B树、B-、B+、B*树
1、B树(或B-树、B_树)
定义:是一种平衡的多路查找树,称为B树(或B-树、B_树)。B 树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树。
B-树结构特性:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:
1、树中每个结点最多含有m个孩子(m>=2);
2、除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
3、若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4、所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);
5、每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
注:可简记 1、根节点孩子数[2,m] 2、非根非叶节点孩子数[ceil(m / 2),m] 3、非叶节点关键字数=该节点孩子数-1 4、叶节点数(即查找失败节点数)= 关键字数+1
B-树的度:B树中每一个结点能包含的关键字数有一个上界和下界。这个下界可以用一个称作B树的最小度数(算法导论中文版上译作度数,最小度数即内节点中节点最小孩子数目)m(m>=2)表示。
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
B-树的节点定义:

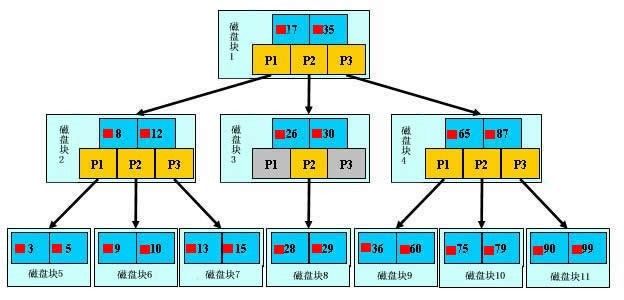
上面的图中比如根结点,其中17表示一个磁盘文件的文件名;小红方块表示这个17文件内容在硬盘中的存储位置;p1表示指向17左子树的指针。
B树中的每个结点根据实际情况可以包含大量的关键字信息和分支(当然是不能超过磁盘块的大小,根据磁盘驱动(disk drives)的不同,一般块的大小在1k~4k左右);这样树的深度降低了,这就意味着查找一个元素只要很少结点从外存磁盘中读入内存,很快访问到要查找的数据。
B-树的查找:
B-树的查找类似二叉排序树的查找,所不同的是B-树每个结点上是多关键码的有序表,在到达某个结点时,先在有序表中查找,若找到,则查找成功;否则,到按照对应的指针信息指向的子树中去查找,当到达叶子结点时,则说明树中没有对应的关键码。由于B- 树通常存储在磁盘上,则前一查找操作是在磁盘上进行的,而后一查找操作是在内存中进行的,即在磁盘上找到指针p 所指结点后,先将结点中的信息读入内存,然后再利用顺序查找或折半查找查询等于K 的关键字。
具体步骤:
假如每个盘块可以正好存放一个B树的结点(正好存放2个文件名)。那么一个BTNODE结点就代表一个盘块,而子树指针就是存放另外一个盘块的地址。
下面,咱们来模拟下查找文件29的过程(图为上图B-树):
