试水DCGAN(tensorflow平台实现的face-generation)
之前看过优达学城的一个深度学习的课程,主讲是个youtube上的印度网红,做了一个GAN生成人脸的简单项目(但是训练的是28*28的人脸),这次掏出来再看完paper之后,再重新试水训练一下 64 × 64 64\times64 64×64的人脸。算是正式开始学习深度学习和tensorflow的一个项目,毕竟明年可能要在实际项目中应用了。
GAN生成模型
GAN是Ian Goodfellow 在14年在Generative Adversarial Nets中提出的一种生成模型。这种模型总共有两个完全不同的网络构成,一个generator和一个discriminator, 通过对抗训练,得到了很神奇的效果,目前是深度学习领域非常火的一种网络。 generator的任务是生成假样本去欺骗discriminator,而discriminator的任务则是从真假样本中区分出假样本,两个网络相互对抗训练。当训练到最优情况下, generator生成的样本就像从真样本中获取的一样,discriminator对于任意样本都是以0.5的概率输出真或假。
虽然GAN获得了非常神奇的效果,但是也依然村一些未解决的问题
- 难以训练,难以把握discriminator和generator之间的平衡,discriminator往往很容易快速收敛,导致generator无法进一步得到更新
- mode collapse, 即训练得到的模型只输出部分学习样本,导致输出样本多样性过低。
- loss无法反应当前训练模型的好坏,没有好的指标,WGAN提出了一个指标,但是这次只实验DCGAN.
对于训练数据用 x x x表示, 其分布为 p x p_x px, D ( x ) D(x) D(x)则是discriminator,需要区分出真样本。样本来自真实样本的概率越高,则 D ( x ) D(x) D(x)越大。
z z z为一个低维的均匀分布或者高斯分布, G ( x ) G(x) G(x)是generator,它将 z z z的分布变换为真实数据的分布来欺骗 D D D。
损失函数
网络的loss function如下
m i n G m a x D V ( D , G ) = E x ∼ p d a t a ( x ) [ l o g D ( x ) ] + E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] \mathop{min}_G\mathop{max}_DV(D,G)=E_{x∼p_{data}(x)}[logD(x)]+E_{z∼p_z(z)}[log(1−D(G(z)))] minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
DCGAN
DCGAN是在原本的GAN结构基础上对于网络架构进行了一些改进,使得网络能更快更稳定收敛。网上资料说DCGAN是个偏工程化的探索,改动都说不出为什么一定要这么改,但是效果不错。
改动如下:
- 全连接层用stride卷积代替
- 每层卷积层后接batchNorm层,
- generator的最后一层用tanh, discriminator的最后一层用sigmoid.
- generator的激活函数用ReLu, discriminator的激活函数用Leaky-Relu
paper中的网络结构如下

在我实现过程中发现这个结构,discrimintor收敛太快,generator却没有收敛到,所以我改动了一下,代码如下
def generator(z, is_train = True):
with tf.variable_scope("generator", reuse= not is_train):
x1 = tf.layers.dense(z, 8*8*512)
x1 = tf.nn.tanh(x1) #计算x的正切值
x1 = tf.reshape(x1, (-1, 8, 8, 512))
x1 = tf.layers.batch_normalization(x1, training=is_train)
x1 = tf.nn.relu(x1)
x2 = tf.layers.conv2d_transpose(x1, 256, 5, strides=2, padding='same')
x2 = tf.layers.batch_normalization(x2, training=is_train)
x2 = tf.nn.relu(x2)
x3 = tf.layers.conv2d_transpose(x2, 128, 5, strides=2, padding='same')
x3 = tf.nn.relu(x3)
x3 = tf.layers.batch_normalization(x3, training=is_train)
logits = tf.layers.conv2d_transpose(x3, 3, 5, strides=2, padding='same')
out = tf.tanh(logits)
return out
discriminator的结构和generator对称,如下
def Discriminator(images, reuse=False):
with tf.variable_scope("discriminator", reuse= reuse):
alpha = 0.2
x1 = tf.layers.conv2d(images, 128, 5, strides=2, padding='same')
bn1 = tf.layers.batch_normalization(x1, training=True)
relu1 = tf.nn.leaky_relu(bn1, alpha)
x2 = tf.layers.conv2d(relu1, 256, 5, strides=2, padding='same')
bn2 = tf.layers.batch_normalization(x2, training=True)
relu2 = tf.nn.leaky_relu(bn2, alpha)
