C++语法糖
std::bind的用法 : 给一个函数指针,加上固定的参数(不固定的参数用std::placeholders::_1、std::placeholders::_2来表示)
std::shared_ptr的用法:new出来的裸指针直接交给shared_ptr的构造函数,则后续无论怎么在多个shared_ptr之间共享,最后都会被析构(所有shared_ptr都reset了他或者所有shared_ptr对象自身都析构后)
默认reseth会调delete p; 如果传入的是数组(new int[100]),则要传入delete[]函数:ptr_.reset(data_array, [](V* data){ delete [] data; });
own的还是ptr_这个shared_ptr,加减释放用它,但是使用的是data() + begin, 用于指向数组中的非头部元素,但是释放仍然和整个数组同进退:ret.ptr_ = std::shared_ptr
unique_ptr, shared_ptr, weak_ptr的区别:unique_ptr不能复制给别的,要么move控制权,要么主动或被动析构,即只有一个指针指向同一对象时适用;shared_ptr用引用计数控制多个指针指向同一对象;weak_ptr在循环引用场景下使用,可以克服删不掉的问题(平时不会增加对象的引用计数,用的时候当场创建一个shared_ptr);
explicit: 很多地方用了explicit构造函数,禁止自动类型转化;
锁:std::lock_guard
以下实现条件wait功能(类似:while (!pred()) wait(lck); )
std::unique_lock
tracker_cond_.wait(lk, [this, timestamp]{
return tracker_[timestamp].first == tracker_[timestamp].second;
});
vector::data(), 是C++11新加的功能,能确保拿到连续数组的头元素地址;比&vec[0]要好,因为当vector为空时,&vec[0]将undefined
inplace_merge的STL实现
2个排好序的序列,放在一个数组里;用尽量少的额外空间,使其完成二路原地归并;
思路:1. 如果buffer能放下任何一个子序列,则转成普通的二路归并,注意copy_backward;
2. 如果放不下,就把较长的那个序列的1/2位置,做pivot,用lower_bound或upper_bound二分查找另一个序列的分割点,使得2个子序列分成4个子子序列s11,s12,s21,s22; 然后rotate "s12,s21", 变成"s21,s12", 然后递归的排序"s11,s21"和"s12,s22";
rotate,在buffer够大时,可以借助他来中转;极端小时,可以用分别reverse再全局reverse大法;rotate的目的是把原始序列转成"s11,s21" <= "s12,s22"这样的关系,从而可以分而治之;
__FILE__,__func__,__LINE__:
常用于logout,打trace,debug调试。__FILE__指示当前文件名;__func__指示当前函数名;__LINE__指示运行当前文件的行数。
std::atomic
t = new std::thread(&Func, arg); t.join(); delete t;
C++11对计时、卡时间的支持:std::chrono
atomic和volatile的区别:
fflush(C函数)和fsync(Linux系统调用)的区别
fflush() forces a write of all user-space buffered data for the given output or update stream via the stream's underlying write function.
The mentioned write function tells the operating system what the contents of the file should be. At this point all changes will be held in filesystem caches before actually being committed to disk.
The POSIX function fsync() tells the operating system to sync all changes from its caches to disk. As others have said you can use FlushFileBuffers on the Windows platform.
False Sharing: 定义一个struct Data {int a; int b}; Data d; 启动2个线程,线程A不停的给d.a加1,线程B不停的给d.b加1,问:是否会有问题?
我认为:正确性不会有问题,因为不存在访存冲突;速度可能会慢些,因为a和b在内存上挨得太近,在同一个cache行,任何一个线程把自己本地cache写回到主存的话,都可能造成另一个线程的cache认为自己这行失效了导致重新读内存加载这行。
今晚我在Visual Studio上实际编程对比了一下,A组实验是那个struct,B组实验是开辟一个100MB的数组让a是数组头部b是数组尾部,结果B组比A组大概能快个25%左右。
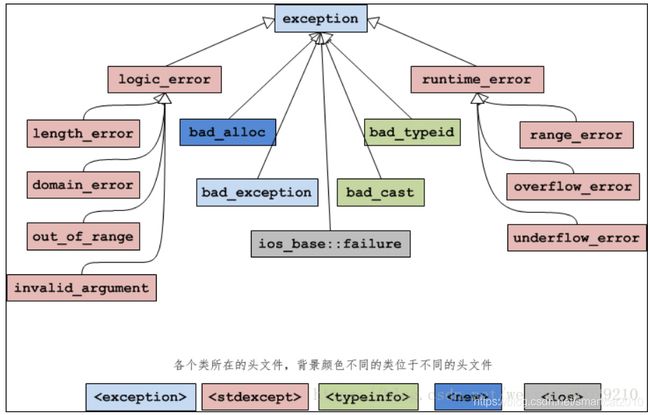
各种异常的继承关系