Shape Robust Text Detection with Progressive Scale Expansion Network 论文阅读
论文地址:https://arxiv.org/pdf/1806.02559.pdf
Abstract
The challenges of shape robust text detection lie in two aspects: 1) most existing quadrangular bounding box based detectors are difficult to locate texts with arbitrary shapes, which are hard to be enclosed perfectly in a rectangle; 2) most pixel-wise segmentation-based detectors may not separate the text instances that are very close to each other. To address these problems, we propose a novel Progressive Scale Expansion Network (PSENet), designed as a segmentation-based detector with multiple predictions for each text instance. These predictions correspond to different kernels produced by shrinking the original text instance into various scales. Consequently, the final detection can be conducted through our progressive scale expansion algorithm which gradually expands the kernels with minimal scales to the text instances with maximal and complete shapes. Due to the fact that there are large geometrical margins among these minimal kernels, our method is effective to distinguish the adjacent text instances and is robust to arbitrary shapes. The state-of-the-art results on ICDAR 2015 and ICDAR 2017 MLT benchmarks further confirm the great effectiveness of PSENet. Notably, PSENet outperforms the previous best record by absolute 6.37% on the curve text dataset SCUT-CTW1500. Code will be available in https://github.com/whai362/PSENet.
任意文本检测面临的挑战主要表现在两个方面:
1)现有的基于四边形边界框的检测器难以定位任意形状的文本,难以将文本完美地封装在矩形中;
2)大多数基于像素分段的检测器可能无法将非常接近的文本实例分开。
为了解决这些问题,我们提出了一种新型的渐进比例扩张网络(PSENet),它被设计成一个基于分段的检测器,对每个文本实例进行多个预测。这些预测对应于通过将原始文本实例缩小到不同的范围而产生的不同内核。因此,最终的检测可以通过我们的渐进比例扩张算法进行,该算法将最小尺度的内核逐步扩展到最大和完整形状的文本实例。由于这些最小核之间存在较大的几何边界,因此我们的方法能够有效地区分相邻的文本实例,并且对任意形状具有鲁棒性。ICDAR 2015和ICDAR 2017 MLT基准测试的最新结果进一步证实了PSENet的巨大有效性。值得注意的是,PSENet在SCUT-CTW1500曲线文本数据集上的性能比之前的最佳记录绝对高6.37%。代码将在https://github.com/whai362/PSENet中提供。
1 Introduction
Recently, natural scene text detection has attracted extensive attention for its numerous applications, such as scene understanding, product identification, automatic driving and target geolocation. However, due to the large variations in foreground texts and background objects, and the diverse text variabilities in shapes, colors, fonts, orientations and scales, along with the extreme illumination and occlusion, text detection in natural scene is still faced with considerable challenges.
近年来,自然场景文本检测因其在场景理解、产品识别、自动驾驶、目标定位等方面的广泛应用而受到广泛关注。然而,由于前景文本和背景对象变化较大,文本在形状、颜色、字体、方向和尺度上的多样性,以及极端的光照和遮挡,自然场景中的文本检测仍然面临着相当大的挑战。
