中南大学自动化学院“智能控制与优化决策”课题组-第五章神经网络小结
1. 试述常见的激活函数,试述将线性函数 f ( x ) = w T x f(x)=w^Tx f(x)=wTx 用作神经元激活函数的缺陷
1.1什么是激活函数
如下图,如下图,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function.
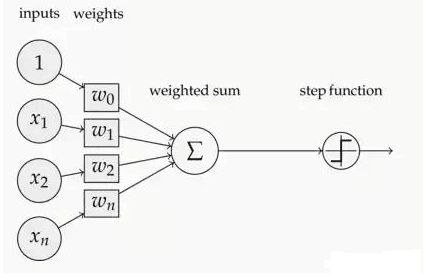
1.2激活函数的作用
如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这也是为什么不使用线性激活函数的原因。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
1.3常见的激活函数
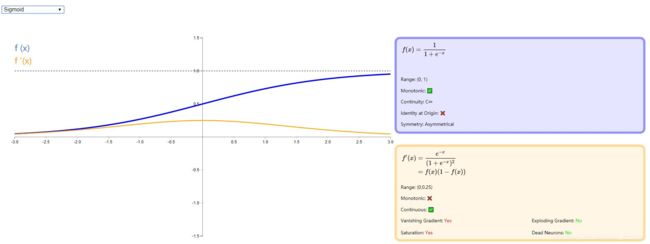
- Sigmoid激活函数
sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外, ( 0 , 1 ) (0, 1) (0,1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如 Sigmoid 交叉熵损失函数。
然而,sigmoid 也有其自身的缺陷,最明显的就是饱和性。从下图可以看到,其两侧导数逐渐趋近于 0 。具有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和。
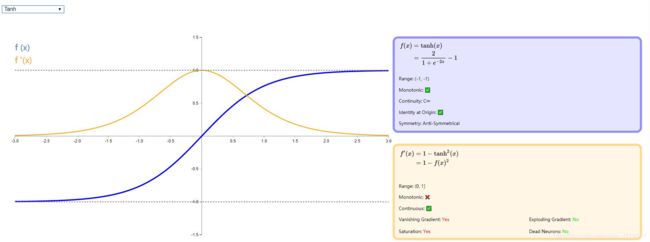
- Tanh函数
tanh 是双曲正切函数,tanh 函数和 sigmod 函数的曲线是比较相近的,咱们来比较一下看看。首先相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh 的输出区间是在 (-1,1) 之间,而且整个函数是以 0 为中心的,这个特点比 sigmod 的好。
一般二分类问题中,隐藏层用 tanh 函数,输出层用 sigmod 函数。不过这些也都不是一成不变的,具体使用什么激活函数,还是要根据具体的问题来具体分析,还是要靠调试的。
详情看下图:
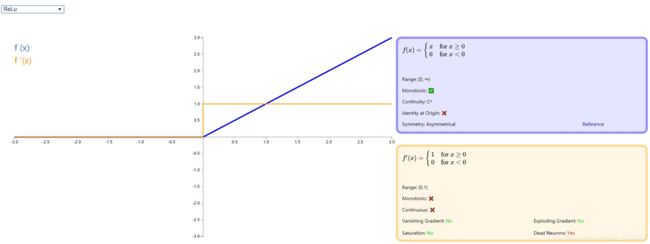
- ReLU
ReLU 全称是:Rectified linear unit, 是目前比较流行的激活函数,它保留了类似 step 那样的生物学神经元机制:输入超过阈值才会激发。虽然在 0 点不能求导,但是并不影响其在以梯度为主的反向传播中发挥有效作用。有关 ReLU 的详细介绍,请移步论文:《Rectified Linear Units Improve Restricted Boltzmann Machines》 还有一篇介绍比较全的博客:神经网络回顾 - Relu 激活函数.
