hadoop+Zookeeper(平台部署、hdfs工作原理、yarn调度器、高可用)
文章目录
- 1.设置单节点群集
- 1.1 安装软件及设置
- 1.2 独立运行
- 1.3 伪分布式操作
- 2.Hadoop集群设置
- 2.1 完全分布式
- 2.2 在线添加新节点
- 2.3 Yarn资源管理器
- 2.4 MRAppMaster上MapReduce作业处理流程
- 3.hadoop+Zookeeper
- 3.1 主备切换
- 1.部署 Zookeeper 集群(三台)
- 2. Hadoop 配置部署高可用
- 3.启动 hdfs 集群
- 4. 测试故障自动切换
- 4. yarn 的高可用
- 5.Hbase部署
- 1 hbase 配置
- 2.启动Hbase
- 3.测试
参考官网:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
实验环境:
172.25.0.1 server1: NameNode DFSZKFailoverController ResourceManager
172.25.0.5 server5: NameNode DFSZKFailoverController ResourceManager
172.25.0.2 server2: JournalNode QuorumPeerMain DataNode NodeManager
172.25.0.3 server3: JournalNode QuorumPeerMain DataNode NodeManager
172.25.0.4 server4: JournalNode QuorumPeerMain DataNode NodeManager
1.设置单节点群集
实验环境:server1
1.1 安装软件及设置
解压hadoop
[root@server1 ~]# su - red ##使用普通用户
[red@server1 ~]$ ls
hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ ls
hadoop-3.2.1.tar.gz jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ ln -s jdk-8u181/ jdk
[red@server1 ~]$ ls
hadoop-3.2.1.tar.gz jdk jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ tar zxf hadoop-3.2.1.tar.gz
[red@server1 ~]$ ls
hadoop-3.2.1 hadoop-3.2.1.tar.gz jdk jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ ln -s hadoop-3.2.1 hadoop
[red@server1 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz jdk jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz

![]()
设置环境变量:
vim hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/red/jdk
export HADOOP_HOME=/home/red/hadoop
[red@server2 ~]$ vim .bash_profile
[red@server2 ~]$ cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/hadoop/bin:$HOME/jdk/bin
export PATH
[red@server2 ~]$ source .bash_profile
[red@server2 ~]$ hadoop
1.2 独立运行
默认情况下,Hadoop被配置为以非分布式模式作为单个Java进程运行。
下面的示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。 输出被写入给定的输出目录。
[red@server1 ~]$ mkdir input
[red@server1 ~]$ cp hadoop/etc/hadoop/*.xml input
[red@server1 ~]$ ls input/
capacity-scheduler.xml hadoop-policy.xml httpfs-site.xml kms-site.xml yarn-site.xml
core-site.xml hdfs-site.xml kms-acls.xml mapred-site.xml
[red@server1 ~]$ hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[red@server1 ~]$ cd output/
[red@server1 output]$ cat *
1 dfsadmin


1.3 伪分布式操作
Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行。
vim hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vim hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
设置ssh免密
[red@server1 ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/red/.ssh/id_rsa):
Created directory '/home/red/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/red/.ssh/id_rsa.
Your public key has been saved in /home/red/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:IimMgV1OCo2rVOq6sS/eUyL7wwO0klylhAMEZ1b2U4Y red@server1
The key's randomart image is:
+---[RSA 2048]----+
|B+=.= .o |
|oO.O oEo |
|o.B + o |
|.B o . . |
|B.= o . S |
|+* o o . |
|+ = o |
|o+.= |
|+=oo+ |
+----[SHA256]-----+
[red@server1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[red@server1 ~]$ chmod 0600 ~/.ssh/authorized_keys

本地运行MapReduce作业
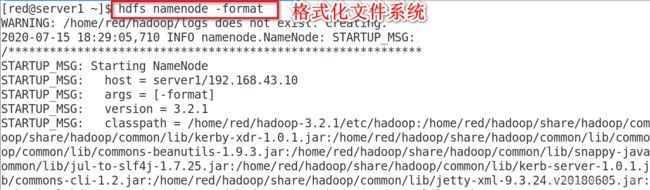
格式化文件系统:
[red@server1 ~]$ hdfs namenode -format


