本增加了小尺度人脸样本的多样性。
PyramidBox 损失
PyramidBox损失函数定义为:
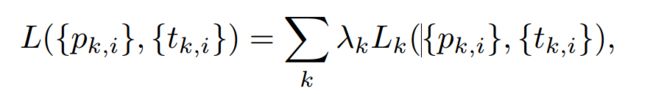
其中第k个pyramid-anchors的损失为
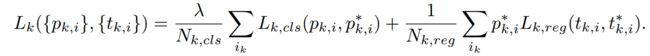
k是pyramid-anchors的索引(k=0,1,2分表表示,人脸,人头和身体)i是一个anchor的索引,并且 ![]() 是anchors i 属于第k个目标(人脸,人头或者身体)的预测概率。ground truth标签定义如下:
是anchors i 属于第k个目标(人脸,人头或者身体)的预测概率。ground truth标签定义如下:
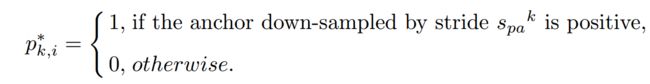
例如当k=0时,ground truth标签等于Fast RCNN中的标签,否则当k>=1时,可以通过匹配下采样的anchores和ground truth来判断对应的标签。另外, 向量表示预测bbox的4个量化坐标。
向量表示预测bbox的4个量化坐标。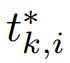 是分配为正anchor的ground truth box<我们按照下面的公式定义它:
是分配为正anchor的ground truth box<我们按照下面的公式定义它:
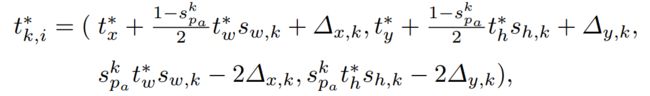
其中![]() 和
和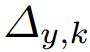 表示偏移量,
表示偏移量,![]() 和
和![]() 分别表示宽度和高度缩放因子。实验中的参数设置:对于k<2时(人脸和人头来说,小中等物体),
分别表示宽度和高度缩放因子。实验中的参数设置:对于k<2时(人脸和人头来说,小中等物体),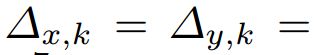 0,
0,![]() 。对于k = 2时(对于身体来说,大物体)
。对于k = 2时(对于身体来说,大物体) 。分类损失
。分类损失![]() 二类(人脸vs.非人脸)log损失。
二类(人脸vs.非人脸)log损失。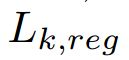 回归损失是Fast RCNN中的平滑L1损失。
回归损失是Fast RCNN中的平滑L1损失。 表示回归损失,只对正anchors 有效。分类损失和回归损失分别利用
表示回归损失,只对正anchors 有效。分类损失和回归损失分别利用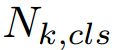 和
和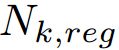 进行标准化,对于k = 0,1,2采用
进行标准化,对于k = 0,1,2采用 ![]() 和
和![]() 平衡权重。
平衡权重。
优化
PyramidBox采用预训练的VGG16进行权重初始化。conv_fc67和conv_fc7的参数利用VGG16的fc6和fc7下采样参数进行初始化,其他额外的层采用随机初始化。在WIDER FACE训练集上,batch size为16,前80k迭代的学习率为0.001,接下来的20k迭代的学习率为0.0001,最后20k迭代的学习率为0.00001.。momentum为0.9,权重衰减为0.0005。