1、根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
2、此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
3、根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
4、此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
5、根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
6、此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
B-树的高度:
1、因为根至少有两个孩子,因此第2层至少有两个结点。
2、除根和叶子外,其它结点至少有┌m/2┐个孩子,因此在第3层至少有2*┌m/2┐个结点
3、在第4层至少有2*(┌m/2┐^2)个结点,
4、在第 I 层至少有2*(┌m/2┐^(l-2) )个结点,于是有: N+1 ≥ 2*┌m/2┐I-2;
5、考虑第L层的结点个数为N+1(即是叶节点数),那么2*(┌m/2┐^(l-2))≤N+1,也就是L层的最少结点数刚好达到N+1个,即: I≤ log┌m/2┐((N+1)/2 )+2;
所以当B树包含N个关键字时,B树的最大高度为l-1(因为计算B树高度时,叶结点所在层不计算在内),即:l - 1 = log┌m/2┐((N+1)/2 )+1。
B-树的插入:
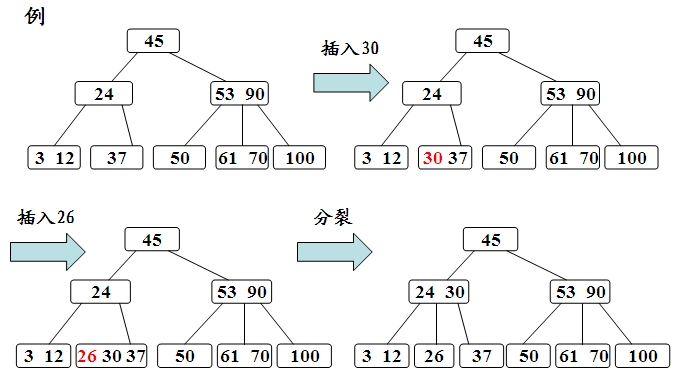
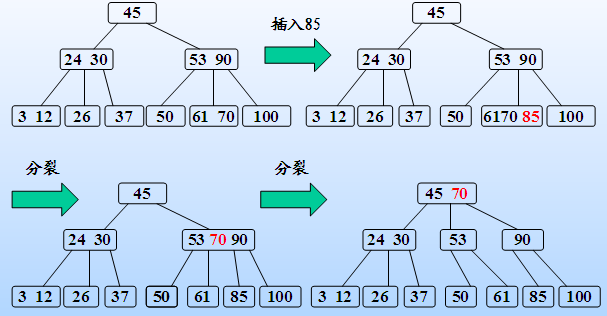
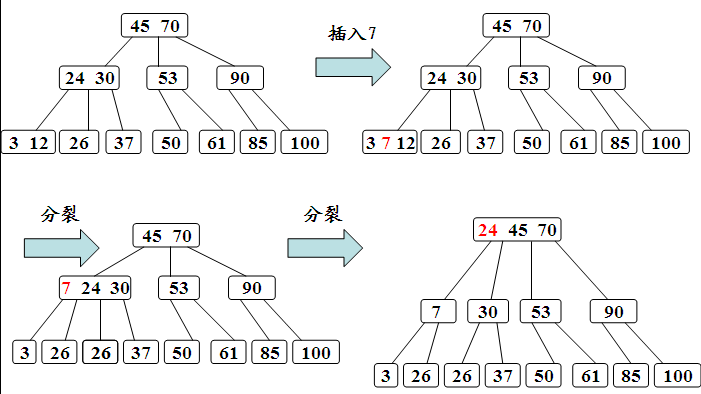
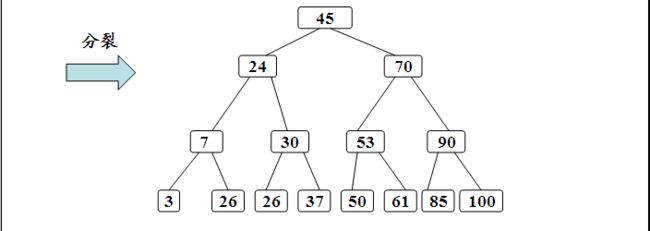
B-树的生成也是从空树起,逐个插入关键字而得。但由于B-树结点中的关键字个数必须≥ceil(m/2)-1,因此,每次插入一个关键字不是在树中添加一个叶子结点,而是首先在最低层的某个非终端结点中添加一个关键字,若该结点的关键字个数不超过m-1,则插入完成,否则要产生结点的“分裂”。
a.利用B-树的查找算法查找关键字的插入位置。若找到,则说明该关键字已经存在,直接返回。否则查找操作必于某个最低层的非终端结点上。
b.判断该结点是否还有空位置。即判断该结点的关键字总数是否满足n<=m-1。若满足,则说明该结点还有空位置,直接把关键字k插入到该结点的合适位置上。若不满足,说明该结点己没有空位置,需要把结点分裂成两个。
分裂的方法是:生成一新结点。把原结点上的关键字和k按升序排序后,从中间位置把关键字(不包括中间位置的关键字)分成两部分。左部分所含关键字放在旧结点中,右部分所含关键字放在新结点中,中间位置的关键字连同新结点的存储位置插入到父结点中。如果父结点的关键字个数也超过(m-1),则要再分裂,再往上插。直至这个过程传到根结点为止。
