Datewhale爬虫学习活动打卡——Task1简单爬虫的实现
文章目录
- 爬虫的原理
- HTML和DOM
- request和get
- 单页面爬虫
- 多页面爬虫
- Beautiful Soup
- 实战:爬豆瓣TOP250电影
爬虫的原理
HTML和DOM
众所周知,我们在互联网上可以通过URL来定位互联网上的资源,我们常见的网页就是互联网上资源的一种。
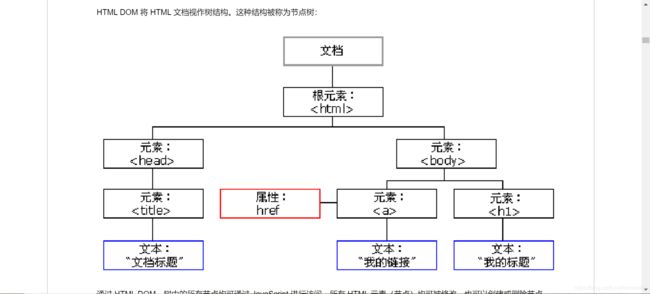
而网页一个网页的页面通常是由HTML、CSS和javascript构成的。HTML是一种标签式语言,各种各样的标签组成了网页上的各个元素。如图所示的这个部分就是HTML代码。
爬虫的作用既然是收集网页上的数据,那就和网页上的元素息息相关。在我们浏览网页时,浏览器将HTML代码解析为DOM(文档对象模型)树,通过这个DOM树,我们就可以找到各个标签之间的关系(父子,兄弟)等,方便我们定位要提取的数据的位置。
request和get
使用浏览器进行网页的浏览是在B/S架构下进行的操作,B/S架构即浏览器/服务器架构,客户端浏览器向服务器发送请求。
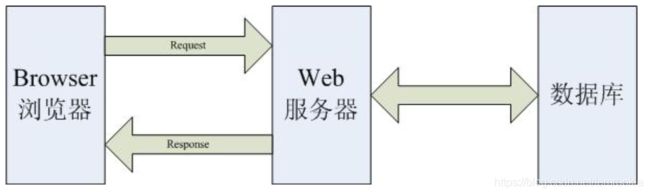
Python有一个Requests库,它基于urllib库,但比urllib更加便捷。通过这个库,我们就可以使用python向指定的url发送请求。
请求有多种方式,在爬虫中常有的就是get和post两种,get请求用于向服务器获取数据,post请求用于向服务器提交表单。在导入了Requests库后,通过request请求的get类型:
a = request.get(url) #url为请求的url
即可获得该请求返回的数据。
单页面爬虫
单页面爬虫指的是要爬取的数据全都在一个页面上,不需要点击一些分页按钮来获取其他数据的页面,即只需要1个url的爬虫。
多页面爬虫
多页面爬虫指的是要爬取的数据不在一个页面上的爬虫。对于多页面爬虫,需要按照网页分页url变化的规律来构造url,如果没有规律的需要模拟点击“下一页”按钮来实现爬取。
Beautiful Soup
Beautiful Soup中文文档
Beautiful Soup是一个python爬虫库,可以帮助我们解析从网页上获取到的数据,即对HTML程序的各个标签进行解析,来实现我们的需求。
实战:爬豆瓣TOP250电影
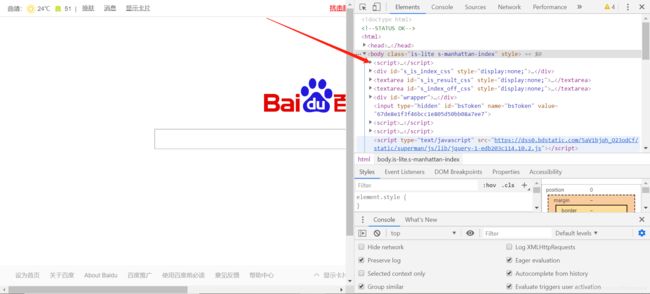
首先打开豆瓣top250的网页,将鼠标移动到我们要爬取的元素上单击右键,点“检查”即可在浏览器的开发者模式中找到我们要爬取元素的标签,如图:
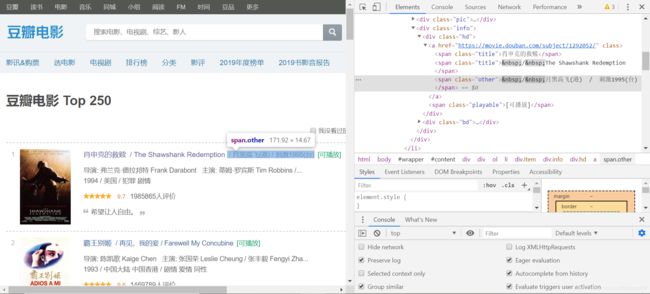
找到这个标签后,在开发者模式的窗口里对应的标签单击右键,“copy”->"copy selector"即可获取到该标签元素的选择器:
#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)

注意观察标签和网页,一部电影有很多个电影名,其他电影名和第一个电影名是兄弟关系,如果只想要第一个电影名,则保留span:nth-child(1)。
接下来继续分析网页,我们可以看到1页有25部电影,此时网页的url如图:
当我们点击下一页翻页后,网页的url发生了变化:

原来的start=0变为了start=25,由此我们可以得到url的变化规律,要爬取top250的电影,需要构造出10个Url,每个url的start参数要递增25。由此写出构造url的函数:
url = 'https://movie.douban.com/top250'
def urllist():
urls = []
for i in range(0,250,25):
turl = url + '?start=' + str(i) + '&filter='
urls.append(turl)
return urls
接下来就可以使用beautifulsoup和requests来发送请求并获取我们想要的数据。
def get_data(url):
res = requests.get(url,headers = headers)
soup = BeautifulSoup(res.content,"lxml") #解析获取到的内容
target = soup.select("#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)") #根据选择器选择标签
year = soup.select("#content > div > div.article > ol > li > div > div.info > div.bd > p:nth-child(1)")
for i,j in zip(target,year):
ti = i.get_text()
tj = j.get_text()
year = re.search("[0-9]{4}",tj).group()
director = re.search("导演: .*",tj).group()
tresult = ti + " " + year + " " + director
result.append(tresult)
print(tresult)
注意,此时使用的标签选择器和之前复制的有所不同,因为之前复制的标签选择器只选中了1个标签,而对于1个url,我们要爬取25个标签,所以看看修改哪里可以满足我们的需求。我们可以发现,一开始的选择器:
#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
在span标签前还有一个标签只选择了它的1个孩子,这就是我们的电影列表标签,如果选择所有列表中的孩子,就能完成我们的选择了。
#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1)
导演和主演的爬取也和这个类似,不过需要用到正则表达式,笔者对正则表达式了解的也不多,就不多叙述了。
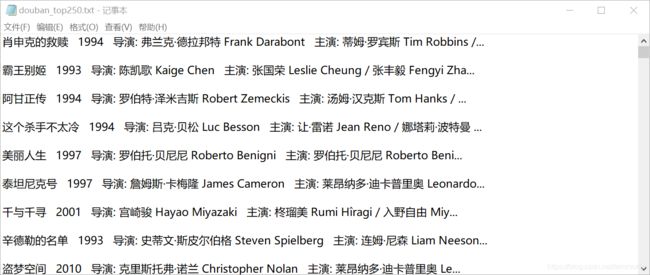
爬取出数据来肯定是要存储的,这里就先保存为txt文件。
保存为txt文件中有一个问题就是网页的编码通常时utf-8编码,而windows系统下新文件的默认编码是GBK编码,所以在创建新的txt文件时,需要以utf-8编码的形式创建:
file = open("douban_top250.txt","w",encoding='utf-8')
参考:
‘gbk’ codec can’t encode character解决方法
在保存时每存一行需要换行,这样数据更好看,所以在写入时在原始数据后加上"\r\n"即可:
file.write(i+'\r\n')
最终就将豆瓣top250的电影保存为了本地的txt文件。