使用faster rcnn训练imageNet上的部分数据集
最近在做毕业设计,需要用到faster rcnn,训练数据使用的是我自己下载的imageNet里的部分数据,主要用到了其中的bike,motorbike,car,bus,train等交通工具。由于imageNet自带了annotation,只是格式和pascal voc不一样,所以还需要转化格式。目前我正在使用imageNet中的ship数据集来进行一个二分类的检测和识别,即background和ship。等这个实验成功之后再进行其他类别的数据转换并进行多类的训练。本文主要记录在进行这个实验时候自己所做的一些工作和查阅资料所获得的帮助,相关参考链接也会在文中贴出来。目前网络还在训练中,结果未知,先将已做的一些工作记录,以供以后自己和大家参考,后续再更新。
我的开发环境是Ubuntu14.04,caffe是必须先要配置好的,这里就不再赘述,网上很多教程。进行该实验之前需要先配置py-faster-rcnn工程,具体参考原作者的github项目(https://github.com/rbgirshick/py-faster-rcnn),写得很清楚,另外该算法还有一个matlab版本(https://github.com/ShaoqingRen/faster_rcnn),要想直接看中文可以参考这一篇博客(http://blog.csdn.net/samylee/article/details/51086153)
运行成功demo.py之后,我们还需要做的是下载pascal voc的数据集,对它进行训练。在项目的github网站也给出了训练的方法,这一步个人感觉必须得做,因为我们后续训练自己的imageNet数据的时候也是模仿pascal voc2007的数据集的格式来的。具体步骤参考原作者的github项目(https://github.com/rbgirshick/py-faster-rcnn),或者博客(http://blog.csdn.net/samylee/article/details/51099508),个人感觉最好看原作者的比较好,道理很简单,谁做的肯定就是谁最清楚怎么回事。
经过以上的参考,配置好py-faster-rcnn并在pascal voc 2007数据集上训练成功应该不成问题。下面讲述如何利用imageNet的某一类数据进行训练。
=======================================我是华丽丽的分割线=========================分割割割割==========================================
首先要下载imageNet2015数据集,贴出百度云链接(http://pan.baidu.com/s/1geEdTeV),总共40G,慢慢下吧,值得提醒的是千万不要为了下载这个求快而去开通百度云会员,不要问为什么,因为我任性,开通过,并没有什么用处,试用的时候能到1m/s,但开通后就打回原形了,个人很鄙视这种近似于欺骗消费者的行为。下载完之后你就可以去里面找你想要的数据了。在imageNet\ILSVRC2015 _DET\Data\DET\train\ILSVRC2013_train\这个目录下面可以看到
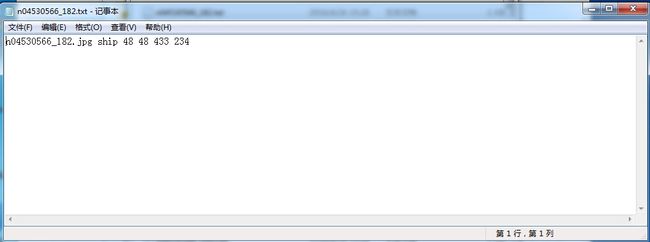
每个子目录对应一种类别,具体怎么知道对应关系可以查看imageNet\ILSVRC2015_devkit\devkit\data\map_clsloc.txt文件,我按照这个文件找到了ship这一类别,每个类别对应的annotation在imageNet\ILSVRC2015 _DET\Annotations\DET\train\ILSVRC2013_train\目录下找到。现在我们要做的是怎么把ship的图片xml文件转化为pascalvoc的格式,我这里采用了比较笨的方法,参考这篇http://blog.csdn.net/samylee/article/details/51201744,他是将每个图片的数据写成了一个txt文件,然后用txt转化为xml文件。我模仿这种方法,那么我得先获得txt文件,所以现在的第一步是要将我的imageNet的annotation,即xml文件转化为参考博客所提到的txt文件,如下图所示的格式,值得注意的是下
四个坐标的顺序依次为xmin,ymin,xmax,ymax。而pascal voc的格式是xmin,xmax,ymin,ymax,转化的时候需要注意。先在m文件当前目录下创建名为JPEGImage和labels的文件夹,以及一个JPEGImage1的文件夹。创建这个文件夹的原因是imageNet上的格式是.JPEG,而pascal的是.jpg,为了和它保持一致,我们先将所有图片转化为.jpg,并存在JPEGImage1文件夹中。首先将所有源图片放入JPEGImage文件夹中。然后贴出将.JPEG转化为.jpg文件的m代码:
path_image='JPEGImages/';
path_image1='JPEGImages1/';
file_all = dir(path_image);
for i = 3:length(file_all)
JPEGPath = [path_image,file_all(i).name];
fprintf('JPEGPath = %s\n',JPEGPath)
img = imread(JPEGPath);
jpgPath = [path_image1,file_all(i).name(1:end-5),'.jpg'];
fprintf('jpgPath = %s\n',jpgPath)
imwrite(img,jpgPath)
end
然后你可以将原JPEGImage文件删除,并将新生成的JPEGImage1改名为JPEGImage即可。
贴出将imageNet的xml转化为txt的matlab代码,以供参考,代码可能不能直接运行,因为这和你所存图片和xml文件的目录有关系,具体的自己稍微看下应该就能解决。
%createtxt.m
path_image='JPEGImages/';%源图片存放路径
path_label='labels/';%txt文件存放路径
files_all=dir(path_image);
