CUDA编程笔记
围绕图灵系显卡
常见术语
-
Streaming Multiprocessor (SM):GPU中的处理器核心
-
Graphics Processing Clusters (GPCs)
-
Texture Processing Clusters (TPCs)
-
Raster Operations Units(ROPs):光栅化处理单元。光栅化操作,是发生在模型完全建立,并且完成基本光照及对应纹理之后的操作环节。除了满足二维平面输出对坐标变换的要求之外,Rasterizer(光栅化)最大的意义在是:由于透视固有的视线前后遮蔽问题,建立好的模型存在很多看不到的部分,光栅化过程对Z值得判断,可以将这些看不到的部分剔除掉]
硬件概况
核心代号
| 产品型号 | RTX 2080 Ti | RTX 2080 | RTX 2070 | RTX 2060 | GTX 1660 Ti |
|---|---|---|---|---|---|
| 核心代号 | TU102 | TU104 | TU106 | TU106 | TU116 |
The TU104 and TU106 GPUs utilize the same basic architecture as TU102, scaled down to different degrees for different usage models and market segments.
硬件架构

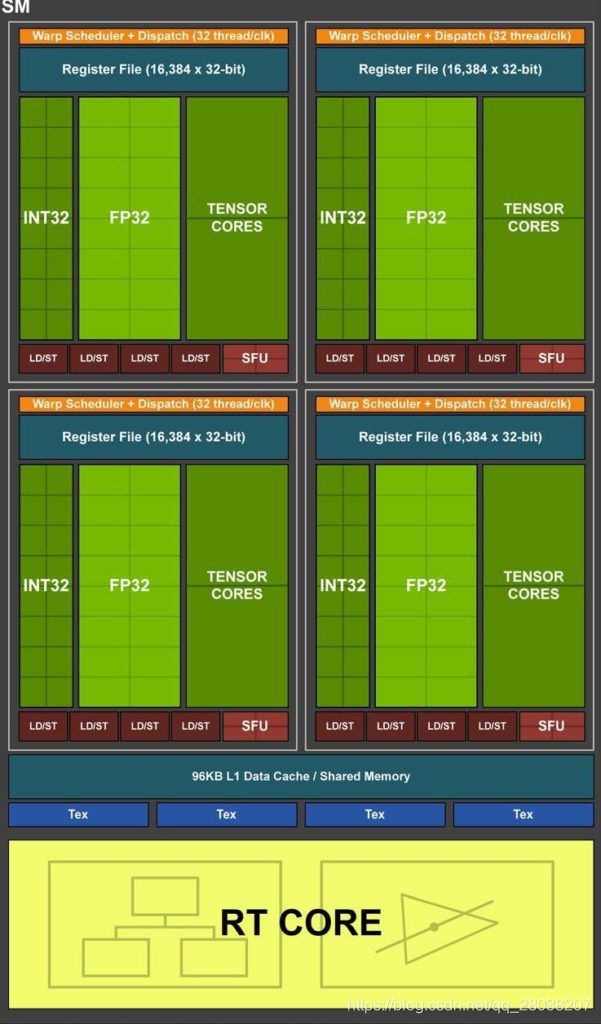
Graphics Processing Cluster
├── 6 * Texture Processing Cluster
├── 2 * Streaming Multiprocessor
├── 64 CUDA Cores = 64 FP32 cores, 32 FP64 cores, 64 INT32 cores
├── 8 mixed-precision Tensor Cores
├── 1 RT Core
├── 64K 32-bit registers, a 256 KB register file
├── 4 texture units
├── 96 KB of L1/shared memory
├── 16 special function units for single-precision floating-point transcendental functions
├── 4 warp schedulers
memory controller
├── 8 ROP units
├── 512 KB of L2 cache
- Traditional graphics workloads partition the 96 KB L1/shared memory as 64 KB of dedicated graphics shader RAM and 32 KB for texture cache and register file spill area. Compute workloads can divide the 96 KB into 32 KB shared memory and 64 KB L1 cache, or 64 KB shared memory and 32 KB L1 cache.