启动NameNode守护程序和DataNode守护程序:
[red@server1 ~]$ cd hadoop/sbin/
[red@server1 sbin]$ ./start-dfs.sh

hadoop守护程序日志输出将写入$ HADOOP_LOG_DIR目录(默认为$ HADOOP_HOME / logs)

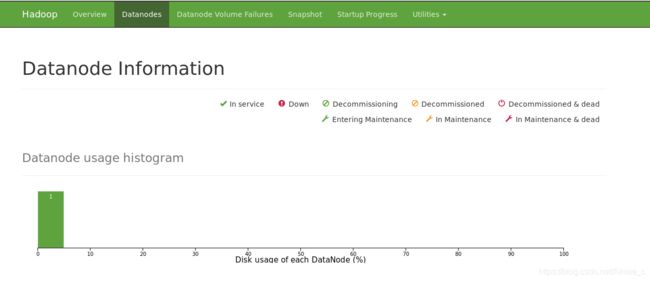
浏览Web界面的NameNode;默认情况下,它在以下位置可用:
NameNode-http:// localhost:9870 /

设置执行MapReduce作业所需的HDFS目录:
[red@server1 ~]$ hdfs dfs -ls
ls: `.': No such file or directory
[red@server1 ~]$ hdfs dfs -ls /
[red@server1 ~]$ hdfs dfs -mkdir /user
[red@server1 ~]$ hdfs dfs -mkdir /user/red
[red@server1 ~]$ hdfs dfs -ls 
将输入文件复制到分布式文件系统中:
[red@server1 ~]$ hdfs dfs -put input/


运行示例:
[red@server1 ~]$ rm -fr input output
[red@server1 ~]$ hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'


检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们:

[red@server1 ~]$ hdfs dfs -ls
Found 2 items
drwxr-xr-x - red supergroup 0 2020-07-15 18:44 input
drwxr-xr-x - red supergroup 0 2020-07-15 18:48 output
[red@server1 ~]$ hdfs dfs -cat output/*
2020-07-15 18:51:17,368 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1 dfsadmin
[red@server1 ~]$ hdfs dfs -get output
2020-07-15 18:51:40,542 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[red@server1 ~]$ ls
hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz jdk jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz output
[red@server1 ~]$ cd output/
[red@server1 output]$ ls
part-r-00000 _SUCCESS


![]()
删除输出文件



对字数进行统计
[red@server1 ~]$ hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output '
[red@server1 ~]$ hdfs dfs -cat output/*


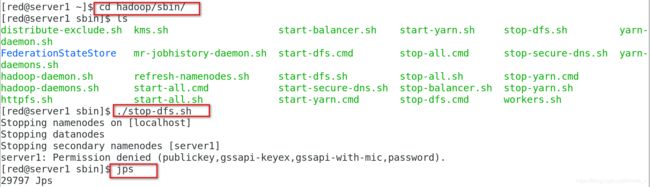
停止守护进程
[red@server1 ~]$ cd hadoop/sbin/
[red@server1 sbin]$ ./stop-dfs.sh
2.Hadoop集群设置

2.1 完全分布式
实验环境:server1、server2、server3




配置nfs文件系统
[root@server1 ~]# yum install -y nfs-utils.x86_64
[root@server1 ~]# vim /etc/exports
[root@server1 ~]# cat /etc/exports
/home/red *(rw,anonuid=1001,anongid=1001)
[root@server1 ~]# systemctl enable --now nfs
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
[root@server1 ~]# showmount -e
Export list for server1:
/home/red *
[root@server2/3 ~]# yum install -y nfs-utils.x86_64
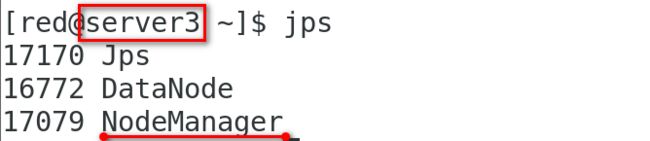
[root@server2/3 ~]# systemctl start rpcbind.service
[root@server2/3 ~]# mount 172.25.1.1:/home/red /home/red


![]()

![]()

vim hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.1.1:9000</value>
</property>
</configuration>

[red@server1 ~]$ vim hadoop/etc/hadoop/workers
[red@server1 ~]$ cat hadoop/etc/hadoop/workers
172.25.1.2
172.25.1.3
[red@server1 ~]$ vim hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>

