sort函数的排列顺序的使用+sort函数内部源码分析(只有sort的部分源码)(只涉及到概念,具体实现目前不清楚)
看到访问量竟然破千了,作为第一个破千的博客,再看了一下博客的质量,发现根本不匹配,就重新写一下吧(估计很多dalao都是奔着标题来的。。我也做了一回标题党啊)
当初一开始学习STL的时候对这个sort函数非常不理解,就写下这篇博客当做新手入门吧。(后面更新的对于STL中sort的源码的分析只是一时兴起,闲的时候更新,由于水平有限,所以可能会没有dalao想看的)
首先上一道例题熟悉C++,STL中sort的自定义排序:http://acm.hdu.edu.cn/showproblem.php?pid=1862
中文题,很清楚,按照不同的优先级进行排序。
这道题的目的应该就是让我这样的辣鸡熟悉STL中的sort吧。
sort函数有一个默认的排序规则就是从小到大(也就是说升序排列)如下面的这个代码:
int shuzu[10]; //定义一个数组
int main()
{
int i,j;
for(i=0;i<10;++i)
scanf("%d",&shuzu[i]); //首先输进去一些数
sort(shuzu,shuzu+10); //默认排序
for(i=0;i<10;++i)
printf("%d ",shuzu[i]); //输出
}嗯......这个因为是调用c++库函数,因此要加一个头文件,要不然可能会显示编译错误:
#include
using namespace std; 好了,运行一下就是这样的结果: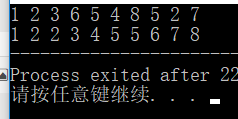
这是sort默认的排序,我认为比冒泡排序好多了,复杂度也是O(nlogn)级的....我刚学的时候被如此简单的代码惊呆了!!当时我还在沉迷冒泡不可自拔....
那么如果要使用STL中的sort()函数进行排序,应该怎么写呢?或者说,格式是什么?
我们来看sort函数中的参数的传递:![]()
首先我们要先知道一个知识:数组的表现:一个数组(比如说数组a),它的存储方式是:a代表数组的开始,表示的是数组的起始地址,这里a是一个地址。a+i表示的是数组第i个元素的地址,a[i]就是第i位置的元素了。
好了,我们可以来分析参数的传递了:
这是一个sort函数,对数组a进行排序。那么我们来看传入的参数:
首先是第一个__first,这个意思就是传入数组开始的位置。比如你的数组有效的元素位置是从a[1]开始的,那么传入a+1(这里a+1的意思是数组a的下一位)。
然后是第二个参数 __last,这个意思就是传入数组结束的位置的后面的一个位置。
第三个参数就是 __comp,是对数组自定义的排序规则。
前面两个必须要写,用来确定对哪些元素进行排序,后面那个可写可不写,不写就是默认的从小到大,写了就是定义的排序规则了。
在实际运用中,我们不可能只用这一种序列,遇到其他的情况,比如降序(当然可以反着输出,一开是我就是这样做的2333...)
但遇到复杂一点的就不行了,比如两个值相同的情况下按顺序排第二个参数,如例题一样:
那么我们就要自定义一个排序规则了,习惯性用Cmp表示这个的名字,当然用其他的也行,比如拼音:paixu(我一开始也就是这么做的23333)。
比如想让已知序列按照降序排列,就可以写一个这样的自定义的排序函数Cmp():
int a[110];
int n;
int Cmp(int x,int y){
return x>y;//如果x>y就返回1
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;++i){
scanf("%d",&a[i]);
}sort(a+1,a+1+n,Cmp);
for(int i=1;i<=n;++i){
printf("%d ",a[i]);
}printf("\n");
}这样的话就是从大到小了,再运行一下: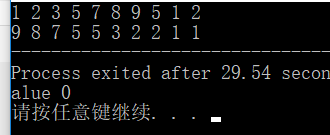
ok,降序的排列已经搞定了,下面我们来看看问题(终于回到了题目,不容易啊):
很明显题目要求的排序不止一种顺序:名字了,学号了,成绩了什么的,还有重复的,那么就要自定义多中了,算了,不说了直接代码:
#include
#include
#include
#include
#include
#include
using namespace std;
#define ll long long
#define da 100000
#define xiao -10000000
#define clean(a,b) memset(a,b,sizeof(a))
#define max 35000
struct nude{ //定义一个结构体nude
string name,num;
int gread;
}p[100010]; //名字是p,有100010个
int cmp1(nude a,nude b)
{
return a.num>p[i].num>>p[i].name>>p[i].gread;
if(c==1)
sort(p,p+n,cmp1); //第一种情况
else if(c==2)
sort(p,p+n,cmp2); //第二种情况
else
sort(p,p+n,cmp3); //第三种情况
printf("Case %d:\n",shu);
for(i=0;i 这个就是AC代码了,有注释,个人感觉还是比较清晰的。如果还有什么不详细的地方,欢迎留言评论。
其实还有一道题也可以拿来熟悉对sort的操作:
http://acm.nyist.edu.cn/JudgeOnline/problem.php?pid=8
Update:
一下都是自己学习摸索的,如果能对他人有所帮助,当然很开心,但是主要还是记录自己的总结
以后会不定期补充:
2018/2/6
闲的无聊看了一波sort的代码,想知道如何根据自定义函数改变排序规则的;
上网看了很多大佬关于sort剖析的博客,总结了一些,去掉了许多一看就很难的东西。。简单的介绍了一下sort
先贴出sort的源码:
/**
* @brief Sort the elements of a sequence.
* @ingroup sorting_algorithms
* @param __first An iterator.
* @param __last Another iterator.
* @return Nothing.
*
* Sorts the elements in the range @p [__first,__last) in ascending order,
* such that for each iterator @e i in the range @p [__first,__last-1),
* *(i+1)<*i is false.
*
* The relative ordering of equivalent elements is not preserved, use
* @p stable_sort() if this is needed.
*/
template
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)//check库(检查)
__glibcxx_function_requires(_LessThanComparableConcept<
typename iterator_traits<_RandomAccessIterator>::value_type>)
__glibcxx_requires_valid_range(__first, __last);
std::__sort(__first, __last, __gnu_cxx::__ops::__iter_less_iter());
}
/**
* @brief Sort the elements of a sequence using a predicate for comparison.
* @ingroup sorting_algorithms
* @param __first An iterator.
* @param __last Another iterator.
* @param __comp A comparison functor.
* @return Nothing.
*
* Sorts the elements in the range @p [__first,__last) in ascending order,
* such that @p __comp(*(i+1),*i) is false for every iterator @e i in the
* range @p [__first,__last-1).
*
* The relative ordering of equivalent elements is not preserved, use
* @p stable_sort() if this is needed.
*/
template
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)
__glibcxx_function_requires(_BinaryPredicateConcept<_Compare,
typename iterator_traits<_RandomAccessIterator>::value_type,
typename iterator_traits<_RandomAccessIterator>::value_type>)
__glibcxx_requires_valid_range(__first, __last);
std::__sort(__first, __last, __gnu_cxx::__ops::__iter_comp_iter(__comp));
}
template
_OutputIterator
__merge(_InputIterator1 __first1, _InputIterator1 __last1,
_InputIterator2 __first2, _InputIterator2 __last2,
_OutputIterator __result, _Compare __comp)
{
while (__first1 != __last1 && __first2 != __last2)
{
if (__comp(__first2, __first1))
{
*__result = *__first2;
++__first2;
}
else
{
*__result = *__first1;
++__first1;
}
++__result;
}
return std::copy(__first2, __last2,
std::copy(__first1, __last1, __result));
}
很长,我还不太清楚具体的实现;
先把所有的涉及到的代码都贴出来吧:
据说sort函数主要是由快排和堆排序一起构成的:
template
inline void
sort(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
// concept requirements