图示如下:
- Leaky ReLU
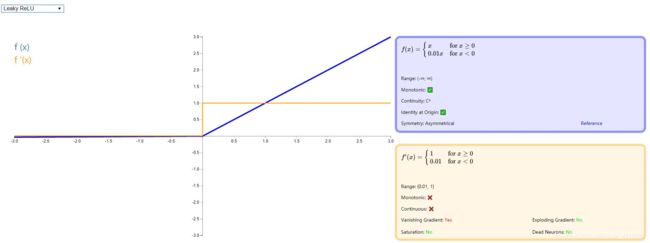
由于 ReLU 在小于零的部分全部归为 0 ,这样极易造成 神经元死亡 ,因此 Andrew L. Maas 等人在论文 《Rectifier Nonlinearities Improve Neural Network Acoustic Models》 中提出了新的激活函数,在小于 0 的方向增加一个非常小的斜率。如下图:
2.感知机与多层网络
2.1感知机
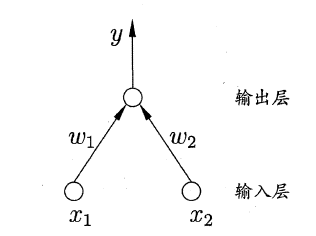
感知机(Perceptron)由两层神经元组成,如图所示,输入层接收外界输入信号后传递给输出层,输出层是 M−PM−P 神经元,亦称为“阈值逻辑单元”。
更一般地,给定训练数据集,权重 w i w_i wi以及阈值 θ \theta θ可通过学习得到。阈值 θ \theta θ可看作一个固定输入为 − 1.0 -1.0 −1.0的“哑结点”多对应的连接权重 w n + 1 w_{n+1} wn+1. 这样,权重和阈值学习就可统一为权重的学习。感知机的学习规则非常简单,对训练样例 ( x , y ) (x,y) (x,y),若当前感知机的输出为 y ^ \hat y y^, 则感知机权重将最优调整:
w i ← w i + Δ w i Δ w i = η ( y − y ^ ) x i w_i \leftarrow w_i +\Delta w_i \\ \Delta w_i=\eta(y-\hat y)x_i wi←wi+ΔwiΔwi=η(y−y^)xi
其中 η ∈ ( 0 , 1 ) \eta \in (0,1) η∈(0,1)称为“学习率(learing rate)” .从上式可以看出,若感知机对训练样例 ( x , y ) (x,y) (x,y)预测正确,则感知机不发生变化,否则将根据错误的程度进行权重调整。感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,其学习能力非常有限。只能处理线性可分的情况,无法处理非线性可分的情况。
2.2多层网络
要解决非线性可分问题,需要考虑使用多层功能神经元。输出层和输入层之间的一层神经元,被称为隐层或隐含层,隐含层和输出层神经元都是拥有激活函数的功能神经元。

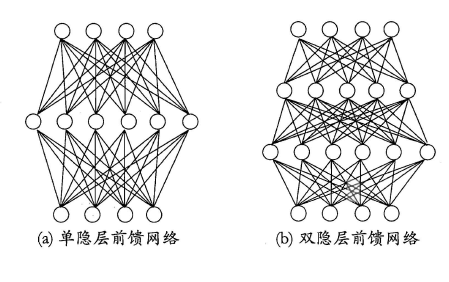
更一般地,常见的神经网络如下图,每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。这样的神经网络结果通常称为“多层前馈神经网络”(multi-layer feedforward neural networks),其中输入层神经元接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出;换言之,输入层神经元仅是接受输入,不进行函数处理,隐层与输出层包含功能神经元。
3. 试述使用sigmoid激活函数的神经元与对数几率回归的联系。
两者都是跟 s i g m o i d sigmoid sigmoid函数有关,但是在对数几率回归里, s i g m o i d sigmoid sigmoid函数的作用是将线性回归模型产生的预测值(实值)转化为 0 / 1 0/1 0/1 值. s i g m o i d sigmoid sigmoid 函数是用于代替单位阶跃函数,因为 s i g m o i d sigmoid sigmoid 函数单调且可微;在神经元模型中, s i g m o i d sigmoid sigmoid函数作为“激活函数”用以处理产生神经元的输出,因为神经元模型中的神经元收到来自 n n n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,采用“激活函数”能将输出值转化为 0 / 1 0/1 0/1 值。
3. 对于图5.7(102页)中的 ,试推导出BP算法中的更新公式
对训练例 ( x k , y k ) (\bm x_k,\bm y_k) (xk,yk), 假定神经网络的输出为 y ^ k = ( y ^ 1 k , y ^ 2 k , . . . , y ^ l k ) \hat y_k=(\hat y_{1}^{k},\hat y_{2}^{k},...,\hat y_{l}^{k}) y^k=(y^1k,y^2k,...,y^lk),即 y ^ j k = f ( β j − θ j ) \hat y_{j}^{k}=f(\beta_j-\theta_j) y^jk=f(βj−θj) ,
则网络在 ( x k , y k ) (\bm x_k,\bm y_k) (xk,yk)上的均方误差为:
E k = 1 2 ∑ j = 1 l ( y ^ j k − y ^ j k ) 2 E_k=\frac{1}{2}\sum_{j=1}^{l}(\hat y_{j}^{k}-\hat y_{j}^{k})^2 Ek=21j=1∑l(y^jk−y^jk)2
任意参数 v v v的更新估计式为 v ← v + Δ v v \leftarrow v+ \Delta v v←v+Δv
对于误差 E k E_k Ek,给定学习率 η \eta η,有 Δ w h j = − η ∂ E k ∂ w h j . \Delta w_{hj}=-\eta \frac{\partial E_k}{\partial w_{hj}}. Δwhj=−η∂whj∂Ek.