Nevertheless, great progress has been made in recent years with the amazing development of Convolutional Neural Networks (CNNs) [6, 10, 22]. Based on bounding box regression, a list of methodologies [8, 9, 12, 17, 19, 23, 26, 29, 30] has been proposed to successfully locate the text targets in forms of rectangles or quadrangles with certain orientations. Unfortunately, these frameworks cannot detect the text instances with arbitrary shapes (e.g., the curve texts), which also often appear in natural scenes (see Fig. 1 (b)). Naturally, semantic segmentation-based methods can be taken into consideration to explicitly handle the curve text detection problems. Although pixel-wise segmentation can extract the regions of arbitrary-shaped text instances, it may still fail to separate two text instances when they are relatively close, because their shared adjacent boundaries will probably merge them together as one single text instance (see Fig. 1 ©).
然而,近年来随着卷积神经网络(Convolutional Neural Networks, CNNs)的惊人发展,卷积神经网络已经取得了很大的进步[6,10,22]。在bounding box 回归的基础上,提出了一系列方法[8、9、12、17、19、23、26、29、30]来成功定位具有一定方向的矩形或四边形文本目标。不幸的是,这些框架无法检测任意形状的文本实例(例如曲线文本),这些文本实例也经常出现在自然场景中(参见图1 (b))。自然,可以考虑基于语义分段的方法来显式处理曲线文本检测问题。虽然像素分割可以提取任意形状文本实例的区域,但是当两个文本实例相对较近时,仍然可能无法分离,因为它们共享的相邻边界可能会将它们合并为一个文本实例(见图1 ©)。
To address these problems, in this paper, we propose a novel instance segmentation network, namely,Progressive Scale Expansion Network (PSENet). There are two advantages of the proposed PSENet.
针对这些问题,本文提出了一种新的实例分割网络,即渐进比例扩张网络(PSENet)。提出的PSENet有两个优点。
Firstly, as a segmentation-based method, PSENet is able to locate texts with arbitrary shapes. Secondly, we put forward a progressive scale expansion algorithm, with which the closely adjacent text instances can be identified successfully (see Fig. 1 (d)). Specifically, we assign each text instance with multiple predicted segmentation areas. For convenience, we denote these segmentation areas as kernels in this paper and for one text instance, there are several corresponding kernels. Each of the kernels shares the similar shape with the original entire text instance, and they all locate at the same central point but differ in scales. To obtain the final detections, we adopt the progressive scale expansion algorithm. It is based on Breadth-First-Search (BFS) and is composed of 3 steps: 1) starting from the kernels with minimal scales (instances can be distinguished in this step); 2) expanding their areas by involving more pixels in larger kernels gradually; 3) finishing until the largest kernels are explored.
首先,作为一种基于分段的方法,PSENet能够对任意形状的文本进行定位。其次,我们提出了一种渐进比例扩张算法,利用该算法可以成功地识别出相邻的文本实例(见图1 (d))。具体来说,我们为每个文本实例分配多个预测的分割区域。为了方便起见,本文将这些分割区域表示为内核,对于一个文本实例,有几个相应的内核。每个内核的形状都与原始的整个文本实例相似,它们都位于相同的中心点,但是大小不同。
为了得到最终的检测结果,我们采用了渐进比例扩张算法。它基于广度优先搜索(BFS),由3个步骤组成:
1)从规模最小的内核开始(实例可在此步骤中区分);
2)通过在更大的内核中逐渐包含更多的像素来扩展它们的区域;
3)直到最大的内核被开发出来。