x3 = tf.layers.conv2d(relu2, 512, 5, strides=2, padding='same')
bn3 = tf.layers.batch_normalization(x3, training=True)
relu3 = tf.nn.leaky_relu(bn3, alpha)
# Flatten it
flat = tf.reshape(relu3, (-1, 8*8*512))
logits = tf.layers.dense(flat, 1)
out = tf.sigmoid(logits)
return out, logits
loss function and Optimization
discriminator和generator都定义好了,需要定义网络的损失函数,这里按照paper中用的是交叉熵。
def model_loss(input_real, input_z):
g_model = generator(input_z)
d_model_real, d_logits_real = Discriminator(input_real)
d_model_fake, d_logits_fake = Discriminator(g_model, reuse=True)
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=d_logits_real, labels=tf.ones_like(d_model_real) * 0.999))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=d_logits_fake, labels=tf.zeros_like(d_model_fake)))
# discriminal loss
d_loss = d_loss_real + d_loss_fake
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_loss
优化器采用Adam
def model_opt(d_loss, g_loss, learning_rate, beta1):
"""
Get optimization operations
:param d_loss: Discriminator loss Tensor
:param g_loss: Generator loss Tensor
:param learning_rate: Learning Rate Placeholder
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:return: A tuple of (discriminator training operation, generator training operation)
"""
# Get the trainable_variables, split into G and D parts
t_vars = tf.trainable_variables()
g_vars = [var for var in t_vars if var.name.startswith('generator')]
#print('g_Var:',g_vars)
d_vars = [var for var in t_vars if var.name.startswith('discriminator')]
#print('d_var:',d_vars)
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
d_train_opt = tf.train.AdamOptimizer(learning_rate, beta1 = beta1).minimize(d_loss, var_list=d_vars)
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
g_train_opt = tf.train.AdamOptimizer(learning_rate, beta1 = beta1).minimize(g_loss, var_list=g_vars)
return d_train_opt, g_train_opt
train
这里有个trick是看得网上的套路,训练一次D的时候,训练两次G,据说这么搞效果好。
def train(epoch_count, batch_size, z_dim, learning_rate, beta1, get_batches, data_shape, data_image_mode):
"""
Train the GAN
:param epoch_count: Number of epochs
:param batch_size: Batch Size
:param z_dim: Z dimension
:param learning_rate: Learning Rate
:param beta1: The exponential decay rate for the 1st moment in the optimizer
:param get_batches: Function to get batches
:param data_shape: Shape of the data
:param data_image_mode: The image mode to use for images ("RGB" or "L")
"""
InputHolder,z_InputHolder,LearningRate = model_inputs(data_shape[1], data_shape[2], data_shape[3], z_dim)
d_loss, g_loss = model_loss(InputHolder, z_InputHolder)
d_train_opt, g_train_opt = model_opt(d_loss, g_loss, LearningRate, beta1)
with tf.Session() as sess:
writer = tf.summary.FileWriter("logs/", sess.graph) #第一个参数指定生成文件的目录。
