用VGG_16网络模型训练并测试自己的数据库(超级详细的教程)
- 网络结构:VGG-16
- 数据库:cats_vs_dogs
- 硬件:Nvida Quadro p2000 5GB
- 深度学习框架:Tensorflow
文章目录
- step1: Get File
- step2: Transform To TFRecord
- step3: Read TFRecord
- stpe4: VGG_16 Model
- step5: Train
step1: Get File
找到已经下载到电脑上的数据集
def get_file(file_dir):
print('searching images...')
images = []
temp = [] # 临时list
labels = []
# for root,sub_folders,files in os.walk(file_dir):
# for name in files:
# if name.endswith('.jpg'):
# images.append(os.path.join(root,name))
# if name in sub_folders:
# temp.append(os.path.join(root,name)) #存放文件路径
# for one_folder in temp:
# n_img = len(os.listdir(one_folder))
# print('number of files:',n_img)
# class_name = one_folder.split('\\')[-1] # 文件名即为分类名称
# if class_name == 'cats':
# labels = np.append(labels,n_img*[1])
# elif class_name == 'dogs':
# labels = np.append(labels,n_img*[2])
cats_path = file_dir + '/cats'
dogs_path = file_dir + '/dogs'
for filename in os.listdir(cats_path):
images.append(os.path.join(cats_path,filename))
labels.append(1)
# print(len(images))
for filename in os.listdir(dogs_path):
images.append(os.path.join(dogs_path,filename))
labels.append(2)
# print(len(images))
temp = np.array([images,
labels]) # [2,total_n_img]
temp = temp.transpose() # 转置
np.random.shuffle(temp) # shuffle
image_list = list(temp[:,0])
label_list = list(temp[:,1])
label_list = [int(float(i)) for i in label_list]
'''
# 将所有的list分为两部分,一部分用来训练tra,一部分用来验证val
n_sample = len(image_list)
n_val = int(math.ceil(n_sample * ratio))
n_train = n_sample - n_val
tra_images = image_list[0:n_train]
tra_labels = label_list[0:n_train]
tra_labels = [int(flaot(i)) for i in tra_labels]
val_images = image_list[n_train:-1]
val_labels = label_list[n_train:-1]
val_labels = [int(flaot(i)) for i in val_labels]
return tra_images,tra_labels,val_images,val_labels
'''
return image_list,label_list
测试代码
image_list,label_list = get_file(img_path)
print('number of image:',len(image_list))
print('number of label:',len(label_list))
# 来10张图片测试一下image和label是否一一对应
for i in range(10):
image = Image.open(image_list[i])
plt.subplot()
plt.title(label_list[i])
plt.imshow(image)
plt.show()
测试结果
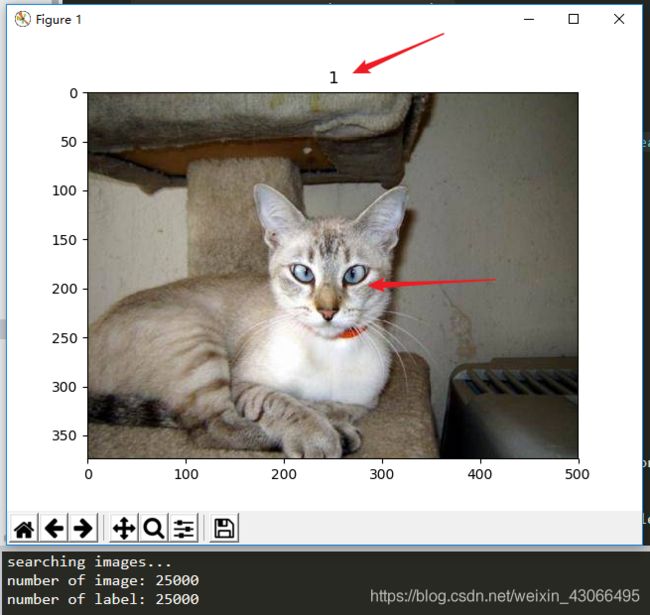
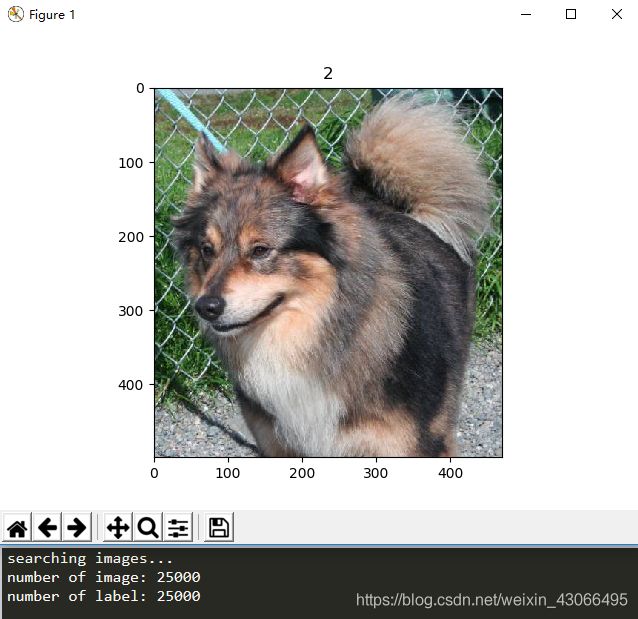
