python中数组与链表的总结与实现
- 引言
- 关于数组
- numpy的含义以及优劣势
- 问题一:关于数组的动态扩容以及增删改查
- 问题二:实现两个有序数组合并为一个有序数组
- 关于链表
- 问题一:实现单链表与双向链表
- 问题二:合并两个有序链表
引言
已经有两个礼拜没有更文了,算是我从开始在csdn写到现在最久的一次,最近事情很多。那么话不多说,让我们进入正题。
关于数组
数组应该是数据结构里用得最频繁的,也是构建其它复杂类型的结构,这里我就不再过多说明了,只想提一点,因为我的博客主要是以python为主,但python的基础模块中是没有数组这种数据结构的,用了列表来代替。如果我们需要用数组的话,需要导入数据分析的模块,没错,就是numpy,下面我就来介绍一下numpy中的数组以及它与列表的区别。
numpy的含义以及优劣势
NumPy是高性能科学计算和数据分析的基础包。部分功能如下:
- ndarray, 具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能。
- 用于集成C、C++、Fortran等语言编写的代码的工具。
我们可以看下面的图:
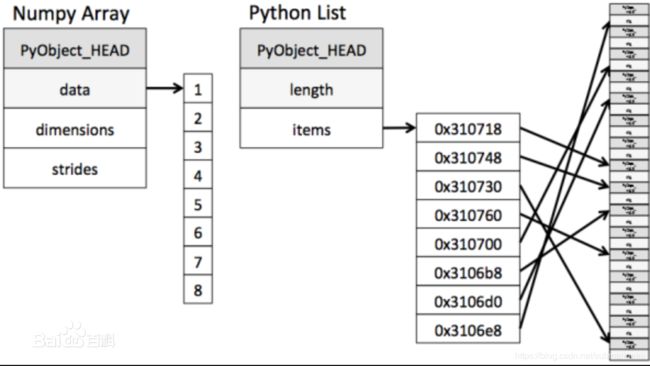
这张图来自百度百科,我们可以发现的是array类型数据存储方式是连续的,并且直接指代,而列表的线反而显得杂乱无章,还需要通过寻址来存储,这就导致了numpy在计算的时候虽然类型单一,但没有太多循环的限制,还有可执行向量化操作与解决了GIL全局解释器锁,都给它的速度带来了质的飞越。
另外我记得在看哪本书中提到过,python列表实际上是数组,具体来说,它们是具有指数过度分配的动态数组,可分离的顺序表。python创始人龟叔在编写cpython解释器的过分分配非常保守,只给了1.125倍的速率,这在大部分语言里,是比较低的。
(书不记得哪本了,翻找了很多的资料,在quora上找到一个讨论帖,可以一看 How-are-Python-lists-implemented-internally)
关于numpy的缺点,可以看这篇博文:
numpy 矩阵运算的陷阱
如果还想看后面更多的关于numpy的内容,可以看我之前写的:
numpy总结与思维导图
问题一:关于数组的动态扩容以及增删改查
这个问题其实在python中是不用和C一样大费周章的,python提供的list和字典是可变类型,就像我上面提到的,本身就是一个过度分配的动态数组。所以它的增删改查,我大概画了一个流程图,可以完成基本的所有操作,而如果想要了解底层编译方式,就需要查看CPython解释器了解它的组成,我找到了一篇译文,可以参考如下链接,以及我画的思维导图:

Python中list的实现
问题二:实现两个有序数组合并为一个有序数组
这个问题如果是没有提出任何要求的话,我们能想到的一种很简单的方式就是用extend与set组合起来,那么两行就可以搞定。或者使用for循环代替set,达到去重的目的,但突然被告知是leetcode里的题,然后过去看了下,题目为:
给定两个有序整数数组 nums1 和 nums2,将 nums2 合并到 nums1 中,使得 num1 成为一个有序数组。
说明:
初始化 nums1 和 nums2 的元素数量分别为 m 和 n。
你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
然后看了几分钟,没有审清题目,参数太多漏看了一些内容,然后有点懵逼,看了下解题思路才发现原来是这个样子啊,具体是哪些地方傻逼了我就不解释了。。。然后这题空间有没有其实都没啥太大关系,还是承接上面的思路,我extend拼接是可以做的:
class Solution:
def merge(self,nums1,nums2):
"""
Do not return anything, modify nums1 in-place instead.
"""
nums1.extend(nums2)
nums1 = sorted(nums1)
return nums1
nums1 = [1,2,3]
nums2 = [2,5,6]
a = Solution()
print(a.merge(nums1, nums2))
而如果是要用到m和n参数,这里就是将extend换成了nums1[m:] = nums2,这种思路就不提了,另外看到一个比较好的解题方案,加了点注释在这里分享一下:
class Solution:
def merge(self, nums1, m, nums2, n):
while m>0 and n>0:
if nums1[m-1]>nums2[n-1]:#若nums1中最后一个元素大于nums2[]中最后一个元素
nums1[m+n-1]=nums1[m-1]#则扩展后的列表最后一个元素是俩元素中最大的
m-=1 #nums1中元素-1
else:
nums1[m+n-1]=nums2[n-1]
n-=1
if n>0:#若nums1完了,nums2还没完
nums1[:n]=nums2[:n]#把剩下nums2加在最开始
关于链表

关于链表,我也不再做过多说明了,上图说得比较明白了,那么需要完成的也就是如上的操作总结内容。
问题一:实现单链表与双向链表
这里我就不想画图了,参考了 数组、单链表和双链表介绍 以及 双向链表的C/C++/Java实现 的图和过程,以及《python面试宝典》一书中的代码思路。
单向链表:
单向链表(单链表)是链表的一种,它由节点组成,每个节点都包含下一个节点的指针。
单链表的示意图如下:

表头为空,表头的后继节点是"节点10"(数据为10的节点),“节点10"的后继节点是"节点20”(数据为10的节点),…
单链表删除节点

删除"节点30"
删除之前:“节点20” 的后继节点为"节点30",而"节点30" 的后继节点为"节点40"。
删除之后:“节点20” 的后继节点为"节点40"。
单链表添加节点

在"节点10"与"节点20"之间添加"节点15"
添加之前:“节点10” 的后继节点为"节点20"。
添加之后:“节点10” 的后继节点为"节点15",而"节点15" 的后继节点为"节点20"。
单链表的特点是:节点的链接方向是单向的;相对于数组来说,单链表的的随机访问速度较慢,但是单链表删除/添加数据的效率很高。
class Node(object):
def __init__(self, data):
# 数据域
self.data = data
# 向后的引用域
self.next = None
class SingleLinkList(object):
def __init__(self):
self.head = None
# is_empty() 链表是否为空
def is_empty(self):
return not self.head
# add(data) 链表头部添加元素
# O(1)
def add(self, data):
node = Node(data)
node.next = self.head
self.head = node
# show() 遍历整个链表
# O(n)
def show(self):
cur = self.head
while cur != None:
# cur是一个有效的节点
print(cur.data, end=' --> ')
cur = cur.next
print()
# append(item) 链表尾部添加元素
# O(n)
def append(self, data):
cur = self.head
while cur.next != None:
cur = cur.next
# cur指向的就是尾部节点
node = Node(data)
cur.next = node
# length() 链表长度
# O(n)
def length(self):
count = 0
cur = self.head
while cur != None:
# cur是一个有效的节点
count += 1
cur = cur.next
return count
# search(item) 查找节点是否存在
# O(n)
def search(self, data):
cur = self.head
while cur != None:
if cur.data == data:
return True
cur = cur.next
return False
# remove(data) 删除节点
# O(n)
def remove(self, data):
cur = self.head
pre = None
while cur != None:
if cur.data == data:
if cur == self.head:
self.head = self.head.next
return
pre.next = cur.next
return
pre = cur
cur = cur.next
# insert(index, data) 指定位置添加元素
# O(n)
def insert(self, index, data):
if index <= 0:
self.add(data)
return
if index > self.length() - 1:
self.append(data)
return
cur = self.head
for i in range(index-1):
cur = cur.next
# cur指向的是第index节点第前置节点
node = Node(data)
node.next = cur.next
cur.next = node
双向链表:
双向链表(双链表)是链表的一种。和单链表一样,双链表也是由节点组成,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
双链表的示意图如下:

表头为空,表头的后继节点为"节点10"(数据为10的节点);“节点10"的后继节点是"节点20”(数据为10的节点),“节点20"的前继节点是"节点10”;“节点20"的后继节点是"节点30”,“节点30"的前继节点是"节点20”;…;末尾节点的后继节点是表头。
双链表删除节点

删除"节点30"
删除之前:“节点20"的后继节点为"节点30”,“节点30” 的前继节点为"节点20"。“节点30"的后继节点为"节点40”,“节点40” 的前继节点为"节点30"。
删除之后:“节点20"的后继节点为"节点40”,“节点40” 的前继节点为"节点20"。
双链表添加节点

在"节点10"与"节点20"之间添加"节点15"
添加之前:“节点10"的后继节点为"节点20”,“节点20” 的前继节点为"节点10"。
添加之后:“节点10"的后继节点为"节点15”,“节点15” 的前继节点为"节点10"。“节点15"的后继节点为"节点20”,“节点20” 的前继节点为"节点15"
class Node(object):
#节点的类
def __init__(self,item):
self.item = item
self.prev = None
self.next = None
class DLinkList(object):
#双向链表的类
def __init__(self):
#指向链表的头节点
self.head = None
def is_empty(self):
#链表是否为空
return self.head == None
def length(self):
#链表长度
cur = self.head
#计数器
count = 0
while cur != None:
count += 1
cur = cur.next
return count
def travel(self):
#遍历链表
cur = self.head
while cur != None:
print(cur.item)
cur = cur.next
def add(self,item):
#链表头部添加
node = Node(item)
if self.is_empty():
#如果是空链表,将head指向node
#给链表添加第一个元素
self.head = node
else:
#如果链表不为空,在新的节点和原来的首节点之间建立双向链接
node.next = self.head
self.head.prev = node
#让head指向链表的新的首节点
self.head = node
def append(self,item):
#链表尾部添加
#创建新的节点
node = Node(item)
if self.is_empty():
#空链表,
self.head = node
else:
#链表不为空
cur = self.head
while cur.next != None:
cur = cur.next
#cur的下一个节点是node
cur.next = node
#node的上一个节点是
node.prev = cur
def insert(self,pos,item):
#指定位置添加
if pos <=0:
self.add(item)
elif pos > self.length()-1:
self.append()
else:
node = Node(item)
cur = self.head
count = 0
#把cur移动到指定位置的前一个位置
while count < (pos - 1):
count+=1
cur = cur.next
#node的prev指向cur
node.prev = cur
#node的next指向cur的next
node.next = cur.next
cur.next.prev = node
cur.next = node
def remove(self,item):
#删除节点
if self.is_empty():
return
else:
cur = self._head
if cur.item == item:
#首节点是要删除的节点
if cur.next == None:
#说明链表中只有一个节点
self.head = None
else:
#链表多于一个节点的情况
cur.next.prev = None
self.head = cur.next
else:
# 首节点不是要删除的节点
while cur != None:
if cur.item == item:
cur.prev.next = cur.next
cur.next.prev = cur.prev
break
cur = cur.next
def search(self,item):
#查找节点是否存在
cur = self._head
while cur != None:
if cur.item == item:
return True
cur = cur.next
return False
问题二:合并两个有序链表
点击leetcode中题目描述的相似题目里面,就会看见有序链表,题目描述为:
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
想了很久,缺乏思路,看来还是对链表的理解程度不够,看了下解答方案,大概总结出了两种解法,以后再回头看:
递归版:
class Solution:
def mergeTwoLists(self, l1, l2):
"""
:type l1: ListNode
:type l2: ListNode
:rtype: ListNode
"""
if l1==None and l2==None:
return None
if l1==None:
return l2
if l2==None:
return l1
if l1.val<=l2.val:
l1.next=self.mergeTwoLists(l1.next,l2)
return l1
else:
l2.next=self.mergeTwoLists(l1,l2.next)
return l2
非递归版:
class Solution:
def mergeTwoLists(self, l1, l2):
"""
:type l1: ListNode
:type l2: ListNode
:rtype: ListNode
"""
head = ListNode(0)
first = head
while l1 != None and l2 != None:
if l1.val > l2.val:
head.next = l2
l2 = l2.next
else :
head.next = l1
l1 = l1.next
head = head.next
if l1 == None:
head.next = l2
elif l2 == None:
head.next = l1
return first.next
未完待续