Turing Tensor Cores
- 用于加速矩阵运算,可用于神经网络训练和最后的推理
- modes : INT4, INT8, FP16
- Deep Learning Super Sampling (DLSS)要用到该单元
RT Cores
- 用于光线追踪
新特性
- 独立的线程调度。一个warp的线程可以不同步地执行
- hardware-accelerated Multi Process Service (MPS) with address space isolation for multiple applications
- 合作组(Cooperative Group),可以轻易达到不同范围线程的同步
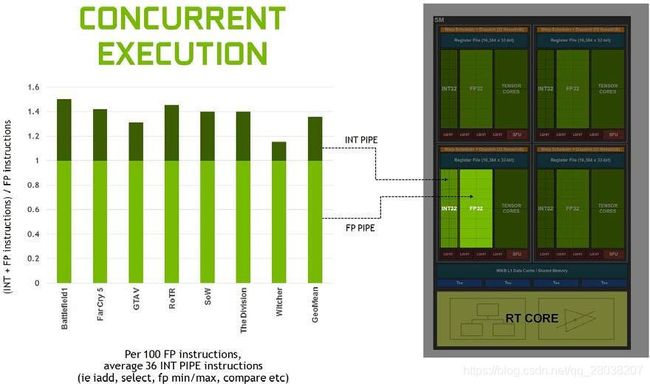
- 新的整数数据通道。使得浮点数指令计算可以和整数指令计算并行。可见
最优性能部分
- unify shared memory, texture caching, and memory load caching into one unit。对于常见工作,可以获得超过2倍的带宽和超过2倍的容量的L1缓存
deviceQuery
lsy@lsy-MS-7B79:~$ cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
lsy@lsy-MS-7B79:/usr/local/cuda-10.0/samples/1_Utilities/deviceQuery$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2060"
CUDA Driver Version / Runtime Version 10.1 / 10.0
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 5901 MBytes (6188105728 bytes)
(30) Multiprocessors, ( 64) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1710 MHz (1.71 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes (3M bytes)
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes(64 KBs)
Total amount of shared memory per block: 49152 bytes(48 KBs)
Total number of registers available per block: 65536(64*4 KBs)
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 29 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
Device 0: "GeForce GTX 1660 Ti"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 5945 MBytes (6233391104 bytes)
(24) Multiprocessors, ( 64) CUDA Cores/MP: 1536 CUDA Cores
GPU Max Clock rate: 1455 MHz (1.46 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1
Result = PASS
CPU vs GPU
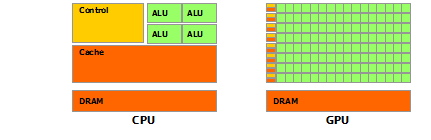
GPU适合处理的问题应该具有一下2个特点:
- 数据并行计算
- 高的算数强度:the ratio of arithmetic operations to memory operations
GPU劣势:缓存小,memory access latency 更大一些;逻辑控制能力差
目标:做完x份数学试卷
CPU 计算单元 = 数学教授, GPU 计算单元 = 20 个中学生, 一份试卷必须由单个人完成
CPU缓存大 = 做完一份后,去取下一份试卷花费的时间少
如果 x = 1,那么CPU更快。
如果 x = 1000,那么GPU更快。在计算过程中,取下一份试卷期间,20 个中学生大概率是有试卷在做的。所以,内存延迟就被掩盖掉了(即使延迟更低,也不会起到作用)
计算能力
Turing架构的显卡计算能力的为sm_75等。它代表了GPU的支持特征(如动态并行、半精度浮点数等)和技术规格(最多可并行的核函数数量、每个大核的32位寄存器个数)
NVCC 和 runtime
通过提供了c语言的扩展集和运行时库,帮助熟悉c语言的程序员编写在GPU上运行的程序。
nvcc
包含c语言扩展特性的源文件都要通过nvcc进行编译。nvcc是编译器驱动,提供和gcc类似的命令行选项,调用其它工具来实现不同阶段的编译。
-
线下编译:分离设备代码和主机代码
- 设备代码 ----编译为----> PTX code 或 cubin object
- 主机代码:核函数
<<<...>>>执行 ----修改为----> 调用核函数的运行时函数 - 可以选择继续让主机编译器编译主机代码
-
just-in-time 编译 : Any PTX code loaded by an application at runtime is compiled further to binary code by the device driver. This is called just-in-time compilation.
runtime
运行时库内容:C functions that execute on the host to allocate and deallocate device memory, transfer data between host memory and device memory, manage systems with multiple devices, etc.