No Problem!
step2: Transform To TFRecord
将img转化为TFRecord文件
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def convet_to_tfrecord(images,labels,save_dir,name,image_size):
filename = os.path.join(save_dir,name+'.tfrecords')
if tf.gfile.Exists(filename):
print('\n%s already exist!\n' % filename)
return
n_samples = len(labels)
if np.shape(images)[0] != n_samples:
raise ValueError('Image size %d dose not match labels size %d.' %
(images.size(),labels.size()))
writer = tf.python_io.TFRecordWriter(filename)
print('\nTransform start...')
m=n=0
for i in np.arange(0,n_samples):
try:
m += 1
image = Image.open(images[i])
image = image.resize(image_size)
image_raw = image.tobytes()
label = int(labels[i])
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':_bytes_feature(image_raw),
'label':_int64_feature(label)
}))
writer.write(example.SerializeToString())
print('Num of successful:',m)
except IOError as e:
n += 1
print('Could not read:',images[i])
print('Error type:',e)
print('Skip it !\n')
writer.close()
print('Transform done !')
print('Transformed : %d\t failed : %d\n' % (m,n))
return filename
测试代码
tfrecords_file_path = convet_to_tfrecord(image_list,
label_list,
save_dir=save_dir,
name=tfrecords_name,
image_size=image_size)
print(tfrecords_file_path)
结果:打印出.tfrecords文件的路径及名称
- 注:这里我用的是整个cats_vs_dogs数据集,一共25000张图片(接近600M)。存入.tfrecords文件的图片大小是224x224. 整个.tfrecords文件相当大(3.5GB)。
step3: Read TFRecord
读取TFRecord文件
def read_and_decode(tfrecords_file,batch_size,image_size):
filename_queue = tf.train.string_input_producer([tfrecords_file])
reader = tf.TFRecordReader()
_,serialized_example = reader.read(filename_queue)
img_feature = tf.parse_single_example(serialized_example,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
'label':tf.FixedLenFeature([],tf.int64)
})
image = tf.decode_raw(img_feature['image_raw'],tf.uint8)
image = tf.reshape(image,[image_size[0],image_size[1],3])
label = tf.cast(img_feature['label'],tf.int32)
image_batch, label_batch = tf.train.batch([image,label],
batch_size=batch_size,
num_threads=64,
capacity=2000)
return image_batch,tf.reshape(label_batch,[batch_size])
测试代码
image_batch,label_batch = read_and_decode(tfrecords_file_path,
batch_size=batch_size,