example_z = np.random.uniform(-1, 1, size=[25, z_dim]) # 固定噪声,观察
g_loss_sum = tf.summary.scalar("g_loss", g_loss)
d_loss_sum = tf.summary.scalar("d_loss", d_loss)
# 变量初始化
sess.run(tf.global_variables_initializer())
batchNum = 0
for epoch_i in range(epoch_count):
for batch_images in get_batches(batch_size):
batch_images = batch_images * 2
# Sample random noise for G
batch_z = np.random.uniform(-1.0, 1.0, size=(batch_size, z_dim))
#batch_z = np.random.normal(0, 1.0, size=(batch_size, z_dim))
# Run optimizers
_,summary_str = sess.run([d_train_opt, d_loss_sum], feed_dict={InputHolder: batch_images, z_InputHolder: batch_z,
LearningRate: learning_rate})
writer.add_summary(summary_str, batchNum)
_ ,summary_str = sess.run([g_train_opt,g_loss_sum], feed_dict={InputHolder: batch_images,z_InputHolder: batch_z,
LearningRate: learning_rate})
writer.add_summary(summary_str, batchNum)
_ ,summary_str = sess.run([g_train_opt,g_loss_sum], feed_dict={InputHolder: batch_images,z_InputHolder: batch_z,
LearningRate: learning_rate})
writer.add_summary(summary_str, batchNum)
batchNum += 1
if batchNum % 100 == 0:
samples = sess.run(generator(z_InputHolder, False), feed_dict={z_InputHolder: example_z})
images_grid = helper.images_square_grid(samples, data_image_mode)
if not os.path.exists(SaveSample_dir):
os.makedirs(SaveSample_dir)
strFileName = "Epoch_{}_{}.jpg".format(epoch_i+1, batchNum)
strFileName = os.path.join(SaveSample_dir,strFileName)
scipy.misc.imsave(strFileName, images_grid)
if batchNum % 10 == 0:
# At the end of each epoch, get the losses and print them out
train_loss_d = d_loss.eval({InputHolder: batch_images, z_InputHolder: batch_z,LearningRate: learning_rate})
train_loss_g = g_loss.eval({z_InputHolder: batch_z})
print("Epoch {}/{}...".format(epoch_i+1, epoch_count),
"Discriminator Loss: {:.4f}...".format(train_loss_d),
"Generator Loss: {:.4f}".format(train_loss_g))
if np.mod(batchNum, 500) == 0:
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(max_to_keep=1)
saver.save(sess, os.path.join(checkpoint_dir,"DCGAN.model"),global_step = batchNum)
show_generator_output(sess, 25, z_InputHolder, data_image_mode)
return sess
实验结果
程序还在跑中,目前一个epoch还没跑完已经可以看到一些人脸了,多个epoch之后效果应该会更好,等跑完了再更新,深度学习还挺奇妙的,做到了传统算法难以达到的功能。
人脸生成效果
batchsize = 64 ,看上去存在一定不足,但是一些已经可以看出是人脸了,生成图像大小是64*64,训练图片来自celeba对齐后的数据。 感觉效果还是有一点欠缺,没有那么多时间去尝试不同参数组合选最优了。
| 半个ecpoch | 12个epoch |
|---|---|
 |
 |
对于采样的几个噪声做成gif如下,感觉过渡不是特别自然,后期训练变化不大。
目前来看,大多数脸都比较清晰了,GPU比较差,显存也低,跑了10多个小时,才跑完这10个epoch。
以下两个是训练过程中的loss变化曲线, d_loss和g_loss此起彼伏,g_loss不断处于一个不断震荡的状态。

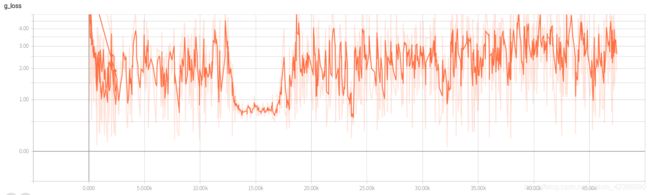
tensorboad中的graph如下

初次试水先这样吧,后续尝试一下其他的GAN,或者实现一下基于GAN的图像补全等操作,也可以尝试一下pyTorch框架,貌似网上都说不错,更接近python风格,更好用。