关于CNN行为识别算法的学习记录
最近需要做一点行为识别相关的项目,于是把行为识别类的算法(特别是基于CNN的算法)调研了一遍。
到目前为止,CNN行为识别类的算法主要都是基于双流和3D卷积两种方法,近年来,融合使用光流和C3D的算法逐渐增多(I3D),也有的算法使用了如RGB Diffierence(TSN)或人体关节点等多模态的数据。
评估行为识别算法主要使用的数据集包括:
- UCF-101:最通用的数据集,几乎所有论文都会在UCF-101数据集上进行测试,共有101分类,13320段视频。
-
Kinetic:Deepmind发布的数据集,从youtube视频中截取得到,分为Kinetic-400和Kinetic-600,其中Kinetic-400包含400分类,约300K段视频;Kinetic-600包含600分类,约500K段视频。由于数据规模较大,Kinetic被许多网络选择作为预训练数据集(如I3D)。
-
Something-Something、Jester、Charades等...
截至2018.10,基于CNN的行为识别算法在UCF-101数据集上的准确率可以达到98%(I3D [2017]),速度方面也已经有可以做到实时的算法出现(如ECO [2017],论文中称其处理速度可以达到230+fps)。
接下来将介绍一些我调研到的行为识别算法:
1. 双流网络 (Two-Stream Convolutional Networks)
论文标题:Two-Stream Convolutional Networks for Action Recognition in Videos, 2014
主要贡献:最早的双流网络行为识别。
备注:
1. 提出了two-stream网络,分为空间流网络 (spatial stream convnet) 和时间流网络 (temporal stream convnet),空间流网络使用静止帧图片作为输入,时间流网络使用连续帧间的稠密光流序列作为输入。
在测试时,对于一段给定的视频,采样一定数量的帧(论文中为25),帧间具有相同的时间间隔;然后对于每一帧,通过随机裁剪 (crop) 和翻转 (flip) 得到网络的10个输入;对于每个网络输入,采用RGB图像 (3 * 224 * 224) 作为空间流网络输入,对RGB图像提取后续L个连续帧间的稠密光流序列(2L * 224 * 224)作为时间流网络输入;最后,计算所有输入图像所得分类得分的平均值作为整个视频的分类得分。
如下是作者使用的网络结构:

对于最后的双流信息融合,作者尝试了使用平均值和使用线性SVM分类器的方法。
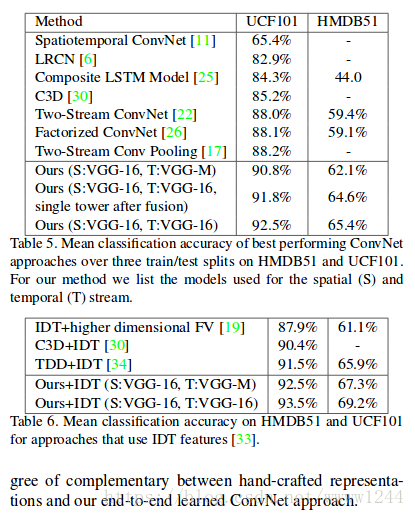
最终,作者在UCF-101和HMDB-51数据集上得到的结果如下图所示:

2. Two-Stream Fusion
论文标题:Convolutional Two-Stream Network Fusion for Video Action Recognition, 2016
项目主页:http://www.robots.ox.ac.uk/~vgg/software/two_stream_action/
github主页:https://github.com/feichtenhofer/twostreamfusion
主要贡献:在双流网络的基础上研究了能够更好融合时空信息的方法
备注:
1. Spatial Fusion
在双流网络中,作者利用平均值或者线性SVM分类器融合空间流网络和时间流网络得到的分类结果(softmax输出),在本文中,作者认为这样的方法不能很好地融合时空信息,于是提出了一些新的fusion策略并测试了不同的fusion策略对网络分类精度的影响:
① Sum:
![]()
② Max:
![]()
③ Concatenation:
![]()
④ Conv:
![]()
⑤ Bilinear:

测试结果如下:

2. Where to fuse
作者尝试了几种不同的方案以修改融合时空信息的位置,下图是其中的两种网络结构:

不同方案的测试结果如下:

3. Temporal Fusion
在双流网络中,作者通过以一定时间间隔采样视频帧作为网络输入,最后对所有帧所得的分类结果取平均值的方法融合时间信息,在本文中,作者尝试了在Spatial Fusion后使用3D Pool和3D Conv的方法,并得到了如下的测试结果:

4. 最后,作者融合了上述方案,得到了最后的测试结果:
3. TSN (Temporal Segment Networks)
论文标题:Temporal Segment Networks: Towards Good Practices for Deep Action Recognition, ECCV 2016
github主页1:https://github.com/yjxiong/temporal-segment-networks (可以训练)
github主页2:https://github.com/yjxiong/tsn-pytorch (可以训练)
主要贡献:
1. 港中文汤晓鸥组的论文,在双流网络的基础上,采用稀疏时间采样策略 (Sparse Temporal Sampling Strategy) 和视频级监督 (Video-Level Supervision),提升了网络处理长时间视频序列的能力;
2. 在传统的RGB图和光流图以外,尝试了新的输入模式,包括RGB、RGB Difference、Optical Flow和Warped Optical Flow;
3. 测试了新的基础网络,例如VGG-16、GoogleNet和BN-Inception。
备注:
1. 稀疏时间采样策略
如下图所示:

将一个视频分成K段 (segment),从每一段中随机采样得到一个片段 (snippet);将片段输入双流网络得到对应的class score;最后,对于所有的class score,通过一个segmental consensus function(例如Max、Average和Weight Average)得到最终的分类结果。
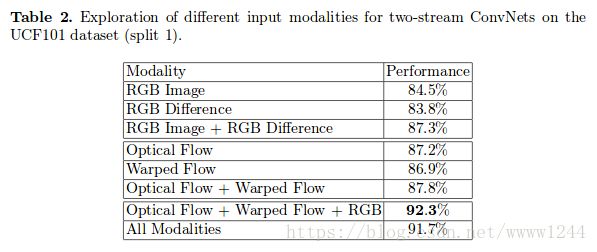
2. 多模态输入
在使用Optical Flow、Warped Optical Flow和RGB三模态输入时,网络的分类精度最高,如下图所示:
3. TSN在UCF-101和HMDB-51数据集上的测试结果如下图所示:

4. TRN (Temporal Relation Network):TSN的改进版本
论文标题:Temporal Relational Reasoning in Videos, ECCV 2018
项目主页:http://relation.csail.mit.edu/
github主页:https://github.com/metalbubble/TRN-pytorch (可以训练)
主要贡献:
1. 使用MLP来表征不同temporal segment的relation;
2. 通过时间维度上的multi-scale特征融合,提高了video-level的鲁棒性。

备注:
1. TRN主要在Something-Something、Jester和Charades三个数据集上进行测试。作者认为这些数据集中的动作具有“较强的方向性” (actions with strong directionality and large, one-way movements),受益于时序信息更加明显。
5. C3D (3D Convolution)
论文标题:Learning Spatiotemporal Features With 3D Convolutional Networks, 2015
项目主页:http://vlg.cs.dartmouth.edu/c3d/
github主页:https://github.com/facebook/C3D (caffe)
备注:
1. C3D工程由Facebook维护,2017年3月更新v1.1版本,提供了基于resnet的新模型。
2. 关于3D卷积
对于2D卷积,设输入图像尺寸为c*w*h,其中c为图像通道数,一般为3;卷积核尺寸为K*3*3*3,stride=1,padding=True,则输出feature-map的尺寸为K*w*h。
对于3D卷积,设输入视频段尺寸为c*l*h*w,其中l为视频序列的长度;卷积核尺寸为K*3*3*3,stride=1,padding=True,则输出feature-map的尺寸为K*l*w*h。

3. 以下是C3D的网络结构,所有卷积层滤波器尺寸均为3*3*3,pool1滤波器尺寸为1*2*2,其它所有pool层滤波器尺寸均为2*2*2。

4. 以下是C3D模型在UCF-101数据集上的测试结果:

6. R(2+1)D
论文标题:A Closer Look at Spatiotemporal Convolutions for Action Recognition, CVPR 2018
github主页:https://github.com/facebookresearch/R2Plus1D (caffe2)
主要贡献:提出使用(2+1)D卷积替代3D卷积,在许多数据集上达到了接近state-of-the-art的效果。
备注:
1. R(2+1)D工程由Facebook维护,主要是对R(2+1)D模型的实现,除此以外,还提供了对C3D以及论文中提到的R2D、R3D、MCx、rMCx等模型的支持。
2. 在本文中,作者提出混合使用2D和3D卷积来提高网络的分类精度;此外,还提出了一种新的卷积结构,将3D卷积操作分解为两个依次进行的卷积操作:2维空间卷积和1维时间卷积,如下图所示:

并据此提出了几种新的模型结构,如下图所示:

另外,作者还将残差网络的思想融入到R(2+1)D模型中,最终设计出的网络结构如下图所示:

3. 以下是使用2D卷积、3D卷积和(2+1)D卷积的各种模型在Kinetic测试结果:

4. 以下是R(2+1)D网络在UCF-101和HMDB-51数据集上的测试结果:

7. I3D (Two-Stream Inflated 3D ConvNet)
论文标题:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset, CVPR 2017
github主页:https://github.com/deepmind/kinetics-i3d(没有开源训练)
主要贡献:将双流网络与3D卷积结合,设计了新的网络结构,在UCF-101数据集上达到了98.0%的识别精度。
备注:
1. 作者对比了几种现有的行为识别框架,并设计了新的方案,如下图e所示:

然后,作者又基于Inception Module设计了新的Inflated Inception-V1网络,如下图所示:

在测试时,RGB图像序列和optical flow序列分别输入两个Inflated Inception-V1网络中,并对两个预测结果取平均值作为总的预测结果。
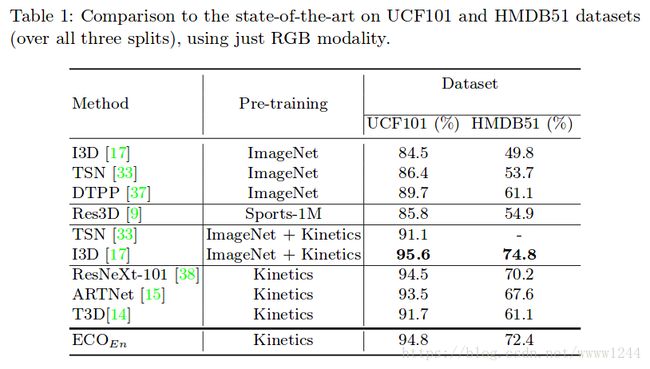
2. 以下是I3D网络在UCF-101和HMDB-51数据集上的测试结果(目前识别精度方面的state-of-the-art):

8. ECO
论文标题:ECO: Efficient Convolutional Network for Online Video Understanding, ECCV 2018
github主页:https://github.com/mzolfaghari/ECO-efficient-video-understanding(提供了一个实时预测的接口)
主要贡献:
1. 采用离散采样的方法减少冗余帧,实现了online video understanding,轻量化网络的处理速度可以达到237帧/秒(ECO Lite-4F,Tesla P100,UCF-101 Accuracy为87.4%)。
2. 使用2D+3D卷积完成帧间信息融合。
备注:
1. 以下是ECO Lite的网络结构:

首先,将一段视频分成等长的N段,再从每一段中随机选取一帧输入网络(S1~SN);输入图像首先经过共享的2D卷积子网络得到96*28*28的feature map,然后输入到一个3D卷积子网络中,得到对应动作类别数目的一维向量。
2. 关于帧间信息融合的部分,作者还尝试了使用2D与3D卷积相结合的方案(ECO Full),如下图所示:

3. 以下是ECO网络在UCF-101和HMDB-51数据集上的测试结果:
以下是网络在运行速度方面的测试结果:

作者还测试了不同版本的ECO模型,结果如下:

参考博客:[论文笔记] 用于在线视频理解的高效卷积网络
https://zhuanlan.zhihu.com/p/36795554