image_size=image_size)
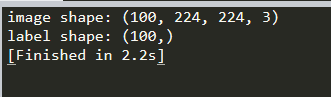
print('image shape:',image_batch.shape)
print('label shape:',label_batch.shape)
测试结果
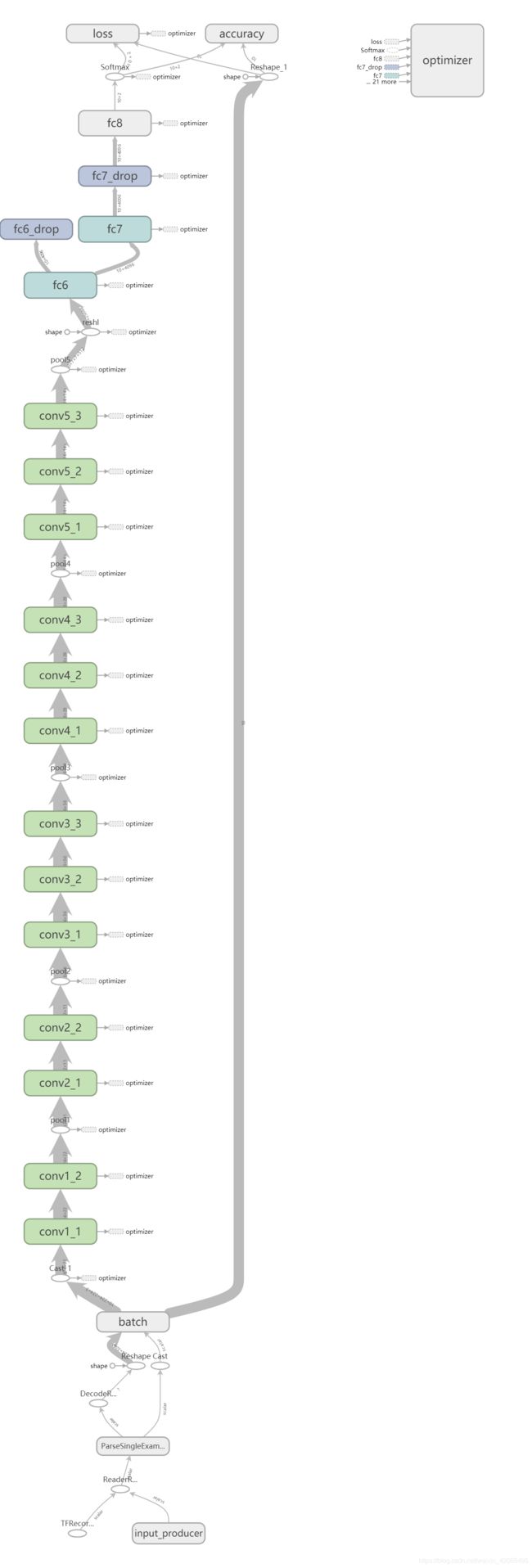
stpe4: VGG_16 Model
构建VGG-16网络结构模型,这部分没什么好说的,网上版本多的是,大同小异。
import tensorflow as tf
def conv_op(input_op,name,kh,kw,n_out,dh,dw,p):
n_in = input_op.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+'w',
shape=[kh,kw,n_in,n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv = tf.nn.conv2d(input_op,kernel,[1,dh,dw,1],padding='SAME')
bias_init_val = tf.constant(0.0,shape=[n_out],dtype=tf.float32)
biases = tf.Variable(bias_init_val,trainable=True,name='b')
z = tf.nn.bias_add(conv,biases)
activation = tf.nn.relu(z,name=scope)
p += [kernel,biases]
return activation
def fc_op(input_op,name,n_out,p):
n_in = input_op.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+'w',
shape=[n_in,n_out],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
biases = tf.Variable(tf.constant(0.0,shape=[n_out],dtype=tf.float32),name='b')
activation = tf.nn.relu_layer(input_op,kernel,biases,name=scope)
p += [kernel,biases]
return activation
def mpool_op(input_op,name,kh,kw,dh,dw):
return tf.nn.max_pool(input_op,
ksize=[1,kh,kw,1],
strides=[1,dh,dw,1],
padding='SAME',
name=name)
def inference_op(input_op,keep_prob):
p=[]
conv1_1 = conv_op(input_op, name='conv1_1', kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
conv1_2 = conv_op(conv1_1, name='conv1_2', kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
pool1 = mpool_op(conv1_2, name='pool1', kh=2, kw=2, dh=2, dw=2)
conv2_1 = conv_op(pool1, name='conv2_1', kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
conv2_2 = conv_op(conv2_1, name='conv2_2', kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
pool2 = mpool_op(conv2_2, name='pool2', kh=2, kw=2, dh=2, dw=2)
conv3_1 = conv_op(pool2, name='conv3_1', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_2 = conv_op(conv3_1, name='conv3_2', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_3 = conv_op(conv3_2, name='conv3_3', kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
pool3 = mpool_op(conv3_3, name='pool3', kh=2, kw=2, dh=2, dw=2)