图1:不同方法的结果,最好以彩色显示。
(a)为原始图像。
(b)为基于边界框回归方法的结果,红色框几乎覆盖了绿色框中一半以上的上下文,检测结果令人失望。
©是语义分割的结果,由于边界像素部分相连,将3个文本实例误认为1个实例。
(d)是我们提出的PSENet的结果,它成功地区分和检测了4个独特的文本实例。
The motivations of the progressive scale expansion are mainly of four folds. Firstly, the kernels with minimal scales are quite easy to be separated as their boundaries are far away from each other. Therefore, it overcomes the major drawbacks of the previous segmentation-based methods; Secondly, the largest kernels or the complete areas of text instances are indispensable for achieving the final precise detections; Thirdly, the kernels are gradually growing from small to large scales, and thus the smoonth surpervisions would make the networks much easier to learn; Finally, the progressive scale expansion algorithm ensures the accurate locations of text instances as their boundaries are expanded in a careful and gradual manner.
渐进的比例扩张的动因主要有四方面:
首先,最小尺度的核由于边界距离较远,很容易被分离。因此,它克服了以往基于分段的方法的主要缺点;
其次,最大的内核或完整的文本实例区域对于实现最终的精确检测是必不可少的;
第三,网络的核逐渐从小尺度向大尺度发展,因此,smoonth超视域使得网络的学习更加容易;
最后,渐进比例扩张算法保证了文本实例的精确位置,因为文本实例的边界被小心而渐进地扩展。
To show the effectiveness of our proposed PSENet, we conduct extensive experiments on three competitive benchmark datasets including ICDAR 2015 [13], ICDAR 2017 MLT [27] and SCUTCTW1500 [18]. Among these datasets, SCUT-CTW1500 is explicitly designed for curve text detection, and on this dataset we surpass the previous state-of-the-art result by absolute 6.37%. Furthermore, the proposed PSENet achieves better or at least comparable performance on the ordinary quadrangular text datasets: ICDAR 2015 and ICDAR 2017 MLT, when compared with the existing state-of-the-art methods.
为了证明我们提出的PSENet的有效性,我们对ICDAR 2015[13]、ICDAR 2017 MLT[27]和SCUTCTW1500[18]三个具有竞争力的基准数据集进行了广泛的实验。在这些数据集中,SCUT-CTW1500是专门为曲线文本检测而设计的,在该数据集上,我们以绝对6.37%的优势超过了之前的最先进的结果。此外,与现有的最先进的方法相比,本文提出的PSENet在普通四边形文本数据集ICDAR 2015和ICDAR 2017 MLT上实现了更好的性能,或者至少可以与之媲美。
The main contributions of this paper are as follows:
- We propose a novel Progressive Scale Expansion Network (PSENet) which can precisely detecttext instances with arbitrary shapes.
- We propose a progressive scale expansion algorithm which is able to accurately separate the textinstances standing closely to each other.
- Our proposed PSENet significantly surpasses the state-of-the-art methods on the curve text detectiondataset SCUT-CTW1500. Furthermore, it also achieves competitive results on the regular quadrangular text benchmarks: ICDAR 2015 and ICDAR 2017 MLT.
该文章主要贡献如下:
- 提出了一种新型的渐进比例扩张网络(PSENet),它可以精确地检测任意形状的文本实例。
- 提出了一种渐进比例扩张算法,该算法能够准确地分离相邻的文本实例
- 我们提出的PSENet算法明显超过了SCUT-CTW1500曲线文本检测数据集的最新方法。在常规四边形文本基准上:ICDAR 2015和ICDAR 2017 MLT也取得了比较好的结果。
2 Related Work
Text detection has been an active research topics in computer vision for a long period of time. [15, 29] successfully adopted the pipelines of object detection into text detection and obtained good performance on horizontal text detection. After that, [8, 9, 12, 17, 23, 30] took the orientation of text line into consideration and made it possible to detect arbitrary-oriented text instances. Recently,[19] utilized corner localization to find suitable irregular quadrangles for text instances. The detection manners are evolving from horizontal rectangle to rotated rectangle and further to irregular quadrangle. However, besides the quadrangular shape, there are many other shapes of text instances in natural scene. Therefore, some researches began to explore curve text detection and obtained certain results. [18] tried to regress the relative positions for the points of a 14-sided polygon. [31] detected curve text by locating two end points in the sliding line which slides both horizontally and vertically. A fused detector was proposed in [1] based on bounding box regression and semantic segmentation. However, since their current performances are not very satisfied, there is still a large space for promotion in curve text detection, and the detectors for arbitrary-shaped texts still need more explorations.
文本检测一直是计算机视觉领域的一个活跃研究课题。[15,29]成功地将目标检测应用到文本检测中,在水平文本检测中取得了良好的性能。之后,[8、9、12、17、23、30]考虑了文本行方向,使得检测任意方向的文本实例成为可能。最近,[19]利用角定位为文本实例找到合适的不规则四边形。检测方式由水平矩形演变为旋转矩形,进而演变为不规则四边形。然而,在自然场景中,除了四边形外,还有许多其他形状的文本实例。因此,一些研究开始探索曲线文本检测,并取得了一定的成果。[18]试图还原一个14边多边形各点的相对位置。[31]通过在水平和垂直滑动的滑动线上定位两个端点来检测曲线文本。提出了一种基于边界盒回归和语义分割的[1]融合检测器。但是,由于它们目前的性能还不是很理想,曲线文本检测还有很大的提升空间,任意形状文本的检测器还需要进一步的探索。
3 Proposed Method
In this section, we first introduce the overall pipeline of the proposed Progressive Scale Expansion Network (PSENet). Next, we present the details of progressive scale expansion algorithm, and show how it can effectively distinguish the adjacent text instances. Further, the way of generating label and the design of loss function are introduced. At last, we describe the implementation details of PSENet.
在本节中,我们首先介绍所提议的渐进比例扩张网络(PSENet)的总体结构。接下来,我们详细介绍了渐进式比例扩张算法,并展示了它如何有效地区分相邻的文本实例。进一步介绍了标签的生成方法和损失函数的设计。最后介绍了PSENet的实现细节。
3.1 Overall Pipeline