for i = 3:length(files_all)
sprintf('i = %d',i)
clear rec;
pathSrcXml = ['./n04530566/' files_all(i).name(1:end-4) '.xml'];%这是imageNet某一类别的xml文件的目录
sprintf('%s', pathSrcXml)
pathtxt = ['./labels/' files_all(i).name(1:end-4) '.txt'];
sprintf('%s', pathtxt)
str = fileread( pathSrcXml );
v = xml_parse( str );
xmin = v.object.bndbox.xmin
ymin = v.object.bndbox.ymin
xmax = v.object.bndbox.xmax
ymax = v.object.bndbox.ymax
filename = v.filename
%filename =
fid = fopen(pathtxt,'wt')
fprintf(fid,'%s%s',filename,'.jpg')
fprintf(fid,'%c',' ');
fprintf(fid,'%s','ship')
fprintf(fid,'%c',' ');
fprintf(fid,'%c',xmin);
fprintf(fid,'%c',' ');
fprintf(fid,'%c',ymin);
fprintf(fid,'%c',' ');
fprintf(fid,'%c',xmax);
fprintf(fid,'%c',' ');
fprintf(fid,'%c',ymax);
fclose(fid);
end
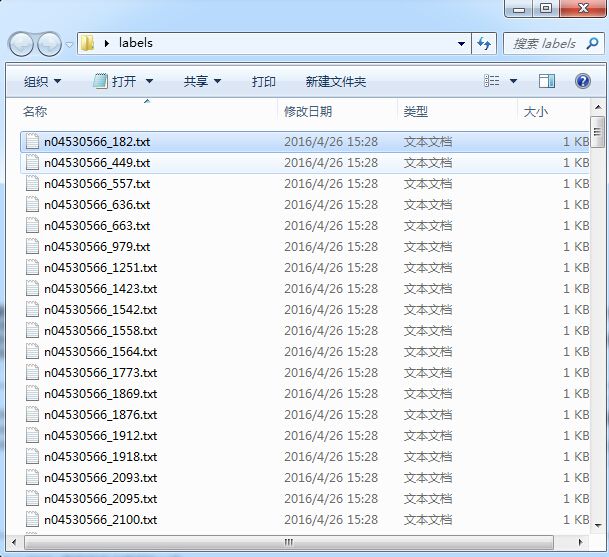
以上代码有一个xml_parse(str),这是解析xml文件用的,我之前用matlab里面自带的xmlread()函数感觉总是不能达到我想要的效果,即我只要读出一个xml文件到一个对象object中,我就可以用object.字段名.字段名这种方式来访问xml的数据,后来上网找了下资料发现这么个工具箱能够实现我想要的功能,贴出百度云链接http://pan.baidu.com/s/1nvaSrn7,我的matlab是2012,运行这个工具箱会有warning,因为这是老版本的工具箱了,但是不影响使用,具体使用方法参考里面的test文件夹就可秒懂。经过以上步骤即可在labels文件夹中生成每个imageNet的xml文件对应的txt文件。如下图所示:
每个txt里面如下图所示:
接下来就可以进行将txt转化为pascal voc格式的xml文件了,在当前目录下创建一个Annotations的文件夹,代码在百度云链接中:http://pan.baidu.com/s/1hrKN1Es,自己稍微琢磨下就能看懂。
小结:经过以上步骤,就能获得一个JPEGImage的文件夹,里面存的是.jpg后缀的源图片,和一个Annotations的文件夹,里面存的是每个源图片对应的pascal voc格式的xml文件,labels文件夹可以不用了,因为voc数据集本来就没有这个东西,他只是我们用来过度的一个文件夹。我们还差什么?imageSets文件夹,如何生成四个txt文件,贴出代码:
%createimagesets.m
file = dir('Annotations');
len = length(file)-2;
num_trainval=sort(randperm(len, floor(9*len/10)));%trainval集占所有数据的9/10,可以根据需要设置
num_train=sort(num_trainval(randperm(length(num_trainval), floor(5*length(num_trainval)/6))));%train集占trainval集的5/6,可以根据需要设置
num_val=setdiff(num_trainval,num_train);%trainval集剩下的作为val集
num_test=setdiff(1:len,num_trainval);%所有数据中剩下的作为test集
path = 'ImageSets\Main\';
fid=fopen(strcat(path, 'trainval.txt'),'a+');
for i=1:length(num_trainval)
s = sprintf('%s',file(num_trainval(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\r\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'train.txt'),'a+');
for i=1:length(num_train)
s = sprintf('%s',file(num_train(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\r\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'val.txt'),'a+');
for i=1:length(num_val)
s = sprintf('%s',file(num_val(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\r\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'test.txt'),'a+');
for i=1:length(num_test)
s = sprintf('%s',file(num_test(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\r\n']);
end
fclose(fid);
这样所需的文件夹我们都已备齐,将imageSets,Annotations和JPEGiImage文件夹分别放入voc数据集的对应位置,在这之前先将其原来的文件夹删除。
以上是准备自己的数据集部分,后续还涉及到修改配置文件以及训练部分,在下一篇博客更新。