树和二叉树
树的定义
树:n(n≥0)个结点的有限集合。
树的定义是采用递归方法
树的基本术语
有序树、无序树:如果一棵树中结点的各子树从左到右是有次序的,称这棵树为有序树;反之,称为无序树。
森林:m (m≥0)棵互不相交的树的集合。
同构:对两棵树,若通过对结点适当地重命名,就可以使这两棵树完全相等(结点对应相等,结点对应关系也相等),则称这两棵树同构。
树的抽象数据类型定义
ADT Tree
Data
树是由一个根结点和若干棵子树构成,
树中结点具有相同数据类型及层次关系
Operation
InitTree
前置条件:树不存在
输入:无
功能:初始化一棵树
输出:无
后置条件:构造一个空树
DestroyTree
前置条件:树已存在
输入:无
功能:销毁一棵树
输出:无
后置条件:释放该树占用的存储空间
Root
前置条件:树已存在
输入:无
功能:求树的根结点
输出:树的根结点的信息
后置条件:树保持不变
Parent
前置条件:树已存在
输入:结点x
功能:求结点x的双亲
输出:结点x的双亲的信息
后置条件:树保持不变
Depth
前置条件:树已存在
输入:无
功能:求树的深度
输出:树的深度
后置条件:树保持不变
PreOrder
前置条件:树已存在
输入:无
功能:前序遍历树
输出:树的前序遍历序列
后置条件:树保持不变
PostOrder
前置条件:树已存在
输入:无
功能:后序遍历树
输出:树的后序遍历序列
后置条件:树保持不变
endADT
二叉树的逻辑结构
二叉树的概念
1.
在二叉树的第i层上至多有2^(i-1)个节点
2:
深度为k的二叉树至多有2^k-1个结点(k>=1)
3:
对任何一棵二叉树T,若其终端结点数为n0,度数为2的结点数为n2,则n0=n2+1
一共三个域,其中一个指向它的左孩子的根结点,另一个指向它右孩子的根结点
typedef struct node {
DataType data;
node* lchild, *rchild;
} BinTNode;
typedef BinTNode * BinTree;
先序遍历
(1).规则:先访问根结点,然后按规则遍历左子树,再按规则遍历右子树
template <typename T>
bool BiTree<T>::preorderR(BiTreeNode<T>* node,list<T>* l){
if(node==NULL||l==NULL)
return false;
l->push_back(node->data);
preorderR(node->left,l);
preorderR(node->right,l);
return true;
}
中序遍历
(1).先中序遍历左子树,再访问根结点,最后中序遍历右子树
template <typename T>
bool BiTree<T>::inorderR(BiTreeNode<T>* node,list<T>* l){
if(node==NULL||l==NULL)
return false;
inorderR(node->left,l);
l->push_back(node->data);
inorderR(node->right,l);
return true;
}
后序遍历
(1).后序遍历左子树,再后序遍历右子树,最终访问根结点
template <typename T>
bool BiTree<T>::postorderR(BiTreeNode<T>* node,list<T>* l){
if(node==NULL||l==NULL)
return false;
postorderR(node->left,l);
postorderR(node->right,l);
l->push_back(node->data);
return true;
}
树的高度
template <typename T>
int BiTree<T>::height(BiTreeNode<T>* node){
if(node==NULL)
return 0;
int left_height = height(node->left);
int right_height = height(node->right);
return max(left_height,right_height)+1;
}
二叉树的存储结构
顺序存储结构:
二叉树的顺序存储结构就是用一维数组存储二叉树中的结点,并且结点的存储位置,也就是数组的下标要能体现结点之间的关秀,比如双亲与孩子的关系,左右结点的兄弟关系。
完全二叉树:
完全二叉树由于其结构上的特点,通常采用顺序存储方式存储。一棵有n个结点的完全二叉树的所有结点从1到n编号,就得到结点的一个线性系列
完全二叉树除最下面一层外,各层都被结点充满了,每一层结点的个数恰好是上一层结点个数的2倍
① 当 2i ≤ n 时,结点 i 的左孩子是 2i,否则结点i没有左孩子;
② 当 2i+1 ≤ n 时,结点i的右孩子是 2i+1,否则结点i没有右孩子;
③ 当 i ≠ 1 时,结点i的双亲是结点 i/2;

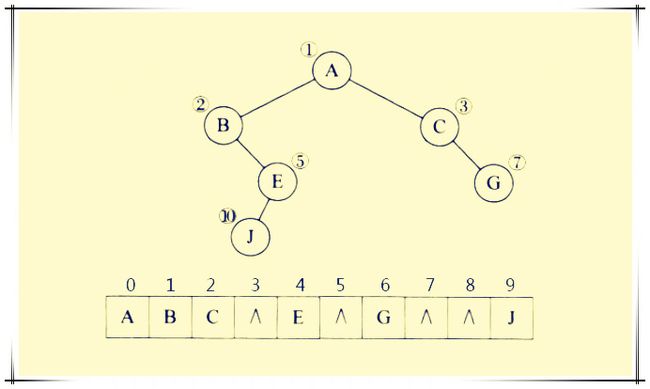
一般二叉树:
这时假设将一般二叉树进行改造,增添一些并不存在的空结点,使之成为一棵完全二叉树的形式,然后再用一维数组顺序存储。在二叉树中假设增添的结点在数组中所对应的元素值为"空"用^表示。
哈夫曼树
哈夫曼树是一种单词树,广泛使用于数据压缩之中。将会根据每个字符的权重,来构建一颗Huffman树,同时根据Huffman树对原来的文本进行二次编码,以达到压缩数据的目的。
比如当我们对AAABBBA进行Huffman树压缩时,A的编码将会是1,B的编码将会是0,那么这串字符串将会被压缩为1110001,只需要7个bit即可进行储存,而AAABBBA则至少需要7 * 8个bit,这样我们就可以达到数据压缩(compress)的目的。当然,当我们预见一个已经压缩好的数据时,我们只需要拥有其对应的编码表,则可将其进行展开
Huffman树节点:
Huffman树的节点中将会储存字符(ch),字符的权重(Weight),其左右子树(Left, Right),值得注意的时,除了叶子节点以外,我们不会储存具体的字符,因为Huffman我们需要保证Huffman树的编码是前缀编码,因此它必须是一颗满树,同时只能在叶子节点中存储具体的字符。
struct Node {
// 储存元素
char ch;
int weigth;
Node *Left;
Node *Right;
// 构造函数
Node() {
Left = NULL;
Right = NULL;
}
// 拷贝构造函数
Node(const Node &P) {
ch = P.ch;
weigth = P.weigth;
if (P.Left == NULL)
Left = NULL;
else {
Left = new Node();
*Left = *(P.Left);
}
if (P.Right == NULL)
Right = NULL;
else {
Right = new Node();
*Right = *(P.Right);
}
}
// 重载"<="符号
bool operator <= (const Node &P) {
return this->weigth <= P.weigth;
}
};