- 初始化时间:运行时 在 一个运行时函数(more specifically any function other than functions from the device and version management sections of the reference manual) 第一次被调用的时候初始化。
- 初始化内容:为系统中的每个设备创建一个CUDA环境(被该应用的所有线程共享);设备代码(PTX则需编译)传送到设备内存
执行模型
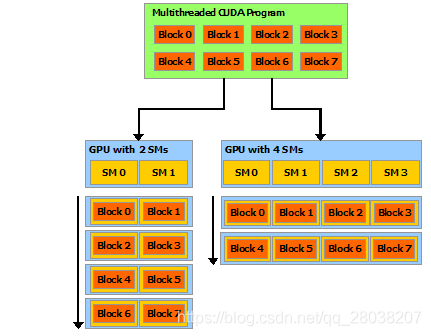
多线程程序(核函数)被分成多个线程块独立地执行。
核函数
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{ int i = threadIdx.x; C[i] = A[i] + B[i]; }
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
__global__、threadIdx和<<是CUDA C对c语言的扩展。
线程层次
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sw6356ni-1576298749030)(image/grid-of-thread-blocks.png)]
从大到小:grid > block > thread。核函数中与之对应的内置类型变量是blockIdx 、blockDim 、threadIdx。
线程块之间是独立进行;线程块内的线程必须同时存在同一个SM上,且它们之间可以共享该block的shared memory,并通过__syncthreads同步。线程的执行是以warp为单位进行的(分配线程资源以warp为单位)。线程块占用的资源(线程个数、共享内存、寄存器个数/线程)会影响程序执行的效率,见最优性能
warp
线程的创建、管理、调度和执行是warp为单位进行的。每个线程都有独立的指令地址计数器和寄存器状态,但是共享一个程序计数器(sm7.0之前)和一个活跃mask(标识活跃的线程)。
在7.0之前,同一个warp的线程是同步执行的,存在warp范围的线程同步。如果warp内发生线程分歧,则在某一执行路线中处于未活跃的线程仍要执行指令(浪费计算资源),只是不用读写数据。
7.0及之后,每个线程拥有独立的程序计数器和调用栈。因此,实现了独立线程粒度的调度(执行),可以更好地利用计算资源和同一warp线程间的通信。 schedule optimizer determines how to group active threads from the same warp together into SIMT units.
独立线程调度
Independent Thread Scheduling目前只有sm_7.0+的设备支持。这使得warp内的线程可以不同步地进行。当然可以选择不使用这个特征。
- 好处:不用考虑束内分歧,simplifying code changes when porting CPU code
- 注意:warp内线程不在是隐式地同步了
同步
- warp vote functions:warp内线程以
predicate作为输入,与0进行比较
int __all_sync(unsigned mask, int predicate); //if 在mask中且活动的线程 的predicate都大于0,则返回非零值
int __any_sync(unsigned mask, int predicate); //mask有32位,第i位标识第i个线程是否参与同步
unsigned __ballot_sync(unsigned mask, int predicate);
unsigned __activemask();
__syncwarp()同步warp内线程
block
一个SM可以存在多少个block,依赖于核函数需要的寄存器数量和block的共享内存大小,SM本身的资源和技术规格。如果一个SM不可以满足一个block,则程序不能执行。
block被分为一个或多个warp执行。
同步
__syncthreads():7.0之前的设备是warp间的同步,只要warp内的一个线程到达该障碍点即可。7.0及之后,则是线程的同步
存储模型
参数基于RTX2060

以可见性划分:
- 线程:
local memory,最多为512 KB;寄存器数据 - 线程块:共享内存
- 线程格:
global memory
另外2种特殊内存:纹理内存和常量内存
local memory
设备代码的自动变量(一般在寄存器中,单线程最多255个寄存器)有可能存储在局部内存,有3种情况:动态定义的数组;大型数组和结构;寄存器溢出后其它内容。加上编译选项--ptxas-options=-v可看。
- 大小:单线程最多512KB
- 位置:reside in device memory
- 缓存:L2缓存
- 组织:Local memory is however organized such that consecutive 32-bit words are accessed by consecutive thread IDs. Accesses are therefore fully coalesced as long as all threads in a warp access the same relative address
global memory
- 大小:Total amount of global memory: 5901 MBytes (6188105728 bytes)
- 位置:reside in device memory
- 缓存:L2缓存,只读数据 can also be cached in the unified L1/texture cache(用__ldg()或编译器自动优化)。加上编译器选项
-Xptxas -dlcm=ca,所有数据均可以缓存在 the unified L1/texture cache - 优点:容量大,DDR6
- 访问:
- 192位的内存总线宽度,由3个64位的内存通道组成
- cache line is 128 bytes。需要128字节对齐
- memory transaction大小:如果在L1和L2缓存,则为128字节。否则为32字节
- 非原子操作:非原子写,如果warp中的多个线程写入同一个位置,只有一个线程写,且该线程未知
shared memory
- 大小:Maximum amount of shared memory per multiprocessor = 64KB。可以手动调整( cudaFuncSetAttribute(),核函数粒度 ),同时编译器也进行自动调整