本地运行MapReduce作业
格式化文件系统:
[red@server1 ~]$ hdfs namenode -format
![]()
启动NameNode守护程序和DataNode守护程序:
[red@server1 sbin]$ ./start-dfs.sh



设置执行MapReduce作业所需的HDFS目录:
[red@server1 ~]$ hdfs dfs -mkdir /user
[red@server1 ~]$ hdfs dfs -mkdir /user/red
[red@server1 ~]$ hdfs dfs -mkdir input
[red@server1 ~]$ hdfs dfs -ls
Found 1 items
drwxr-xr-x - red supergroup 0 2020-07-16 05:38 input
[red@server1 ~]$ hdfs dfs -put hadoop/etc/hadoop/*.xml input
[red@server1 ~]$ hdfs dfs -ls input
Found 9 items
-rw-r--r-- 2 red supergroup 8260 2020-07-16 05:38 input/capacity-scheduler.xml
-rw-r--r-- 2 red supergroup 885 2020-07-16 05:38 input/core-site.xml
-rw-r--r-- 2 red supergroup 11392 2020-07-16 05:38 input/hadoop-policy.xml
-rw-r--r-- 2 red supergroup 867 2020-07-16 05:38 input/hdfs-site.xml
-rw-r--r-- 2 red supergroup 620 2020-07-16 05:38 input/httpfs-site.xml
-rw-r--r-- 2 red supergroup 3518 2020-07-16 05:38 input/kms-acls.xml
-rw-r--r-- 2 red supergroup 682 2020-07-16 05:38 input/kms-site.xml
-rw-r--r-- 2 red supergroup 758 2020-07-16 05:38 input/mapred-site.xml
-rw-r--r-- 2 red supergroup 690 2020-07-16 05:38 input/yarn-site.xml
[red@server1 ~]$ hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[red@server1 ~]$ hdfs dfs -cat output/*
2020-07-16 05:42:53,150 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1 dfsadmin
1 dfs.replication






2.2 在线添加新节点
添加节点server4
配置server4
![]()

配置server4加入集群
[red@server4 ~]$ cd hadoop/etc/hadoop/
[red@server4 hadoop]$ vim workers
[red@server4 hadoop]$ cat workers
172.25.1.2
172.25.1.3
172.25.1.4
[red@server4 hadoop]$ vim hdfs-site.xml
[red@server4 hadoop]$ tail -8 hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
[red@server4 ~]$ hdfs --daemon start datanode
[red@server4 ~]$ jps
8217 Jps
8190 DataNode



运行示例
[red@server1 ~]$ dd if=/dev/zero of=bigfile bs=1M count=200
200+0 records in
200+0 records out
209715200 bytes (210 MB) copied, 0.294941 s, 711 MB/s
[red@server1 ~]$ ls
bigfile hadoop hadoop-3.2.1 hadoop-3.2.1.tar.gz jdk jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ hdfs dfs -put bigfile
2020-07-16 05:59:05,409 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-07-16 05:59:07,051 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false




2.3 Yarn资源管理器
[red@server1 ~]$ vim hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>

[red@server1 ~]$ vim hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_MAPRED_HOME=/home/red/hadoop
[red@server1 ~]$ vim hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>

[red@server1 ~]$ cd hadoop/sbin/
[red@server1 sbin]$ ls
distribute-exclude.sh mr-jobhistory-daemon.sh start-dfs.sh stop-balancer.sh workers.sh
FederationStateStore refresh-namenodes.sh start-secure-dns.sh stop-dfs.cmd yarn-daemon.sh
hadoop-daemon.sh start-all.cmd start-yarn.cmd stop-dfs.sh yarn-daemons.sh
hadoop-daemons.sh start-all.sh start-yarn.sh stop-secure-dns.sh
httpfs.sh start-balancer.sh stop-all.cmd stop-yarn.cmd
kms.sh start-dfs.cmd stop-all.sh stop-yarn.sh
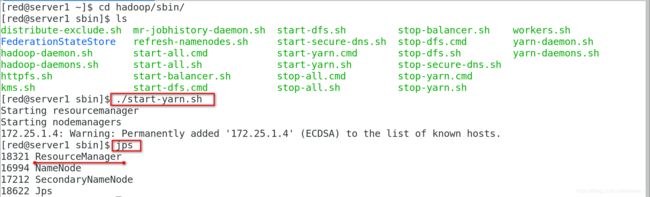
[red@server1 sbin]$ ./start-yarn.sh
Starting resourcemanager
Starting nodemanagers
172.25.1.4: Warning: Permanently added '172.25.1.4' (ECDSA) to the list of known hosts.
[red@server1 sbin]$ jps
18321 ResourceManager
16994 NameNode
17212 SecondaryNameNode
18622 Jps