B-树的删除:
若在B-树上删除一个关键字,则首先应找到该关键字所在结点,并从中删除之,若该结点为最下层的非终端结点,且其中的关键字数目不少于ceil(m/2),则删除完成,否则要进行“合并”结点的操作。假若所删关键字为非终端结点中的Ki,则可以将指针Ai所指子树中的最小关键字Y替代Ki,然后在相应的结点中删去Y。例如,在下图 图的B-树上删去45,可以*f结点中的50替代45,然后在*f结点中删去50。
首先将要删除的关键字 k直接从该叶子结点中删除。然后根据不同情况分别作相应的处理,共有三种可能情况:
a.如果被删关键字所在结点的原关键字个数n>=ceil(m/2),说明删去该关键字后该结点仍满足B-树的定义。这种情况最为简单,只需从该结点中直接删去关键字即可。
b.如果被删关键字所在结点的关键字个数n等于ceil(m/2)-1,说明删去该关键字后该结点将不满足B-树的定义,需要调整。
调整过程为:
1、如果其左右兄弟结点中有“多余”的关键字,即与该结点相邻的右(左)兄弟结点中的关键字数目大于ceil(m/2)-1。则可将右(左)兄弟结点中最小(大)关键字上移至双亲结点。而将双亲结点中小(大)于该上移关键字的关键字下移至被删关键字所在结点中。
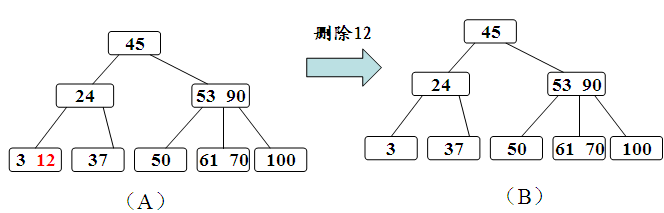
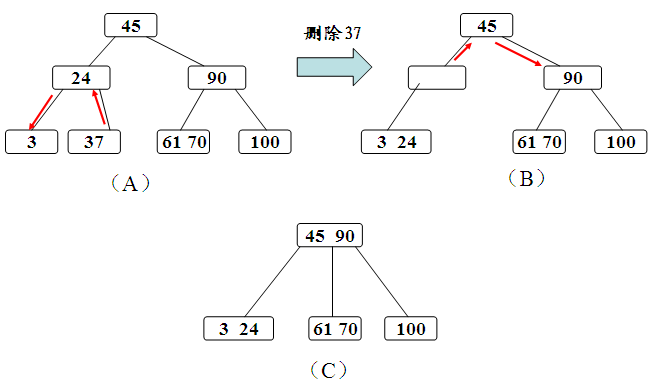
2、如果其左右兄弟结点中没有“多余”的关键字,即与该结点相邻的右(左)兄弟结点中的关键字数目均等于ceil(m/2)-1。这种情况比较复杂。需把要删除关键字的结点与其左(或右)兄弟结点以及双亲结点中分割二者的关键字合并成一个结点,即在删除关键字后,该结点中剩余的关键字加指针,加上双亲结点中的关键字Ki一起,合并到Ai(即双亲结点指向该删除关键字结点的左(右)兄弟结点的指针)所指的兄弟结点中去。如果因此使双亲结点中关键字个数小于ceil(m/2)-1,则对此双亲结点做同样处理。以致于可能直到对根结点做这样的处理而使整个树减少一层。
总之,设所删关键字为非终端结点中的Ki,则可以指针Ai所指子树中的最小关键字Y代替Ki,然后在相应结点中删除Y。对任意关键字的删除都可以转化为对最下层关键字的删除。
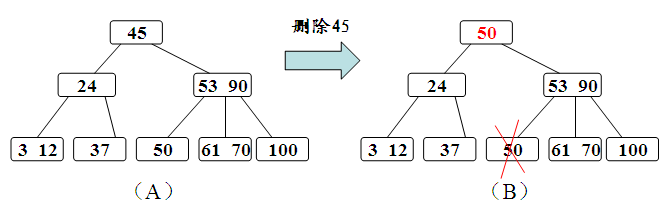
a、被删关键字Ki所在结点的关键字数目不小于ceil(m/2),则只需从结点中删除Ki和相应指针Ai,树的其它部分不变。
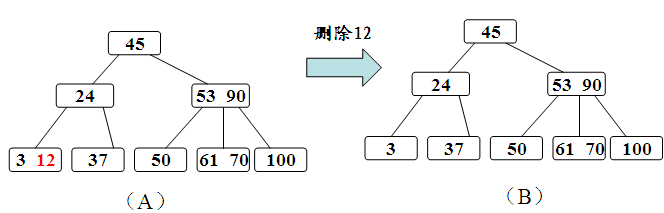
b、被删关键字Ki所在结点的关键字数目等于ceil(m/2)-1,则需调整。调整过程如下面所述。
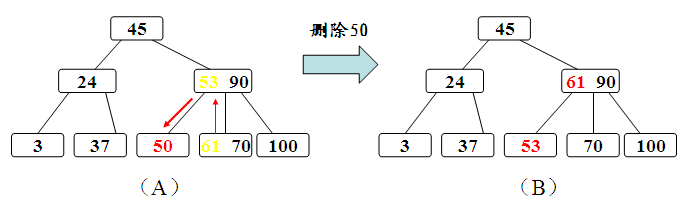