- 位置:L1缓存,和L1缓存共有96KB的空间。``The remaining data cache serves as an L1 cache and is also used by the texture unit that implements the various addressing and data filtering modes`
- 缓存:自己就是
- 优点:带宽大,延迟低。
32 banks that are organized such that successive 32-bit words map to successive banks. Each bank has a bandwidth of 32 bits per clock cycle.。且有广播机制 - 使用:避免访问冲突,即同时访问同一个bank的多个数据
constant memory
- 大小:整个设备上为Constant memory size = 64 KB
- 位置:专用的Constant memory
- 缓存:专用的缓存,Cache working set per multiprocessor for constant memory = 8 KB
a read-only constant cache that is shared by all functional units and speeds up reads from the constant memory space, which resides in device memory,
- 优点:如果一个warp的线程访问同一个内存数据,可以通过广播降低访问量;但是如果请求不同内存数据,则需要分为多次执行
A request is then split into as many separate requests as there are different memory addresses in the initial request, decreasing throughput by a factor equal to the number of separate requests.
texture and surface memory
-
区别:纹理内存是只读的,表面内存可读写。纹理内存支持硬件滤波和插值
-
大小:受SM技术规格限制,
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
-
位置:reside in device memory
-
缓存:专用的缓存,Cache working set per multiprocessor for texture memory = 32KB
-
优点:纹理缓存针对2D空间的局部性进行优化;有专用的单元计算地址空间;广播;自动滤波和插值
-
使用:有2种API用来访问纹理和表面内存,纹理引用API(有限制)和纹理对象API
-
纹理拾取:CUDA 数组对纹理拾取有优化,并且在设备端只能通过纹理拾取访问。线性内存则无优化
- 纹理对象需要提供什么?
- 要被拾取的纹理(一段纹理内存)
- 纹理的维度,
- 纹理元素的类型
- 读取模式:
cudaReadModeNormalizedFloatorcudaReadModeElementType - 纹理坐标模式:normalized or not。都是浮点数坐标
- 寻址模式:对越界元素的处理,
cudaAddressModeBorder, cudaAddressModeClamp, cudaAddressModeWrap, and cudaAddressModeMirror - 滤波模式:
cudaFilterModePointorcudaFilterModeLinear
- texture object API:A texture object is created using
cudaCreateTextureObject()from a resource description of typestruct cudaResourceDesc, which specifies the texture, and from a texture descriptioncudaTextureDesc
// Allocate CUDA array in device memory cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat); cudaArray* cuArray; cudaMallocArray(&cuArray, &channelDesc, width, height); // Copy to device memory some data located at address h_data // in host memory cudaMemcpyToArray(cuArray, 0, 0, h_data, size, cudaMemcpyHostToDevice); // Specify texture struct cudaResourceDesc resDesc; memset(&resDesc, 0, sizeof(resDesc)); resDesc.resType = cudaResourceTypeArray; resDesc.res.array.array = cuArray; // Specify texture object parameters struct cudaTextureDesc texDesc; memset(&texDesc, 0, sizeof(texDesc)); texDesc.addressMode[0] = cudaAddressModeWrap; texDesc.addressMode[1] = cudaAddressModeWrap; texDesc.filterMode = cudaFilterModeLinear; texDesc.readMode = cudaReadModeElementType; texDesc.normalizedCoords = 1; // Create texture object cudaTextureObject_t texObj = 0; cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL); // Destroy texture object cudaDestroyTextureObject(texObj); // Free device memory cudaFreeArray(cuArray); - 纹理对象需要提供什么?
