kubernetes(kubeadm)集群的安装问题总结
1、kubelet与docker驱动不一致(网上其他解决文案各种尝试无效,最后使用如下方法解决)
异常【kubelet cgroup driver:cgroupfs跟docker cgroup driver:systemd不一致】
异常描述如下:
failed to create kubelet: misconfiguration: kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
原因分析
kubelet文件驱动默认cgroupfs, 而安装的docker使用的文件驱动是systemd, 造成不一致, 导致镜像无法启动。
解决方法:
1)确认docker配置文件daemon.json的驱动配置
[root@master~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
2)修改/var/lib/kubelet/kubeadm-flags.env驱动配置,添加–cgroup-driver=systemd 参数
[root@master~]# cat /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--cgroup-driver=systemd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.1"
#重启docker与kubelet
[root@master~]# systemctl daemon-reload && systemctl restart docker kubelet
2、/system.slice/kubelet.service无法识别
异常【Failed to get system container stats for kubelet.service】
异常描述如下
failed to get container info for "/system.slice/kubelet.service": unknown container "/system.slice/kubelet.service"
解决方案
修改kubelet.service
[root@master~]# vim /lib/systemd/system/kubelet.service
#在ExecStart位置最后面,添加如下配置
--runtime-cgroups=/systemd/system.slice \
--kubelet-cgroups=/systemd/system.slice
3、kubeadm初始化时报[ERROR NumCPU]
异常描述如下
kubeadm init --apiserver-advertise-address=10.10.10.129 --image-repository registry.aliyuncs.com/google_contain
ers --kubernetes-version v1.17.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16W0521 22:45:14.131024 8293 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0521 22:45:14.131095 8293 validation.go:28] Cannot validate kubelet config - no validator is available
[init] Using Kubernetes version: v1.17.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决方案1:
这种错误一般会出现在VMware虚拟机上,因为新建VM时默认为一核,可通过配置,调整成2核,重启系统即可,如下所示:
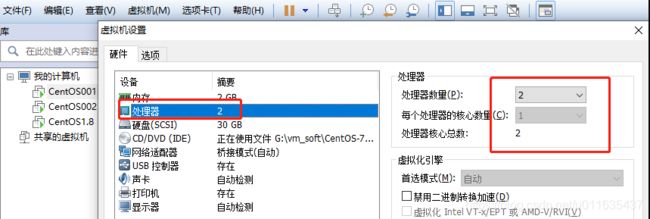
解决方案2:
根据提示添加忽略错误提示–ignore-preflight-errors=…
$ kubeadm init \
--apiserver-advertise-address=10.10.10.129 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.17.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=NumCPU

4、work节点kubeadm join 加入集群时报如下异常
异常描述如下
WARNING: JoinControlPane.controlPlane setting
s will be ignored when control-plane flag is not set.[preflight] Running pre-flight checks
error execution phase preflight: couldn't validate the identity of the API Server: invalid public ke
y hash, expected "format:value"To see the stack trace of this error execute with --v=5 or higher

问题原因:
主节点查看服务状态,发现kube-controller-manager反复重启解决

排查过程
$ kubectl logs -f kube-controller-manager-k8s-master -n kube-system
报错内容
failed to renew lease kube-system/kube-controll er-manager: failed to tryAcquireOrRenew context dead
解决过程
1、排查该问题一般从kube-api和网络链接入手,确认kube-api和网络是正常
2、如果环境为非高可用环境,建议修改leader-elect为false避免kube-controller-manager定期去连接kube-api更新endpoint,理论也可以避免renew超时退出问题。
本人的环境是调度出现问题。

5、kubectl get nodes 时coredns一直处于Pending状态
异常描述如下:
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-9d85f5447-9n2rg 0/1 Pending 0 8m53s
kube-system coredns-9d85f5447-p5csb 0/1 Pending 0 8m52s
kube-system etcd-k8s-master 1/1 Running 0 9m
kube-system kube-apiserver-k8s-master 1/1 Running 0 9m
kube-system kube-controller-manager-k8s-master 1/1 Running 5 9m
kube-system kube-flannel-ds-amd64-7sgw2 1/1 Running 0 4m43s
kube-system kube-proxy-kgb2k 1/1 Running 0 8m53s
kube-system kube-scheduler-k8s-master 1/1 Running 4 9m
排查过程
$ kubectl logs -f coredns-9d85f5447-9n2rg -n kube-system
Unable to connect to the server: net/http: TLS handshake timeout
解决过程:
主要原因是master节点内存过低,执行过程缓慢,如果没有加内存, 预计需要15分钟才会达到正常。所以部署过程尽量满足机器至少2G内存,2个核心来测试,否则时间都花在等待上了。
建议大家部署时使用二进制来安装部署,排查与解决问题都比kubeadm方式来得快速。