python面试中常见的8种排序算法
一、插入排序
介绍
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据。
算法适用于少量数据的排序,时间复杂度为O(n^2)。
插入排算法是稳定的排序方法。
步骤
①从第一个元素开始,该元素可以认为已经被排序
②取出下一个元素,在已经排序的元素序列中从后向前扫描
③如果该元素(已排序)大于新元素,将该元素移到下一位置
④重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⑤将新元素插入到该位置中
⑥重复步骤2
排序演示
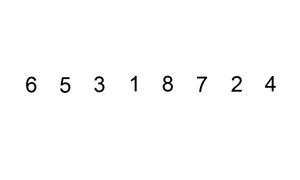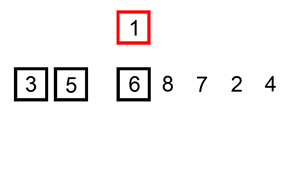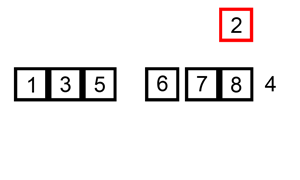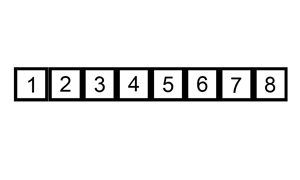
算法实现
# 插入排序
def insert_sort(lists):
count=len(lists)
for i in range(1,count):
key=lists[i]
j=i-1
while j>=0:
if lists[j]>key:
lists[j+1]=lists[j]
lists[j]=key
j-=1
return lists
二、冒泡排序
介绍
冒泡排序(Bubble Sort)是一种简单的排序算法,时间复杂度为O(n^2)。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
原理
循环遍历列表,每次循环找出循环最大的元素排在后面;
需要使用嵌套循环实现:外层循环控制总循环次数,内层循环负责每轮的循环比较。
步骤
①比较相邻的元素。如果第一个比第二个大,就交换他们两个。
②对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
③针对所有的元素重复以上的步骤,除了最后一个。
④持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
算法实现:
# 冒泡排序
'''
排序的总轮数=列表元素个数 - 1
每轮元素互相比较的次数 = 列表元素个数 - 已经排好序的元素个数 - 1
'''
def bubble_sort(data_list):
num=len(data_list)#列表元素个数
for i in range(0,num-1):#排序的总轮数
print("第{}轮:".format(i))
for j in range(0,num-i-1):
if data_list[j]>data_list[j+1]:#前后两个元素比较
data_list[j],data_list[j+1]=data_list[j+1],data_list[j]
print(data_list)
lists=[28,32,14,12,53,42]
bubble_sort(lists)
三、快速排序
介绍
快速排序(Quicksort)是对冒泡排序的一种改进,借用了分治的思想,由C. A. R. Hoare在1962年提出。
基本思想
快速排序的基本思想是:挖坑填数 + 分治法。
首先选出一个轴值(pivot,也有叫基准的),通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
实现步骤
①从数列中挑出一个元素,称为 “基准”(pivot);
②重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边);
③对所有两个小数列重复第二步,直至各区间只有一个数。
排序演示
算法实现
#快速排序
def quick_sort(data_list,start,end):
#设置递归结束条件
if start>=end:
return
low_index=start#低位游标
high_index=end#高位游标
basic_data=data_list[start]#初始基准值
while low_index<high_index:
#模拟高位游标从右向左指向的元素与基准值进行比较,比基准值大则高位游标一直向左移动
while low_index<high_index and data_list[high_index]>=basic_data:
high_index-=1
if low_index!=high_index:
#当高位游标指向的元素小于基准值,则移动该值到低位游标指向的位置
data_list[low_index]=data_list[high_index]
low_index+=1#低位游标向右移动一位
while low_index<high_index and data_list[low_index]<basic_data:
low_index+=1
if low_index!=high_index:
data_list[high_index]=data_list[low_index]
high_index-=1
data_list[low_index]=basic_data
#递归调用
quick_sort(data_list,start,low_index-1)#对基准值左边未排序队列排序
quick_sort(data_list,high_index+1,end)#对基准值右边未排序队列排序
lists=[28,32,14,12,53,42]
quick_sort(lists,0,len(lists)-1)
print(lists)
四、希尔排序
介绍
希尔排序(Shell Sort)是插入排序的一种,也是缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法,时间复杂度为:O(1.3n)。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率; ·
但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位。
基本思想
①希尔排序是把记录按下标的一定量分组,对每组使用直接插入算法排序;
②随着增量逐渐减少,每组包1含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法被终止。
排序演示
算法实现
# 希尔排序
def shell_sort(lists):
count=len(lists)
step=2
group=count/step
while group>0:
for i in range(0,group):
j=i+group
while j<count:
k=j-group
key=lists[j]
while k>=0:
if lists[k]>key:
lists[k+group]=lists[k]
lists[k]=key
k-=group
j+=group
group/=step
return lists
五、选择排序
介绍
选择排序(Selection sort)是一种简单直观的排序算法,时间复杂度为Ο(n2)。
基本思想
选择排序的基本思想:比较 + 交换。
第一趟,在待排序记录r1 ~ r[n]中选出最小的记录,将它与r1交换;
第二趟,在待排序记录r2 ~ r[n]中选出最小的记录,将它与r2交换;
以此类推,第 i 趟,在待排序记录ri ~ r[n]中选出最小的记录,将它与r[i]交换,使有序序列不断增长直到全部排序完毕。
排序演示
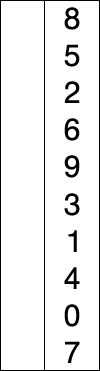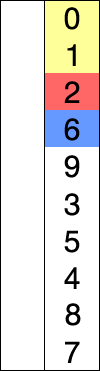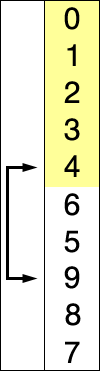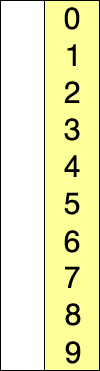
选择排序的示例动画。红色表示当前最小值,黄色表示已排序序列,蓝色表示当前位置。
算法实现
# 选择排序
def select_sort(lists):
count=len(lists)
for i in range(0,count):
min1=i
for j in range(i+1,count):
if lists[min1]>lists[j]:
min1=j
lists[min1],lists[i]=lists[i],lists[min1]
return lists
六、堆排序
介绍
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。
利用数组的特点快速指定索引的元素。
基本思想
堆分为大根堆和小根堆,是完全二叉树。
大根堆的要求是每个节点的值不大于其父节点的值,即A[PARENT[i]] >=A[i]。
在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
排序演示