-
texture reference API:
- 纹理引用的一些参数必须在编译时已知,且运行时不变。因此,必须提前声明为全局静态变量。另外的限制是不能作为函数参数
texture<DataType, Type, ReadMode> texRef;- 绑定CUDA arrays
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef; // Set texture reference parameters texRef.addressMode[0] = cudaAddressModeWrap; texRef.addressMode[1] = cudaAddressModeWrap; texRef.filterMode = cudaFilterModeLinear; texRef.normalized = true; cudaBindTextureToArray(texRef, cuArray); cudaUnbindTexture(texRef);
任务并行
可并行的任务
以下操作可以看作独立的任务,可以并行执行:
- Computation on the host;
- Computation on the device;
- Memory transfers from the host to the device;
- Memory transfers from the device to the host;
- Memory transfers within the memory of a given device;
- Memory transfers among devices.
主机和设备的并行执行
通过相对于主机的异步操作实现,异步操作是在设备完成任务之前就返回控制权,使得主机继续向下执行。主机和设备之间的异步操作如下:
- Kernel launches;(可以通过设置环境变量禁止异步;在用分析工具的时候,除非运行并行核函数分析,否则是同步的)
- Memory copies within a single device’s memory;
- Memory copies from host to device of a memory block of 64 KB or less;
- Memory copies performed by functions that are suffixed with Async;(如果主机内存不是页锁定的,则是同步的)
- Memory set function calls.
核函数并行
同一个CUDA环境(相当于CPU的同一进程)下的核函数可以并行执行。SM75下,最大并行数量是128。
Kernels that use many textures or a large amount of local memory are less likely to execute concurrently with other kernels.
数据传输和核函数并行
设备内数据传输,只需要设备支持核函数并行,即可与核函数并行执行。
主机和设备的数据传输,需要asyncEngineCount大于0,才可与核函数并行执行。主机内存必须是页锁定的
数据传输并行
asyncEngineCount大于等于2。主机内存必须是页锁定的
流和事件
需要通过流来实现后3种类型的任务并行。流是按顺序执行的一系列命令。不同流的命令可以并行执行。
cudaStream_t stream[2];
for (int i = 0; i < 2; ++i)
cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * size);
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel <<<100, 512, 0, stream[i]>>>
(outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
for (int i = 0; i < 2; ++i)
cudaStreamDestroy(stream[i]);
默认流
当执行相关cuda c函数,不指定流参数的时候,命令被发送到默认流上。可以通过编译选项,选择不同类型的默认流:
--default-stream per-thread: 默认流是常规流,每个主机线程拥有一个默认流--default-stream legacy:默认流是特殊流,NULL流。每个设备拥有一个NULL流,被所有主机线程共享。NULL流可以引发隐式同步
显式同步
下面的流中命令的顺序是主机代码发布命令的顺序
cudaDeviceSynchronize():主机代码等待所有主机线程上的所有流的前面命令执行完cudaStreamSynchronize():主机代码等待指定流的前面命令执行完cudaStreamWaitEvent():指定流之后的命令等待事件完成。如果是NULL流,则所有流的之后命令等待事件完成cudaStreamQuery():判断指定流的前面命令是否完成,无同步
隐式同步
不同流的2个命令不能并行执行,如果主机线程在它们之间发出了以下操作:
- a page-locked host memory allocation,
- a device memory allocation,
- a device memory set,
- a memory copy between two addresses to the same device memory,
- any CUDA command to the NULL stream,
- a switch between the L1/shared memory configurations
流这部分看 <<专业 CUDA C 编程 >>更好
回调
回调函数在主机上执行。回调可以插入到一个流的任意节点。当该流之前的操作完成,则会调用回调函数。该命令有同步的作用,即推迟该流之后命令的执行,直到回调完成。如果流是NULL流,则等待和推迟的命令范围扩大为所有流的命令
void CUDART_CB MyCallback(cudaStream_t stream, cudaError_t status, void *data){
printf("Inside callback %d\n", (size_t)data);
}
...