conv4_1 = conv_op(pool3, name='conv4_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_2 = conv_op(conv4_1, name='conv4_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_3 = conv_op(conv4_2, name='conv4_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool4 = mpool_op(conv4_3, name='pool4', kh=2, kw=2, dh=2, dw=2)
conv5_1 = conv_op(pool4, name='conv5_1', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_2 = conv_op(conv5_1, name='conv5_2', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_3 = conv_op(conv5_2, name='conv5_3', kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool5 = mpool_op(conv5_3, name='pool5', kh=2, kw=2, dh=2, dw=2)
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
reshl = tf.reshape(pool5,[-1,flattened_shape],name='reshl')
fc6 = fc_op(reshl,name='fc6',n_out=4096,p=p)
fc6_drop = tf.nn.dropout(fc6,keep_prob,name='fc6_drop')
fc7 = fc_op(fc6_drop,name='fc7',n_out=4096,p=p)
fc7_drop = tf.nn.dropout(fc7,keep_prob,name='fc7_drop')
fc8 = fc_op(fc7_drop,name='fc8',n_out=1000,p=p)
softmax = tf.nn.softmax(fc8)
return softmax
def losses(logits,labels): # logits:网络计算输出值,labels:真实值,0,1
with tf.variable_scope('loss') as scope:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels,
name='x_entropy_per_example')
loss = tf.reduce_mean(cross_entropy,name='loss')
tf.summary.scalar(scope.name + '/loss',loss)
return loss
def training(loss,learning_rate):
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
global_step = tf.Variable(0,name='global_step',trainable=False)
train_op = optimizer.minimize(loss,global_step=global_step)
return train_op # 返回参数:train_op,训练op,这个参数要输入sess.run中让模型去训练。
def evaluation(logits,labels):
with tf.variable_scope('accuracy') as scope:
correct = tf.nn.in_top_k(logits,labels,1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float16))
tf.summary.scalar(scope.name + '/accuracy',accuracy)
return accuracy
# tensorboard
def variable_summary(var,name):
with tf.name_scope(name):
mean = tf.reduce_mean(var)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('mean',mean)
tf.summary.scalar('stddev',stddev)
tf.summary.scalar('min',tf.reduce_min(var))
tf.summary.scalar('max',tf.reduce_max(var))
tf.summary.histogram('histogram',var)
# histogram:打印直方图,反应变量分布
step5: Train