c、被删关键字Ki所在结点和其相邻兄弟结点中的的关键字数目均等于ceil(m/2)-1,假设该结点有右兄弟,且其右兄弟结点地址由其双亲结点指针Ai所指。则在删除关键字之后,它所在结点的剩余关键字和指针,加上双亲结点中的关键字Ki一起,合并到Ai所指兄弟结点中(若无右兄弟,则合并到左兄弟结点中)。如果因此使双亲结点中的关键字数目少于ceil(m/2)-1,则依次类推.
2、B+树
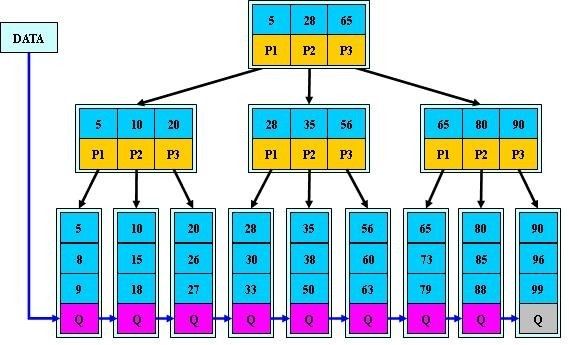
定义:B+树是应文件系统所需而产生的一种B-树的变形树。一棵m阶的B+树和m阶的B-树的差异在于:
1.有n棵子树的结点中含有n个关键字,非叶子结点的子树指针与关键字个数相同;每个关键字不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。为所有叶子结点增加一个链指针;
3.所有的非终端结点可以看成是索引部分,结点中仅含其子树(根结点)中的最大(或最小)关键字。(而B 树的非终节点也包含需要查找的有效信息)。非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);非根非叶节点关键字数[ceil(m / 2),m]。
通常在B+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B-树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-树(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B-树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3)数据库索引采用B+树的主要原因是 B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
B+树的查找:
对B+树可以进行两种查找运算:
1.从最小关键字起顺序查找;
2.从根结点开始,进行随机查找。
在查找时,若非终端结点上的关键值等于给定值,并不终止,而是继续向下直到叶子结点。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子结点的路径。其余同B-树的查找类似。
B+树的插入:
m阶B+树的插入操作在叶子结点上进行,假设要插入关键值a,找到叶子结点后插入a,做如下算法判别:
①如果当前结点是根结点并且插入后结点关键字数目小于等于m,则算法结束;
②如果当前结点是非根结点并且插入后结点关键字数目小于等于m,则判断若a是新索引值时转步骤④后结束,若a不是新索引值则直接结束;
③如果插入后关键字数目大于m(阶数),则结点先分裂成两个结点X和Y,并且他们各自所含的关键字个数分别为:u=大于(m+1)/2的最小整数,v=小于(m+1)/2的最大整数;