for (size_t i = 0; i < 2; ++i) {
cudaMemcpyAsync(devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>(devPtrOut[i], devPtrIn[i], size);
cudaMemcpyAsync(hostPtr[i], devPtrOut[i], size, cudaMemcpyDeviceToHost, stream[i]);
cudaStreamAddCallback(stream[i], MyCallback, (void*)i, 0);
}
流的优先级
At runtime, as blocks in low-priority schemes finish, waiting blocks in higher-priority streams are scheduled in their place.
事件
可用于计时和流间同步
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>
(outputDev + i * size, inputDev + i * size, size);
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
错误检查
所有的运行时函数返回错误代码,但是异步函数返回的错误代码反映了执行该函数之前的错误。这个错误可能是之前的异步函数产生的或者是该函数的参数错误。可以通过同步的方法确定该执行处是否有错误:cudaDeviceSynchronize()
运行时为每个主机线程保留了一个错误变量(初始化为cudaSuccess)。当错误发生的时候,它被重写。cudaPeekAtLastError返回该错误变量。cudaGetLastError返回并重置该错误变量。
最优性能
- 整数计算独立于浮点数计算。之前,浮点数数学运算和其它的简单计算 (integer adds for addressing and fetching data, floating point compare or min/max for processing results) 是不能同时进行的。
Turing adds a second parallel execution unit next to every CUDA core that executes these instructions in parallel with floating point math.
the Turing SM adds a new independent integer datapath that can execute instructions concurrently with the floating-point math datapath. In previous generations, executing these instructions would have blocked floating-point instructions from issuing.
- 线程块资源:线程块的线程必须在同一个SM中。线程块占用的资源(线程个数、共享内存、寄存器个数/线程)会影响程序执行的效率。
- Register and shared memory usage are reported by the compiler when compiling with the ``-ptxas-options=-v `option。
- Register usage can be controlled using the
maxrregcountcompiler option orlaunch bounds - 每个SM最多16个线程块、1024个线程、64KB共享内存、64K个32位寄存器。在图像处理中,如果一个block线程是32*32,那一个SM只能执行一个block。
性能指南
性能优化围绕3个基本策略:
- Maximize parallel execution to achieve maximum utilization;
- Optimize memory usage to achieve maximum memory throughput;
- Optimize instruction usage to achieve maximum instruction throughput.