算法实现
#堆排序
def adjust_heap(lists,i,size):
lchild=2*i+1
rchild=2*i+2
max1=i
if i<size/2:
if lchild<size and lists[lchild]>lists[max1]:
max1=lchild
if rchild<size and lists[rchild]>lists[max1]:
max1=rchild
if max1!=i:
lists[max1],lists[i]=lists[i],lists[max1]
adjust_heap(lists,max1,size)
def build_heap(lists,size):
for i in range(0,(size/2))[::-1]:
adjust_heap(lists,i,size)
def heap_sort(lists):
size=len(lists)
build_heap(lists,size)
for i in range(0,size)[::-1]:
lists[0],lists[i]=lists[i],lists[0]
adjust_heap(lists,0,i)
七、归并排序
介绍
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
基本思想
归并排序算法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
算法思想
自上而下递归法(假如序列共有n个元素)
① 将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
② 将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
③ 重复步骤②,直到所有元素排序完毕。
自下而上迭代法
① 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
② 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
③ 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
④ 重复步骤③直到某一指针达到序列尾;
⑤ 将另一序列剩下的所有元素直接复制到合并序列尾。
排序演示
算法实现
# 归并排序
def merge_sort(data_list):
if len(data_list)<=1:
return data_list
#根据列表长度确定拆分的中间位置
mid_index=len(data_list)//2
# left_list = data_list[:mid_index] #使用切片实现对列表的切分
# right_list = data_list[mid_index:]
left_list=merge_sort(data_list[:mid_index])
right_list=merge_sort(data_list[mid_index:])
return merge(left_list,right_list)
def merge(left_list,right_list):
l_index=0
r_index=0
merge_list=[]
while l_index<len(left_list) and r_index<len(right_list):
if left_list[l_index]<right_list[r_index]:
merge_list.append(left_list[l_index])
l_index+=1
else:
merge_list.append(right_list[r_index])
r_index+=1
merge_list+=left_list[l_index:]
merge_list+=right_list[r_index:]
return merge_list
lists=[28,32,14,12,53,42]
new_list=merge_sort(lists)
print("--------排序结果--------")
print(new_list)
八、基数排序
介绍
基数排序(Radix Sort)属于“分配式排序”,又称为“桶子法”。
基数排序法是属于稳定性的排序,其时间复杂度为O (nlog®m) ,其中 r 为采取的基数,而m为堆数。
在某些时候,基数排序法的效率高于其他的稳定性排序法。
基本思想
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序按照优先从高位或低位来排序有两种实现方案:
MSD(Most significant digital) 从最左侧高位开始进行排序。先按k1排序分组, 同一组中记录, 关键码k1相等,再对各组按k2排序分成子组, 之后, 对后面的关键码继续这样的排序分组, 直到按最次位关键码kd对各子组排序后. 再将各组连接起来,便得到一个有序序列。MSD方式适用于位数多的序列。
LSD (Least significant digital)从最右侧低位开始进行排序。先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。LSD方式适用于位数少的序列。
排序效果

算法实现
import math
#基数排序
def radix_sort(lists,radix=10):
k=int(math.ceil(math.log(max(lists),radix)))
bucket=[[] for i in range(radix)]
for i in range(1,k+1):
for j in lists:
bucket[j/(radix**(i-1))%(radix**i)].append(j)
del lists[:]
for z in bucket:
lists+=z
del z[:]
return lists
九、总结
各种排序的稳定性、时间复杂度、空间复杂度的总结:

平方阶O(n²)排序:各类简单排序:直接插入、直接选择和冒泡排序;
从时间复杂度来说:
线性对数阶O(nlog₂n)排序:快速排序、堆排序和归并排序; O(n1+§))排序,§是介于0和1之间的常数:希尔排序 ;
线性阶O(n)排序:基数排序,此外还有桶、箱排序。