__glibcxx_function_requires(_Mutable_RandomAccessIteratorConcept<
_RandomAccessIterator>)//check库
__glibcxx_function_requires(_LessThanComparableConcept<
typename iterator_traits<_RandomAccessIterator>::value_type>)
__glibcxx_requires_valid_range(__first, __last);
std::__sort(__first, __last, __gnu_cxx::__ops::__iter_less_iter());
} 最下面std::sort中的函数调用的是这个:
template
inline void
__sort(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
if (__first != __last)
{
std::__introsort_loop(__first, __last,
std::__lg(__last - __first) * 2,
__comp);
std::__final_insertion_sort(__first, __last, __comp);
}
} 其中std::introsort loop调用的是:
正常快排:
template
void
__introsort_loop(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_Size __depth_limit, _Compare __comp)
{
while (__last - __first > int(_S_threshold))
{
if (__depth_limit == 0)
{
std::__partial_sort(__first, __last, __last, __comp);
return;
}
--__depth_limit;
_RandomAccessIterator __cut =
std::__unguarded_partition_pivot(__first, __last, __comp);
std::__introsort_loop(__cut, __last, __depth_limit, __comp);
__last = __cut;
}
} 这个是一个递归结构,Introspective Sort在数据量很大的时候采用的是正常的快速排序,下面的使用了
template
inline _RandomAccessIterator
__unguarded_partition_pivot(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
_RandomAccessIterator __mid = __first + (__last - __first) / 2;
std::__move_median_to_first(__first, __first + 1, __mid, __last - 1,
__comp);
return std::__unguarded_partition(__first + 1, __last, __first, __comp);
} 中的__unguarded_partition运用的分割算法:
template
_RandomAccessIterator
__unguarded_partition(_RandomAccessIterator __first,
_RandomAccessIterator __last,
_RandomAccessIterator __pivot, _Compare __comp)
{
while (true)
{
while (__comp(__first, __pivot))
++__first;
--__last;
while (__comp(__pivot, __last))
--__last;
if (!(__first < __last))
return __first;
std::iter_swap(__first, __last);
++__first;
}
} 但当递归深度太深的时候,调用堆排序__partial_sort
template
inline void
__partial_sort(_RandomAccessIterator __first,
_RandomAccessIterator __middle,
_RandomAccessIterator __last,
_Compare __comp)
{
std::__heap_select(__first, __middle, __last, __comp);
std::__sort_heap(__first, __middle, __comp);
} 堆排序结束后结束当前递归。
接下来是std::__final_insertion_sort函数:
template
void
__final_insertion_sort(_RandomAccessIterator __first,
_RandomAccessIterator __last, _Compare __comp)
{
if (__last - __first > int(_S_threshold))
{
std::__insertion_sort(__first, __first + int(_S_threshold), __comp);
std::__unguarded_insertion_sort(__first + int(_S_threshold), __last,
__comp);
}
else
std::__insertion_sort(__first, __last, __comp);
} 。。。。。脑壳疼。。不写了。。先放着吧。。
2018/10/15
在了解泛型之后,再次翻开了之前的sort的源码,现在看起来就舒服多了:
将它缩进变成顺眼的,然后加上注释:
//对比下面的这两个函数,发现它们之间并没什么区别,有的仅仅只是多了一个cmp,于是我放在一起理解了
//注释可以混着看,因为我有些地方分开写了
template//定义的数组名
inline void sort(_RandomAccessIterator __first, _RandomAccessIterator __last)
{
// concept requirements 概念的需求
//我觉得这个英文也有助于理解它的意思,于是我先将它翻译一下:
// glibc:安装;数据库 glid:口齿伶俐的 function :函数 requires :需要
//于是翻译过来大概就是:安装函数需要的东西 (大雾)
__glibcxx_function_requires(_Mutable/*可变*/_Random/*随机*/AccessIterator/*访问器(猜测)*/Concept/*概念*/<_RandomAccessIterator/*传入泛型的数据类型*/>)
__glibcxx_function_requires(_LessThan/**/Comparable/*类似的*/Concept/*概念*/
inline void __sort(_RandomAccessIterator __first, _RandomAccessIterator __last,_Compare __comp)
{
if (__first != __last)//如果首地址和为地址不一样,开始排序
{
//进入下面的函数。。。
std::__introsort_loop(__first, __last/*之前的排序范围*/,std::__lg(__last - __first) * 2/*size*/,__comp/*电脑及相关知识*/);
std::__final_insertion_sort(__first, __last, __comp);
}
} 不想再看了,已经对sort没有多少热情了,以后随缘改吧。。。
关于学习的博客:https://blog.csdn.net/qq_40482358/article/details/80210819