最大化利用率
应用应该进行更多的并行操作(尽量避免同步操作),并且并行操作可以映射到系统的不同单元。
- 应用级别:主机计算、设备计算、主机与设备之间的数据传输可以并行操作。串行工作交给CPU,并行交给GPU
- 设备级别:SM之间可以并行计算。通过流,使得多个核函数并行执行
- SM级别:不同的计算单元之间可以并行。需要更多的warp驻扎在SM内
- 延迟掩盖:在每个指令发布时间,warp调度器选择准备执行下一条指令的warp,发布指令(2条)到该warp的活跃线程。共4个warp调度器,所以每个时钟周期,一个SM发布8条指令。延迟是warp得到下一条指令到开始执行该指令所等待的时钟周期个数。如果warp调度器在每个时钟周期都有指令发布,那么认为该延迟被掩盖掉了。当warp多的时候,可以使延迟“降低”
- 闲置:当在一个block范围同步时,SM上的另一个block可以继续执行。降低SM闲置的时间
最大化内存吞吐
尽快地传递需要的数据。应该减少低带宽通道的数据传输,同时,采用最优的内存访问模式(如纹理内存、共享内存,局部性(合并访问)、内存对齐等)
-
设备内存通过 32-, 64-, or 128-byte 的内存交易完成。一个warp内的内存访问(memory access)会被合并为一个或多个内存交易(memory transaction)
-
全局内存:全局内存指令支持 1, 2, 4, 8, or 16 bytes 的读写。因此,自定义的数据类型大小和内存对齐应该留意(如果类型大小是32字节,数据是连续的,那么访问的内存就会交错,吞吐量降低)。通过CUDA 内存 API 分配的内存至少是256字节对齐的
-
局部内存:设备代码的自动变量(一般在寄存器中,单线程最多255个寄存器)有可能存储在局部内存,有3种情况:动态定义的数组;大型数组和结构;寄存器溢出后其它内容。加上编译选项
--ptxas-options=-v可看。 -
其它内存特点,可见
存储模型
最大化指令吞吐
高效地(充分且不浪费)利用计算单元。如
-
减少吞吐量低的指令,如使用内置函数、单精度运算
-
减少warp内分歧(sm70之后,这个的影响减少)
-
减少指令个数,如避免同步、使用
__restrict__ -
避免产生大量的相同指令,应该给任务分配比例适当的浮点数和整型计算,使得计算资源利用率提高
-
在精度允许的条件下:
-ftz=true、-prec div=false、-prec-sqrt=false -
__fdividef(x, y)比/更快。-use_fast_math -
rsqrtf()指令只有在-prec-div=false和-prec-sqrt=false下,才会产生(编译器把1.0/sqrtf()优化为该指令) -
三角函数:尽量用单精度类型的。输入参数的单位为弧度,尽量不要太大,否则会进入慢的计算通道
-
整数算术:除法和取余会转换为20个指令,尽可能通过位运算优化
-
半精度算术:
-
类型转换:也是有对应指令的,尽量避免
C 语言扩展
函数执行空间说明符
Function execution space specifiers denote whether a function executes on the host or on the device and whether it is callable from the host or from the device.
__global__、__device__、__host__
变量内存空间声明符
__device__, __shared__ and __constant__
内置维度变量
gridDim blockDim blockIdx threadIdx warpSize
内存障碍函数
void __threadfence_block(); //前面的写对于block范围可见;前面的读有序
void __threadfence(); //除了块范围效果,前面的写对于设备范围可见。但仅仅保证顺序是这样,可能直接读缓存而发生错误
void __threadfence_system(); //除了块范围效果,前面的写对于系统范围可见
同步函数
void __syncthreads(); //阻塞,直到所有线程达到该点;之前的内存读写,block内可见; 块内线程必须都能(或都不)到达该点
int __syncthreads_count(int predicate);
int __syncthreads_and(int predicate);
int __syncthreads_or(int predicate);
void __syncwarp(unsigned mask=0xffffffff); //束内同步; 不必所有束内线程一致执行该命令; 正在执行的线程必须等待mask内的线程执行完该函数
执行同步 + 内存读写可见
只读数据缓存函数
T __ldg(const T* address);
数据会被缓存到常量缓存
原子函数
原子函数在32位或64位的全局或共享内存上执行原子操作。
原子函数有自己对应的范围版本:atomicAdd_system() atomicAdd_block()
束内投票函数
int __all_sync(unsigned mask, int predicate);
int __any_sync(unsigned mask, int predicate);
unsigned __ballot_sync(unsigned mask, int predicate);
unsigned __activemask();
束内比较函数
unsigned int __match_any_sync(unsigned mask, T value);
unsigned int __match_all_sync(unsigned mask, T value, int *pred);
mask指定了参与线程。函数只返回给活跃的参与线程(mask中的线程不必全部到达该点)非参加的线程不必同步
束内交换函数
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize); //目标lane = 本lane - delta
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
束矩阵函数
利用 tensor core 计算矩阵D = A*B + C
分析计数函数
void __prof_trigger(int counter);
每个SM有16个硬件计数器
断言
void assert(int expression);
动态内存管理
void* malloc(size_t size);
void free(void* ptr);
执行配置
<<< Dg, Db, Ns, S >>>
启动限制
__global__ void
__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
MyKernel(...)
{
...
}
循环展开
#pragma unroll