import tensorflow as tf
from vgg_16 import *
from imgPreprocess import read_and_decode
import numpy as np
from datetime import datetime
import time
IMAGE_SIZE = (224,224)
batch_size = 10 # 每个batch放多少张img batch过大内存会不够用
num_batch = 100 # 产生的批次数
learning_rate = 0.0001 # 一般不小于
keep_prob = 0.8
tfrecords_file = './data/train.tfrecords' # tfrecords数据文件名(在目标文件目录下)
saver_path = './model/model.ckpt' # 模型保存路径
logs_trian_dir = './logs'
image_batch,label_batch = read_and_decode(tfrecords_file,
batch_size,
image_size=IMAGE_SIZE)
# 训练操作定义
image_batch = tf.cast(image_batch,tf.float32) # 需要将image_batch dtype转换成tf.float32 不然会报错
train_logits = inference_op(image_batch,keep_prob)
train_loss = losses(train_logits,label_batch)
train_op = training(train_loss,learning_rate)
trian_acc = evaluation(train_logits,label_batch)
# log汇总记录
summary_op = tf.summary.merge_all()
# 产生一个会话
sess = tf.Session()
train_writer = tf.summary.FileWriter(logs_trian_dir,sess.graph)
saver = tf.train.Saver()
# 节点初始化
sess.run(tf.global_variables_initializer())
#队列监控
coord = tf.train.Coordinator() #设置多线程协调器
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
# 进行batch训练
try:
for step in np.arange(num_batch):
if coord.should_stop():
break
start_time = time.time()
_,tra_loss,tra_acc = sess.run([train_op,train_loss,trian_acc])
duration = time.time() - start_time
# 每隔10步打印一次当前的loss , acc ,同时记录log,写入writer
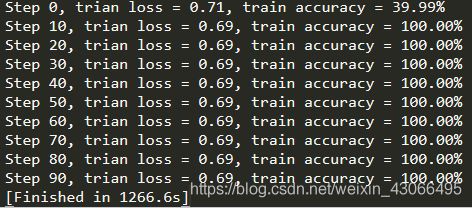
if step % 10 == 0:
print('%s Step %d, trian loss = %.2f, train accuracy = %.2f%%, duration = %s' %
(datetime.now(),step,tra_loss,tra_acc*100.0,duration))
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str,step)
# 保存最后一次网络参数
saver.save(sess,saver_path)
'''
# 每隔10步,保存一次训练好的模型
if(step+1) == num_batch:
saver.save(sess,saver_path)
'''
except tf.errors.OutOfRangeError:
print('Done Training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
sess.close()
运行结果
IMAGE_SIZE = (224,224)
batch_size = 10
num_batch = 100
可以看到:耗时非常长(大约21min)
另外:为什么运行到第10个周期之后 acc 就达到了100%
- 我们来看一下生成的文件
./logs目录下
./model目录下

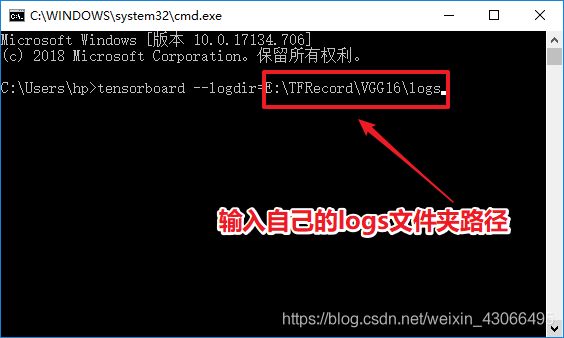
- Now ! 让我们来调出强大Tensorboard,看一下训练过程究竟发生了什么
- win + R
- 输入cmd
- 输入下图所示命令
- 打开浏览器 Ctrl + V 就会看到熟悉的界面
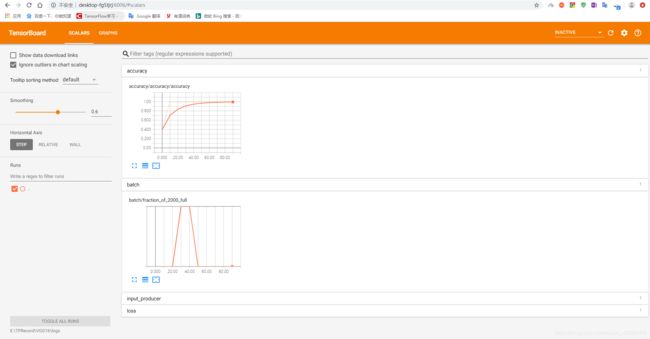
Graph