2.4 MRAppMaster上MapReduce作业处理流程
mapreduce中概念:
1、首先用户程序(JobClient)提交了一个job,job的信息会发送到Job Tracker,Job Tracker是Map-reduce框架的中心,他需要与集群中的机器定时通信heartbeat,需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
2、TaskTracker是Map-Reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
3、TaskTracker同时监视当前机器的tasks运行状况。TaskTracker需要把这些信息通过heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的job分配运行在哪些机器上。
yarn中概念:
4、NM:NodeManager,管理每个节点上的资源和任务,主要有两个作用:定期向RM汇报该节点的资源使用情况和各个container的运行状态、接受并处理AM的作业任务启动,停止等请求。
5、RM:ResourceManager,负责管理所有应用程序计算资源的分配。
6、AM: ApplicationManager,每一个应用程序的AM负责相应的调度和协调。
7、containers:yarn为将来的资源隔离而提出的框架,每一个任务对应一个container,且只能在该container中运行。
 基本的步骤:
基本的步骤:
作业提交–作业初始化–任务的分配–任务的执行–任务进度和状态的更新–任务结束;
(0)Mr 程序提交到客户端所在的节点。
(1)Yarnrunner 向 Resourcemanager 申请一个 Application。
(2)rm 将该应用程序的资源路径返回给 yarnrunner。
(3)该程序将运行所需资源提交到 HDFS 上。
(4)程序资源提交完毕后,申请运行 mrAppMaster。
(5)RM 将用户的请求初始化成一个 task。
(6)其中一个 NodeManager 领取到 task 任务。
(7)该 NodeManager 创建容器 Container,并产生 MRAppmaster。
(8)Container 从 HDFS 上拷贝资源到本地。
(9)MRAppmaster 向 RM 申请运行 maptask 资源。
(10)RM 将运行 maptask 任务分配给另外两个 NodeManager,另两个 NodeManager 分
别领取任务并创建容器。
(11)MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager
分别启动 maptask,maptask 对数据分区排序。
(12)MrAppMaster 等待所有 maptask 运行完毕后,向 RM 申请容器,运行 reduce task。
(13)reduce task 向 maptask 获取相应分区的数据。
(14)程序运行完毕后,MR 会向 RM 申请注销自己。
3.hadoop+Zookeeper
3.1 主备切换
在典型的 HA 集群中,通常有两台不同的机器充当 NN。在任何时间,只有一台机器处于 Active 状态;另一台机器是处于 Standby 状态。Active NN 负责集群中所有客户端的操作; 而 StandbyNN 主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。 为了让 StandbyNN 的状态和 ActiveNN 保持同步,即元数据保持一致,它们都将会和 JournalNodes守护进程通信。当ActiveNN执行任何有关命名空间的修改,它需要持久化到一半以上的 JournalNodes 上(通过 edits log 持久化存储),而 Standby NN 负责观察 edits log 的变化,它能够读取从 JNs 中读取 edits 信息,并更新其内部的命名空间。一旦 Active NN 出现故障,Standby NN 将会保证从 JNs 中读出了全部的 Edits,然后切换成 Active 状态。 StandbyNN 读取全部的 edits 可确保发生故障转移之前,是和 Active NN 拥有完全同步的命 名空间状态。 为了提供快速的故障恢复,Standby NN 也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的 Database 将配置好 Active NN 和 StandbyNN 的位置,并向它们发送块文件所在的位置及心跳,如下图所示:

清除环境



![]()
![]()
加入server5,作为高可用节点

1.部署 Zookeeper 集群(三台)
server2\3\4作为ZK节点,server1/5作为高可用
[red@server1 ~]$ ls
bigfile hadoop-3.2.1 jdk jdk-8u181-linux-x64.tar.gz
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181 zookeeper-3.4.9.tar.gz
[red@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz
[red@server2 ~]$ ls
bigfile hadoop-3.2.1 jdk jdk-8u181-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181 zookeeper-3.4.9
[red@server2 ~]$ cd zookeeper-3.4.9/
[red@server2 zookeeper-3.4.9]$ ls
bin conf docs lib README_packaging.txt src zookeeper-3.4.9.jar.md5
build.xml contrib ivysettings.xml LICENSE.txt README.txt zookeeper-3.4.9.jar zookeeper-3.4.9.jar.sha1
CHANGES.txt dist-maven ivy.xml NOTICE.txt recipes zookeeper-3.4.9.jar.asc
[red@server2 zookeeper-3.4.9]$ cd con
conf/ contrib/
[red@server2 zookeeper-3.4.9]$ cd conf
[red@server2 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[red@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[red@server2 conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[red@server2 conf]$ vim zoo.cfg
[red@server2 conf]$ tail -3 zoo.cfg
server.1=172.25.1.2:2888:3888
server.2=172.25.1.3:2888:3888
server.3=172.25.1.4:2888:3888
[red@server2 conf]$ mkdir /tmp/zookeeper
[red@server2 conf]$ echo 1 > /tmp/zookeeper/myid
[red@server3 ~]$ mkdir /tmp/zookeeper
[red@server3 ~]$ echo 2 > /tmp/zookeeper/myid
[red@server4 ~]$ mkdir /tmp/zookeeper
[red@server4 ~]$ echo 3 > /tmp/zookeeper/myid



![]()
各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入 一个唯一的数字,取值范围在 1-255。这里的x是一个数字,与myid文件中的id是一致的。右边可以配置两个端口,第一个端口 用于 Follower 和 Leader 之间的数据同步和其它通信,第二个端口用于 Leader 选举过程中投票通信。
在三个 DN 上依次启动 zookeeper 集群
[red@server2 ~]$ cd zookeeper-3.4.9/bin ##启动zookeeper
[red@server2 bin]$ ls
README.txt zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh
[red@server2 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[red@server2 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
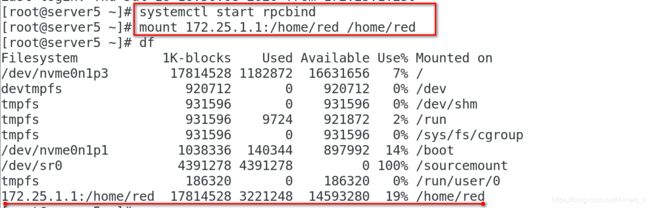
[red@server3 ~]$ cd zookeeper-3.4.9/bin
[red@server3 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[red@server3 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
[red@server4 ~]$ cd zookeeper-3.4.9/bin
[red@server4 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[red@server4 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/red/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower





2. Hadoop 配置部署高可用
[red@server1 hadoop]$ vim hadoop/etc/hadoop/ core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value> ## 指定 hdfs 的 namenode 为 masters
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.1.2:2181,172.25.1.3:2181,172.25.1.4:2181</value> ##指定 zookeeper 集群主机地址
</property>
</configuration>

[red@server1 hadoop]$ vim hadoop/etc/hadoop/ hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>##指定 hdfs的 nameservices为 masters,和 core-site.xml 文件中的设置保持一 致
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<property># masters 下面有两个 namenode 节点,分别是 h1 和 h2
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<property>##指定 h1 节点的 rpc 通信地址
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.1.1:9000</value>
</property>
<property>##指定 h1 节点的 http 通信地址
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.1.1:9870</value>
</property>
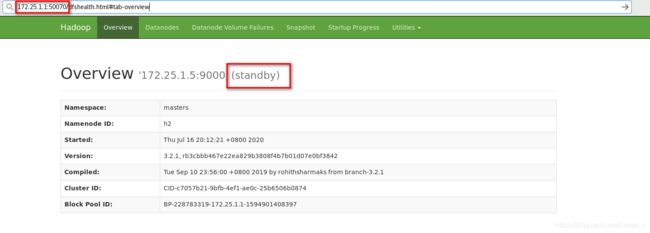
<property>##指定 h2 节点的 rpc 通信地址
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.1.5:9000</value>
</property>
<property>##指定 h2 节点的 http 通信地址
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.1.5:9870</value>
</property>
<property>##指定 NameNode 元数据在 JournalNode 上的存放位置
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.1.2:8485;172.25.1.3:8485;172.25.1.4:8485/masters</value>
</property>
<property>##指定 JournalNode 在本地磁盘存放数据的位置
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<property>##开启 NameNode 失败自动切换
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>##配置失败自动切换实现方式
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>##配置隔离机制方法,每个机制占用一行
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>##使用 sshfence 隔离机制时需要 ssh 免密码
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>## 配置 sshfence 隔离机制超时时间
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>