我们总体结果的说明。左边的部分是由FPN[16]实现的。右侧为特征融合和逐步尺度扩展算法。
有关FPN:
https://blog.csdn.net/u014380165/article/details/72890275
https://blog.csdn.net/quincuntial/article/details/80152314
3.1 Overall Pipeline

所提出的PSENet的总体结构如图2所示。受FPN[16]的启发,我们将低级特征映射与高级特征映射连接起来,从而得到了四个级联的特征映射。这些映射在F中进一步融合为了编码各种接受视图的信息。直观地说,这种融合很可能促进具有不同规模的内核的生成。然后将特征图F投影到n个分支中,得到多个分割结果S1;S2;:::;Sn。每个Si都是在一定范围内所有文本实例的一个分割掩码。不同分割掩模的尺度由超参数决定,超参数将在第3.3节中讨论。在这些掩码中,S1给出了尺度最小的文本实例的分割结果,最小核数),Sn表示原始分割掩码(即最大内核)。在得到这些分割掩码后,我们使用渐进尺度展开算法将S1中的所有实例内核逐步展开到Sn中的完整形状,最终得到的检测结果为R。
3.2 Progressive Scale Expansion Algorithm

图3:逐步缩放算法的实现过程。CC是指查找连接组件的功能。EX表示尺度展开算法。
(a)、(e)和(f)分别为S1、S2和S3。(b)为初始连接组件。
©和(d)是扩张的结果。(g)显示扩展的说明。(g)中的红色框表示冲突像素。


如图1 ©所示,基于分段的方法很难将相邻的文本实例分离出来。为了解决这一问题,我们提出了渐进尺度展开算法。下面是一个生动的例子(见图3),它解释了递进尺度展开算法的过程,其核心思想来自广度优先搜索(BFS)算法。在例子中,我们有3个分割结果S = S1;S2;S3g(见图3 (a), (e), (f))。首先,基于最小核映射S1(见图3 (a)), 4个不同的连通分量C = c1;c2;c3;c4可以被找到,作为初始化。图3 (b)中不同颜色的区域分别表示这些不同的连通分量。到目前为止,我们已经拥有了所有文本实例的中心部分(即,最小内核)检测到。然后,我们通过合并S2和S3中的像素逐步扩展检测到的内核。两种尺度展开的结果分别如图3 ©和图3 (d)所示。最后,我们提取图3 (d)中不同颜色标记的连接组件作为文本实例的最终预测。

渐进的比例扩张如图3 (g)所示,扩张基于广度优先搜索算法,该算法从多个内核的像素开始,迭代地合并相邻文本像素。注意,在展开过程中可能会出现像素冲突,如图3 (g)中的红色框所示。在我们的实践中,处理冲突的原则是,在先到先得的基础上,混淆的像素只能被一个单一的内核合并。由于采用了渐进的扩展过程,这些边界冲突不会影响最终的检测和性能。算法1总结了尺度展开算法的具体内容。伪码中,T;P是中间结果。Q是一个队列。Neighbor(.)表示p的相邻像素。GroupByLabel(.)是按标签对中间结果进行分组的函数。Si[q] = True表示Si中像素q的预测值属于文本部分。

需要 Kernels: C, Segmentation Result(分割结果): Si
保证: Scale Expanded Kernels(比例扩张内核): E