可以推导出:
∂ E k ∂ w h j = ∂ E k ∂ y ^ j k . ∂ y ^ j k ∂ β j . ∂ β j ∂ w h j . ∂ β j ∂ w h j = b h f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) g j = − ∂ E k ∂ y ^ j k . ∂ y ^ j k ∂ β j = − ( y ^ j k − y j k ) f ′ ( β j − θ j ) = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) \frac{\partial E_k} {\partial w_{hj}}=\frac{\partial E_k} {\partial \hat y_{j}^{k}}.\frac{\partial \hat y_{j}^{k}} {\partial \beta _j}.\frac{\partial \beta _j} {\partial w_{hj}} . \\ \ \ \frac{\partial \beta _j} {\partial w_{hj}}=b_h \\ f'(x)=f(x)(1-f(x)) \\ g_j= -\frac{\partial E_k} {\partial \hat y_{j}^{k}}.\frac{\partial \hat y_{j}^{k}} {\partial \beta _j} \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ =-(\hat y_{j}^{k}-y_{j}^{k})f'(\beta_j-\theta _j)\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ =\hat y_{j}^{k}(1-\hat y_{j}^{k})(y_{j}^{k}-\hat y_{j}^{k}) ∂whj∂Ek=∂y^jk∂Ek.∂βj∂y^jk.∂whj∂βj. ∂whj∂βj=bhf′(x)=f(x)(1−f(x))gj=−∂y^jk∂Ek.∂βj∂y^jk =−(y^jk−yjk)f′(βj−θj) =y^jk(1−y^jk)(yjk−y^jk)
接着得到BP算法中关于 w h j w_{hj} whj的更新公式 Δ w h j = η g j b h . \Delta w_{hj}=\eta {g_j}{b_h.} Δwhj=ηgjbh.
类似可得 Δ θ j = − η g j , Δ v i h = η e h x i , Δ γ = − η e h , \Delta \theta_j=-\eta g_j ,\\ \Delta v_{ih}=\eta e_h x_i,\\ \Delta \gamma=-\eta e_h, Δθj=−ηgj,Δvih=ηehxi,Δγ=−ηeh,
其中 e h = ∂ E k ∂ b h . ∂ b h ∂ α h = − ∑ j = 1 l ∂ E k ∂ β j . ∂ β j ∂ b h f ′ ( α h − γ h ) = ∑ j = 1 l w h j g j f ′ ( α h − γ h ) = b h ( 1 − b h ) ∑ j = 1 l w h j g j e_h=\frac{\partial E_k}{\partial b_h}.\frac{\partial b_h}{\partial \alpha_h } \\ =-\sum_{j=1}^{l}\frac{\partial E_k}{\partial \beta_j}.\frac{\partial \beta_j}{\partial b_h}f'(\alpha_h-\gamma_h) \\ =\sum_{j=1}^{l}w_{hj}g_jf'(\alpha_h-\gamma_h)\\ =b_h(1-b_h)\sum_{j=1}^{l}w_{hj}g_j eh=∂bh∂Ek.∂αh∂bh=−j=1∑l∂βj∂Ek.∂bh∂βjf′(αh−γh)=j=1∑lwhjgjf′(αh−γh)=bh(1−bh)j=1∑lwhjgj
4. 试述标准BP算法和累计BP算法,试编程实现标准BP算法和累计BP算法,在西瓜数据集上分别用这两个算法训练一个单隐层神经网络,并进行比较
需注意的是, BP 算法的目标是要最小化训练集 D D D上的累积误差
E = 1 m ∑ k = 1 m E k E=\frac{1}{m}\sum_{k=1}^{m}E_k E=m1k=1∑mEk但我们上面介绍的"标准BP 算法"每次仅针对一个训练样例更新连接权和阈值,也就是说,算法的更新规则是基于单个的 E k E_k Ek 推导而得.果类似地推导出基于累积误差最小化的更新规则,就得到了累积误差逆传播(accumulated error backpropagation)算法.累积BP 算法与标准BP 算法都很常用.一般来说,标准BP 算法每次更新只针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现"抵消"现象.因此,为了达到同样的累积误差极小点,标准BP 算法往往需进行更多次数的迭代.累积BP 算法直接针对累积误差最小化,它在读取整个训练集 D D D 一遍后才对参数进行更新,其参数更新的频率低得多.但在很多任务中,累积误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP 往往会更快获得较好的解,尤其是在训练集 D D D 非常大时更明显.