端口50070改为9870

3.启动 hdfs 集群
在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
hdfs --daemon start journalnode



格式化 HDFS 集群
[red@server1 ~]$ hdfs namenode -format
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
[red@server1 ~]$ scp-r /tmp/hadoop-red 172.25.1.5:/tmp


== 格式化 zookeeper (只需在 h1 上执行即可) ==
[red@server1 ~]$ hdfs zkfc -formatZK

启动 hdfs 集群(只需在 h1 上执行即可)
[red@server1 ~]$ cd hadoop/sbin/
[red@server1 sbin]$ ./start-dfs.sh











4. 测试故障自动切换
[red@server1 ~]$ hdfs dfs -mkdir /user
[red@server1 ~]$ hdfs dfs -mkdir /user/red
[red@server1 ~]$ ls
bigfile hadoop-3.2.1 jdk jdk-8u181-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181 zookeeper-3.4.9
[red@server1 ~]$ hdfs dfs -put bigfile
2020-07-16 19:13:46,554 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-07-16 19:13:48,697 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false



![]()
4. yarn 的高可用
1) 编辑 mapred-site.xml 文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
2)编辑 yarn-site.xml 文件
<configuration>
<property>## 配置可以在 nodemanager 上运行 mapreduce 程序
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>##激活 RM 高可用
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>##指定 RM 的集群 id
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<property>##定义 RM 的节点
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>##指定 RM1 的地址
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.1.1</value>
</property>
<property>##指定 RM2 的地址
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.1.5</value>
</property>
<property>##激活 RM 自动恢复
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>##配置 RM 状态信息存储方式,有 MemStore 和 ZKStore
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>## 配置为 zookeeper 存储时,指定 zookeeper 集群的地址
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.1.2:2181,172.25.1.3:2181,172.25.1.4:2181</value>
</property>
</configuration>
启动 yarn 服务