1: function EXPANSION(C, Si) 尺度扩张函数
2: T(中间结果) P(中间结果) Q (队列) 置空
3: for循环:对于每一个ci属于C(Kernels)
4: T =T ∪{f符合(p,label)属于ci的像素,标签)}
P =P ∪{符合(像素,标签)属于ci的像素}
5: Enqueue(Q; ci) // 所有 ci中元素 进入队列 Q
6: 结束for循环 end for
7: while当 Q 不为空 do
8: (p; label) =Q中所有元素出队列
9: if 存在q 属于Neighbor§ 并且 q 不属于P and Si[q] = True(Si[q] = True表示Si中像 素q的预测值属于文本部分。)then
10: T =T ∪{(像素,标签)属于ci}
P =P ∪{q}
11: Enqueue(Q; (q; label)) // (q; label) 进去队列 Q
12: end if
13: end while
14: E = GroupByLabel(T) 按标签对中间结果进行分组
15: return E
16: end function
3.3 Label Generation
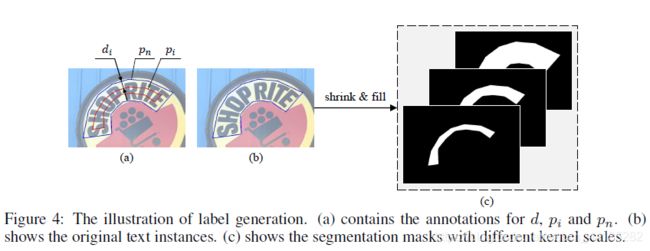
收缩 填充
图4:标签生成的说明。
(a)包含d、pi和pn的注释。
(b)显示原始文本实例。
©显示不同核尺度的分割掩码。

如图2所示,PSENet产生分割结果(如S1;S2;:::;Sn)具有不同的核尺度。因此,在训练过程中也需要不同核尺度下的真实值(ground truths)。在我们的实践中,通过收缩原始文本实例,可以简单而有效地执行这些基本真值标签。图4 (b)中带蓝色边框的多边形表示原始文本实例,对应的是最大的分割标签掩码(见图4 ©中最右边的图)。为了得到图4 ©中依次缩小的掩模,我们利用Vatti裁剪算法[28]将原始多边形pn缩小di像素,得到缩小后的多边形pi(见图4 (a))。然后,将每个收缩后的多边形pi转换成一个0/1的二进制掩码,用于分割标签ground truth。我们将这些地面真值图表示为G1;G2;:::;Gn。从数学上讲,如果我们将比例考虑为ri,则pn与pi之间的边际di可以计算为

比例ri Area计算面积 Perimeter计算周长

m是最小的比例,值在[0,1]
比例的数值(即r1;r2;:::;rn)由两个超参数n和m决定,它们从m线性增加到1。
3.4 Loss Function


学习PSENet,损失函数可以表示为:
![]()
Lc Ls分别表示完整文本实例和收缩文本实例的损失
拉姆达平衡了Lc Ls的重要性
通常情况下文本实例通常只占极小的区域,这使得当使用二进制交叉熵[2]时,预测网络对非文本区域的偏倚。受[20]的启发,我们在实验中采用了骰子系数。骰子系数D(Si;Gi)在公式4。
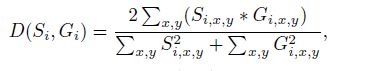
Si,x,y 像素(x,y)在分割结果Si中的值
Gi,x,y 像素(x,y)在真实值Gi中的值
此外,还有许多类似于文本笔画的模式,如fences、lattices,等。因此,为了更好地区分这些模式,我们在训练过程中采用了Online Hard Example Mining (OHEM) [[24]到Lc。
Lc主要对文本和非文本区域进行分割。让我们考虑一下由OHEM是M,因此Lc可以写成
![]()
Ls是收缩文本实例的损失。由于它们被完整文本实例的原始区域所包围,为了避免一定的冗余,我们忽略了分割结果Sn中非文本区域的像素。因此,Ls可以表述为

这里,W是一个掩码,它忽略了Sn中非文本区域的像素,Sn;x;y表示像素(x,y)在Sn中的值
3.5 Implementation Details