5. 试述如何缓解BP神经网络的过拟合现象
由于 BP(BackPropagation) 神经网络具有强大的表示能力,PB神经网络经常遭遇过拟合,其训练误差持续降低,但测试误差却可能上升。有两种策略常用来缓解BP网络的过拟合:
- 第一种策略是“早停”(early stopping):将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。
- 第二种策略是“正则化”(regularization),其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权与阈值的平方和。
6. 试述RBF网络,RNN循环神经网络的概念和特点
-
RBF是一种单隐层前馈神经网络,它使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合,假定输入为 d d d维向量 x \bm x x,输出为实值,则RBF可表示为
φ ( x ) = ∑ i = 1 q ρ ( x , c i ) \varphi(\bm x)=\sum_{i=1}^{q}\rho(\bm x,\bm c_i) φ(x)=i=1∑qρ(x,ci)
其中 q q q为隐层神经元个数, c i 和 w i c_i和w_i ci和wi分别是第 i i i个隐层神经元所对应的中心和权重, ρ ( x , c i ) \rho(x,c_i) ρ(x,ci)是径向基函数,这是沿某种径向对称的函数,通常定义为样本 x x x到数据中心 c i c_i ci之间欧氏距离的单调函数.常见的高斯径向基函数形如:
ρ ( x , c i ) = e − β i ∣ ∣ x − c i ∣ ∣ 2 \rho (x,c_i)=e^{-\beta_i||x-c_i||^2} ρ(x,ci)=e−βi∣∣x−ci∣∣2具有足够多隐层神经元的RBF神经网络能以任意精度逼近任意连续函数. -
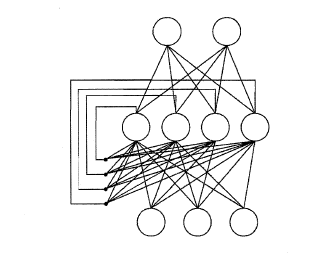
RNN循环神经网络,与前馈神经网络不同,“递归神经网络”(Recurrent Neural Networks)允许网络出现环形结构,可让一些神经元的输出反馈回来作为输入信号,也就是网络在 t t t 时刻的输出状态不仅和输入有关,还和 t − 1 t-1 t−1 时刻的网络状态有关,从而能处理与时间有关的动态变化。Elman 网络是最常用的递归神经网络之一,其结构与多层前馈网络相似,但隐层神经元的输出被反馈回来,与下一时刻的输入层神经元提供的信号一起,作为隐层神经元下一时刻的输入。隐层神经元通常采用 S i g m o i d Sigmoid Sigmoid 激活函数,而网络的训练则常通过推广的BP算法进行。
7. 试述卷积神经网络的卷积、下采样(池化)过程,试述卷积神经网络的架构