由于索引值位于结点的最左端或者最右端,不妨假设索引值位于结点最右端,有如下操作:
如果当前分裂成的X和Y结点原来所属的结点是根结点,则从X和Y中取出索引的关键字,将这两个关键字组成新的根结点,并且这个根结点指向X和Y,算法结束;
如果当前分裂成的X和Y结点原来所属的结点是非根结点,依据假设条件判断,如果a成为Y的新索引值,则转步骤④得到Y的双亲结点P,如果a不是Y结点的新索引值,则求出X和Y结点的双亲结点P;然后提取X结点中的新索引值a,在P中插入关键字a,从P开始,继续进行插入算法;
④提取结点原来的索引值b,自顶向下,先判断根是否含有b,是则需要先将b替换为a,然后从根结点开始,记录结点地址P,判断P的孩子是否含有索引值b而不含有索引值a,是则先将孩子结点中的b替换为a,然后将P的孩子的地址赋值给P,继续搜索,直到发现P的孩子中已经含有a值时,停止搜索,返回地址P。
B+树的删除:
B+树的删除也仅在叶子结点进行,当叶子结点中的最大关键字被删除时,其在非终端结点中的值可以作为一个“分界关键字”存在。若因删除而使结点中关键字的个数少于m/2 (m/2结果取上界,如5/2结果为3)时,其和兄弟结点的合并过程亦和B-树类似。
3、B*树
定义:B*树是B+树的变体,在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。
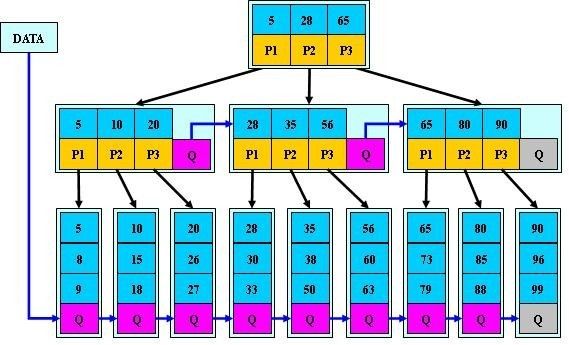
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
4、小结
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵丰满的B+树。
引用:
走进搜索引擎的作者梁斌老师针对B树、B+树给出了他的意见(为了真实性,特引用其原话,未作任何改动):“B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
比如要查 5-10之间的,B+树一把到5这个标记,再一把到10,然后串起来就行了,B树就非常麻烦。B树的好处,就是成功查询特别有利,因为树的高度总体要比B+树矮。不成功的情况下,B树也比B+树稍稍占一点点便宜。有很多基于频率的搜索是选用B树,越频繁query的结点越往根上走,前提是需要对query做统计,而且要对key做一些变化。
另外B树也好B+树也好,根或者上面几层因为被反复query,所以这几块基本都在内存中,不会出现读磁盘IO,一般已启动的时候,就会主动换入内存。”
Bucket Li:"mysql 底层存储是用B+树实现的,知道为什么么。内存中B+树是没有优势的,但是一到磁盘,B+树的威力就出来了"。
参考来源:B树算法与实现 B-树小结汇总 百度百科:B+树 B树算法与实现 从B树、B+树、B*树谈到R 树 B-树和B+树的应用:数据搜索和数据库索引【转】
B+/-Tree原理及mysql的索引分析