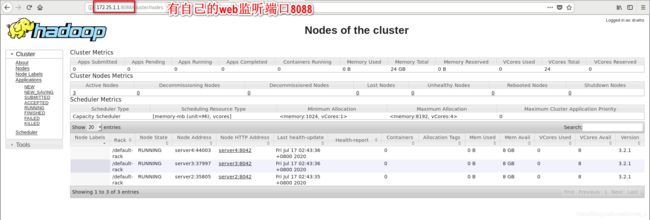


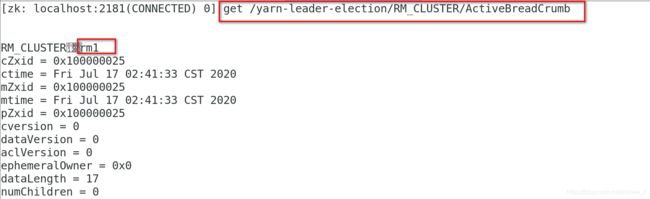
测试 yarn 故障切换





主备切换原理:
下面我们就来看看 YARN 是如何实现多个 ResourceManager 之间的主备切换的。
创建锁节点 在 ZooKeeper 上会有一个/yarn-leader-election/appcluster-yarn 的锁节点,所 有 的 ResourceManager 在 启 动 的 时 候 , 都 会 去 竞 争 写 一 个 Lock 子 节 点 : /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb,该节点是临时节点。ZooKeepr 能够 为 我 们 保 证 最 终 只 有 一 个 ResourceManager 能 够 创 建 成 功 。 创 建 成 功 的 那 个 ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby 状态。主备切换 当 Active 状态的 ResourceManager 出现诸如宕机或重启的异常情况时,其在 ZooKeeper 上 连 接 的 客 户 端 会 话 就 会 失 效 , 因 此 /yarn-leader-election/appcluster-yarn/ActiveBreadCrumb 节点就会被删除。此时其余各个 Standby状态的ResourceManager就都会接收到来自ZooKeeper服务端的Watcher事件通知,。
5.Hbase部署
1 hbase 配置
[red@server1 ~]$ tar zxf hbase-1.2.4-bin.tar.gz
[red@server1 ~]$ ls
bigfile hadoop-3.2.1.tar.gz jdk zookeeper-3.4.9
hadoop hbase-1.2.4 jdk1.8.0_181 zookeeper-3.4.9.tar.gz
hadoop-3.2.1 hbase-1.2.4-bin.tar.gz jdk-8u181-linux-x64.tar.gz
[red@server1 ~]$ cd hbase-1.2.4/conf/
[red@server1 conf]$ ls
hadoop-metrics2-hbase.properties hbase-env.sh hbase-site.xml regionservers
hbase-env.cmd hbase-policy.xml log4j.properties
[red@server1 conf]$ vim hbase-env.sh
export JAVA_HOME=/home/red/jdk
export HBASE_MANAGES_ZK=false
export HADOOP_HOME=/home/red/hadoop



vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.1.2,172.25.1.3,172.25.1.4</value>
</property>
<property>
<name>hbase.master</name>
<value>h1</value>
</property>
</configuration>
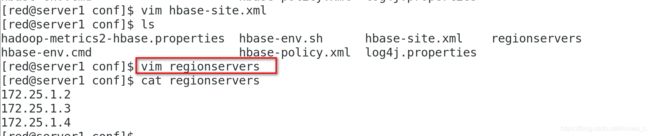
vim regionservers
[red@server1 conf]$ cat regionservers
172.25.1.2
172.25.1.3
172.25.1.4
2.启动Hbase
[red@server1 ~]$ cd hbase-1.2.4/bin/
./start-hbase.sh
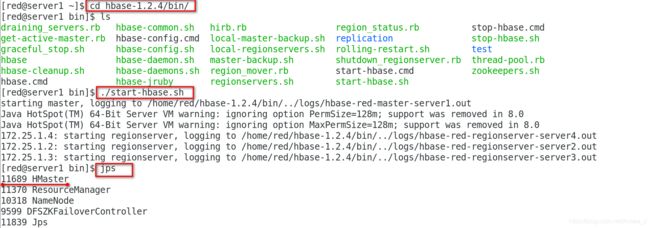


HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口 上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示信息的界面。


3.测试
[red@server1 bin]$ ./hbase shell
hbase(main):003:0> list'test'
TABLE test 1row(s) in 0.2150 seconds =>["test"]
hbase(main):004:0> put 'test', 'row1','cf:a', 'value1' 0row(s) in 0.0560 seconds
hbase(main):005:0> put 'test', 'row2','cf:b', 'value2' 0row(s) in 0.0370 seconds
hbase(main):006:0> put 'test', 'row3','cf:c', 'value3' 0row(s) in 0.0450 seconds
hbase(main):007:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1488879391939, value=value1
row2 column=cf:b, timestamp=1488879402796, value=value2
row3 column=cf:c, timestamp=1488879410863, value=value3
3row(s) in 0.2770 seconds 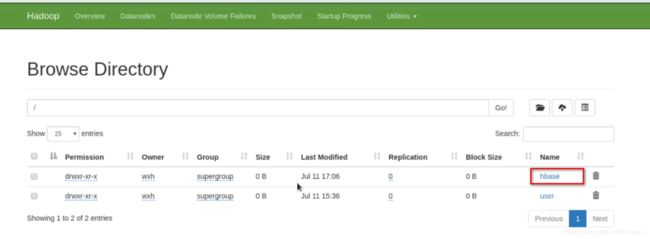
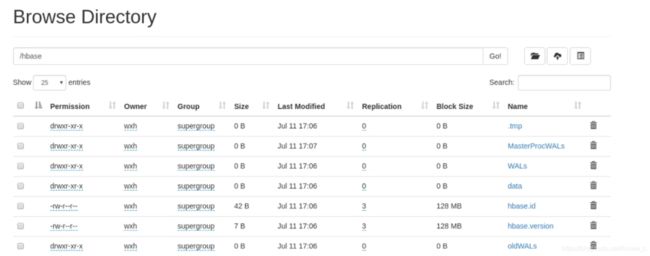

在主节点上 kill 掉 HMaster 进程后查看故障切换