从计算机的角度来看,图像实际上是一个二维矩阵,卷积神经网络所做的工作就是采用卷积、池化等操作从二维数组中提取特征,并对图像进行识别。理论上来说,只要是能转换成二维矩阵的数据,都可以利用卷积神经网络来识别和检测。比如声音文件,可以分割成很短的分段,每段音阶的高低可以转换成数字,这样整段的声音文件就可以转换为二维矩阵,类似的还有自然语言中的文本数据,医药实验中的化学数据等等,都可以利用卷积神经网络来实现识别和检测。
-
卷积:卷积是卷积神经网络最核心的概念,也是其名称的由来。卷积用来提取图像的局部特征,它是一个数学计算方法,下面动图形象的展现了卷积过程。
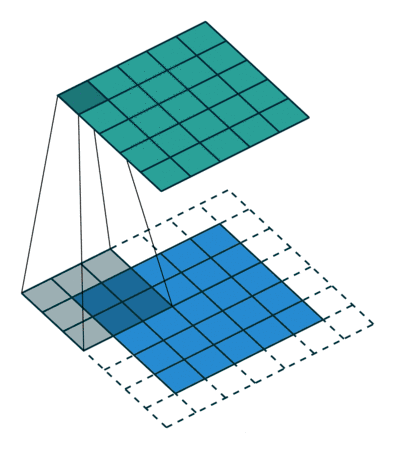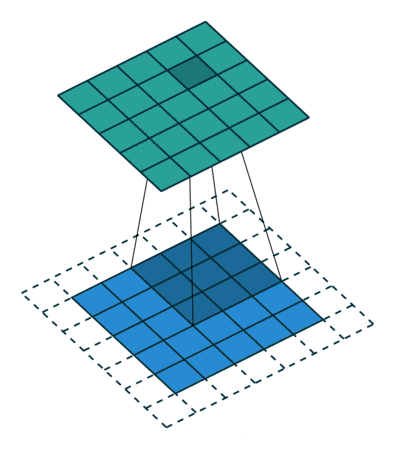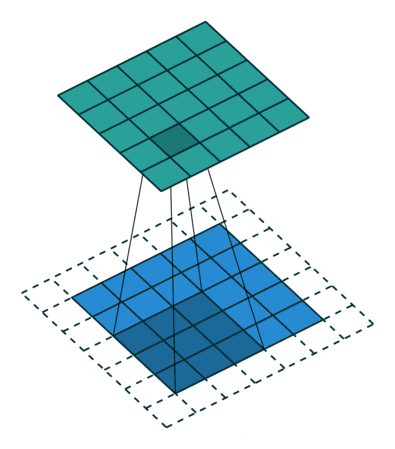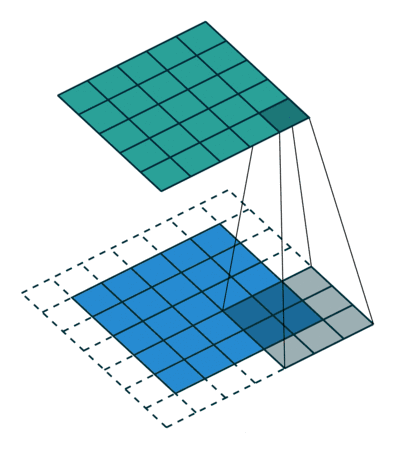
-
池化
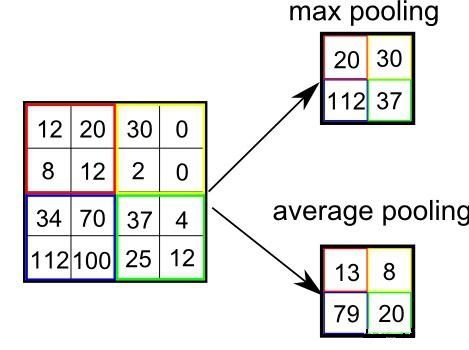
池化的英文是pooling,还有一种叫法是down sampling(下采样),不得不说这两个名词的翻译非常忠于原意,但这种直白的翻译很不好理解。用通俗的语言来描述:池化就是将特征矩阵划分为若干小块,从每个子矩阵中选取一个值替代该子矩阵,这样做的目的是压缩特征矩阵,简化接下来的计算。池化有两种方式:Max Pooling(最大值池化)和Average Pooling(平均值池化),前者是从子矩阵中取最大值,后者是取平均值。

池化比卷积更加容易理解,上面的动图模拟了一个简单的池化过程,黄色的特征矩阵被划分为四个子矩阵,然后按照池化方式从每个子矩阵选取一个数值组成池化矩阵。最大值池化是经常被使用的池化方式,因为选取区域最大值能很好的保持原图的特征。
-
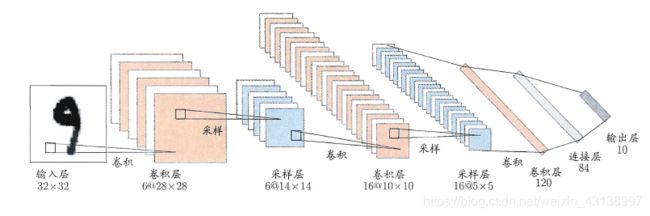
卷积神经网络架构
下面介绍一种常见的卷积神经网络CNN的基本架构,如图所示,网络输入是一个 32 × 32 32×32 32×32 的手写数字图像,输出是其识别结果,CNN 复合多个“卷积层”和“采样层”对输入信号进行加工。然后在连接层实现与输出目标之间的映射。每个卷积层都包含多个特征映射,每个特征映射是一个由多个神经元构成的“平面”,通过一种卷积滤波器提取输入的一种特征。
8. kaggle比赛入门-手写数字识别,下载数据和代码,仔细阅读代码并详细标注代码注释。
参考数据:
https://www.kaggle.com/c/digit-recognizer/overview
参考代码:
https://www.kaggle.com/elcaiseri/mnist-simple-cnn-keras-accuracy-0-99-top-1