Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks论文笔记
论文链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
摘要:
最先进的目标检测网络依赖于候选区域提取算法来假设目标位置。SPPnet和Fast R-CNN网络等技术的进步降低了这些检测网络的运行时间,也暴露了基于候选区域算法的计算瓶颈。在这篇文章中,作者引入了一个与检测网络共享全图像卷积特征的候选区域生成网络(RPN),几乎不需要计算代价生成候选区域。R-CNN是采用selective search方法来生成候选区域,比较耗时。RPN是一个全卷积的网络,它同时预测每个位置的目标边界框和目标的得分。对RPN进行端到端训练,生成高质量的候选区域,这些候选区域可以被Fast R-CNN用来做目标检测。作者通过共享它们的卷积特征将RPN和Fast R-CNN合并到一个单一的网络,类似于现在神经网络中的注意力机制,RPN告诉网络在哪个区域有待检测的目标。对于VGG-16模型,Faster R-CNN检测系统在GPU上的帧率为5fps(包括所有步骤),同时在PASCAL VOC 2007、2012和MS COCO数据集上实现了最先进的目标检测精度,每张图像只有300个候选区域。在ILSVRC和COCO 2015年的比赛中,Faster R-CNN和RPN是在多个比赛获得第一名的基础。
思路:
基于候选区域的目标检测算法取得了很好地性能,但是计算非常耗时,从最开始的R-CNN,selective search方法生成候选区域,逐个提取每个候选区域的特征向量,到Fast R-CNN将逐个计算每个候选区域特征改进为全图一次性计算并结合RoI获取每个候选区域的特征向量,极大提高了计算效率。但是selective search方法生成候选区域也是很耗时的,已经变成了基于候选区域目标检测算法计算效率的瓶颈。分析原因,selective search方法是运行在CPU上的,并行计算效率很低,而CNN可以在GPU上加速,如果使用CNN来生成候选区域并且放到GPU上加速,是一个不错的解决方案,但是,单独用一个CNN来生成候选区域会忽略后面的检测网络,错过共享计算的重要机会。所以作者提出了RPN来替代selective search方法,通过共享目标检测的主干网络,RPN生成候选区域几乎不需要计算代价,处理一张图仅需10毫秒。RPN为了能在有效的预测出不同尺度和宽高比的目标,采用了anchor框的方法,和图像金字塔实现多尺度检测不同,RPN在特征图的每个位置都检测几个不同的anchor框中是否含有目标。避免了枚举多个尺度或纵横比的图像或卷积核。因为刚开始两个分支(RPN和检测器)都不具备检测目标的功能,仅仅能提取特征,但是如果要训练检测器,则RPN要先能生成候选区域,如果先训练RPN,那么RPN训练好的主干网络特征会被检测器破坏,导致主干网络提取的特征没法共享,就是说要不偏向RPN,要不偏向检测器。作者提出了交替训练两个分支,这样做,就可以让主干网络既学到有利于生成RPN的特征,又有利于检测器的特征,实现了权重共享,也使训练更稳定。通过RPN,Faster R-CNN完全抛弃了selective search方法,使得生成一张图像候选区域仅需10ms。测试时可以达到5帧每秒。
Faster R-CNN:

Faster R-CNN有两个子模块构成,一个是RPN,用于生成图像候选区域,一个是Faster R-CNN检测器,用来检测目标。结构如图2所示。实际上这个RPN和注意力机制的功能一样,告诉网络应该重点关注特征图的哪一部分,对于检测任务来说当然是包含目标区域的地方才是需要关注的,而这个区域就是候选区域。Faster R-CNN检测器则在RPN生成的候选区域上对目标进行更精确的回归和分类。
Region Proposal Networks :

RPN网络输入一张图像,输出一系列边界框和每个边界框对应的分数(这个分数用来区分这个区域是属于背景还是目标区域)。因为RPN是共享了主干网络,所以在共享网络的最后一层,使用一个小网络以滑动窗口的形式来提取主干网络输出的特征。小网络的输入就是取自主干网络最后一层输出特征图的nxn窗口,然后将该窗口的特征映射成一个低维特征,要注意的是,这个小网络是全卷积神经网络,所以低维特征的维度等于特征图的通道数。然后将这个低维的特征输入两个1x1卷积的小分支,一个用于生成候选区域的目标框,一个用于预测该目标框的分数。
Anchors:
作者提出这个是为了在同一个窗口位置能同时预测K个不同比例的区域,这篇论文K=9,三个尺度,每个尺度三个比例,总共9个anchors,生成的目标框和得分也是K个,所以有2K个分数(背景分数和含有目标的分数)4K个坐标位置(每个框含有4个坐标),因为在特征图的每个位置都会生成K个anchor,所以对于HxW的特征图,共有HWK个anchors。每个anchor中心都位于滑动窗口的中心,坐标是相对于该中心位置的偏移。
Translation-Invariant Anchors:
作者说他们提出的Anchors具有变换不变性,是因为作者选取的Anchors是固定的9种Anchors,也就意味着根据Anchors生成候选区域的函数,也就这9种,所以不管图像中的目标如何变换,总有一个Anchors能匹配到。而根据聚类算法计算出来的Anchors,是不具备这种性质的,对于一些形状很少见的目标,可能就无法匹配到Anchors了,因为聚类得到的Anchors,主要是针对常出现的目标形状。换言之就是,作者提出的Anchors,覆盖范围广,不管目标怎么变换,都能覆盖,所以翻译过来应该叫对变换不敏感的Anchors。当然这种做法也是有缺点的,就是如果目标形状都集中在某个尺寸,就会浪费很多Anchors,同时也导致某个尺寸的Anchors不够用。比如数据集中全是一些小目标,那么那些尺度较大的Anchors就匹配不到候选区域了。尺度不变性带来的另一好处就是计算效率高, MultiBox有![]() 维度全连接输出层,
维度全连接输出层,![]() 的参数量,而Faster R-CNN仅仅有
的参数量,而Faster R-CNN仅仅有![]() 维度全连接层输出,
维度全连接层输出,![]() 的参数量,大大降低了计算效率。参数量也小,这降低了在较小数据集上过拟合的风险。1536和512和主干网络有关。
的参数量,大大降低了计算效率。参数量也小,这降低了在较小数据集上过拟合的风险。1536和512和主干网络有关。
Multi-Scale Anchors as Regression References:

作者使用多个尺度的Anchors来解决目标尺度不同的问题,在这之前,有两种方法来处理多尺度问题,如图1,一个是图像金字塔,即将图像缩放到不同的尺寸,用于网络训练,做法很直观,效果不错,但是很耗时,缩放图像涉及到各种矩阵插值操作。二是使用卷积核金字塔,即使用不同的卷积核在特征图上提取特征,通常卷积核的大小(也叫滑动窗口)就代表了网络的感受野,如果用一样尺寸的卷积核,比如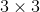 ,如果一个目标的形状是
,如果一个目标的形状是![]() ,就有点管中窥豹的感觉,提取到的特征仅仅是局部的。所以卷积核金字塔采用不同尺寸的卷积核,这样就能全方位提取特征了。第二种方法场合第一种方法一起使用。作者提出的方Anchors金字塔,使用不同尺度的Anchors来提取不同尺度目标的特征,这种方法不需要缩放图像,也不需要不同尺度的卷积核,计算效率高。
,就有点管中窥豹的感觉,提取到的特征仅仅是局部的。所以卷积核金字塔采用不同尺寸的卷积核,这样就能全方位提取特征了。第二种方法场合第一种方法一起使用。作者提出的方Anchors金字塔,使用不同尺度的Anchors来提取不同尺度目标的特征,这种方法不需要缩放图像,也不需要不同尺度的卷积核,计算效率高。
Loss Function:
首先选取正负样本,正样本:和某个真实标注框iou最大的Anchors或者iou大于0.7的。负样本:和某个真实标注框iou低于0.3的,其它的既不是正样本也不是负样本的Anchors不参与训练,因为对训练没有帮助。类别分为:背景和有目标区域,二分类问题。损失函数如下:
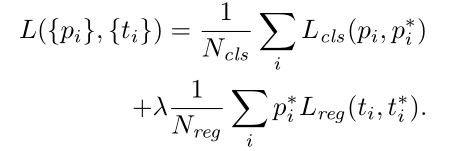
这是一个多任务损失,一个是类别预测损失,一个是位置坐标损失,和Fast R-CNN一样。 其中i表示每个anchor, 表示预测的结果,表示是否是背景,
表示预测的结果,表示是否是背景,![]() 表示真实标注,即正负样本,当时正样本时为1,否则为0。
表示真实标注,即正负样本,当时正样本时为1,否则为0。 表示边框预测的结果,
表示边框预测的结果,![]() 表示边框的真实标注。
表示边框的真实标注。 用于平衡这两个任务的损失,取值应该使两个任务损失值基本平衡。
用于平衡这两个任务的损失,取值应该使两个任务损失值基本平衡。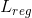 表示
表示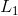 损失函数,即绝对值。对于边框回归的四个位置参数计算如下:
损失函数,即绝对值。对于边框回归的四个位置参数计算如下:

其中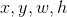 分别表示边框的中心坐标和宽高。
分别表示边框的中心坐标和宽高。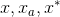 分别表示预测出的边框,anchor框和真实标注的边框。可以看出这是anchor到最近的真实边框的回归,即通过一个与目标有最大iou的anchor,将预测值尽可能接近真实值。
分别表示预测出的边框,anchor框和真实标注的边框。可以看出这是anchor到最近的真实边框的回归,即通过一个与目标有最大iou的anchor,将预测值尽可能接近真实值。
训练RPNs :
通过反向传播来训练RPN,每个batch的输入来自同一张图,然后计算所有anchor的损失,为了是样本平衡,正负样本取样为1:1,如果正样本不够,则用负样本补充。除了共享的主干网络用在ImageNet训练预训练的参数,其它层的参数用均值为0,偏差为0.01的高斯分布初始化。在PASCAL VOC数据集中,60k个batch使用0.001的学习率,再堆20k个batch使用0.0001的学习率。使用0.9的动量和0.0005权重衰减。
RPN 和Fast R-CNN 共享特征:
如果单独训练这两个网络,那么这两个网络就不能共享特征,所以作者提出了三种训练策略,交替训练,近似联合训练和非近似联合训练。作者采用的是交替训练。
实验结果: