Vue+element+Nodejs学习记录(1)
目前的打算是前端用Vue+element,后端用Nodejs的Express框架,实现一个展示页面和后台管理页面。打算记录学习过程。
推荐两个教程:
https://www.cnblogs.com/xifengxiaoma/tag/element/
https://juejin.im/post/59097cd7a22b9d0065fb61d2#heading-1
https://panjiachen.github.io/vue-element-admin-site/zh/guide/
https://blog.csdn.net/sps900608/article/category/7482283/1
1.Nodejs介绍
JS和Nodejs
1、ES 定义了语法规则,JS和Nodejs必须遵守
2、js js=ES+web API(DOM,BOM,事件绑定,ajax)
3、node.js node.js=ES+nodejs API(处理http,处理文件等) ,两者结合,可完成server端的任何操作
Commonjs和ES6模块使用规范
//Commonjs
//math.js
let add=(x,y)=>{
return x+y;
}
let sub=(x,y)=>{
return x-y;
}
module.exports={
add:add,
sub:sub
};
let math=require('./math');
let test=math.add(3,3);
console.log(test);
//ES6模块化
//lib.js
let bar=function(){
console.log('this is bar funciton');
};
let foo=function(){
console.log('this is foo function');
};
export {bar,foo}
//加载 lib.js文件
import {bar,foo,test,obj} from './lib'
foo();//this is foo function
server开发和前端开发的区别
环境思维工具的区别,而不是语言的区别
1.服务的稳定性:server端可能会遭受各种攻击和误操作,单个客户端可以意外挂掉,但是服务端不能
2.考虑内存和CPU(优化和扩展):客户端独占一个浏览器,内存和CPU都不是问题,但是 server 端要承载很多请求,CPU和内存都是稀缺资源
3.日志记录:前端也会参与写日志,但是只是日志的发起方,不关心后续;server端要记录日志,存储日志,分析日志
4.安全: server端要随时准备接受各种恶意攻击(如越权操作,数据库攻击等),前端则少很多
5.集群和服务拆分:流量扩大,解决机器的负荷
2.HTTP请求(get和post)
HTTP请求解析过程 (简单概括)
1.域名解析
用户输入网址,由域名系统DNS解析输入的网址;
2.TCP的3次握手
通过域名解析出的IP地址来向web服务器发起TCP连接请求,如果3次握手通过,则与web服务端建立了可靠的连接;
3.发送http请求
web客户端向web服务端发送请求;
4.接收http响应
web客户端接收来自web服务端的响应,包含各种根据请求反馈的数据;
5.web客户端(浏览器)解释响应
最后由浏览器解析响应里的数据,即HTML代码,以及HTML代码中请求的资源,然后由浏览器呈现给用户。
get请求和post请求
get请求:
1.get请求,即客户端要向server端获取数据,如查询博客列表
2.通过querystring来传递数据,如a.html?a=100&b=200
3.浏览器直接访问,就发送get请求
const server = http.createServer((req,res) => {
console.log(req.method); //GET
const url = req.url; //获取请求的完整 url
//querystring.parse("name=whitemu&sex=man&sex=women");
/*
return:
{ name: 'whitemu', sex: [ 'man', 'women' ] }
*/
req.query = querystring.parse(url.split('?')[1]); //解析 querystring
res.end(JSON.stringfy(req.query));//将对象转换成字符串,res.end返回一个字符串
})
附注:
querystring.parse将字符串转成对象,其实就是把url上带的参数串转成数组对象。
JSON.stringify() 方法是将一个JavaScript值(对象或者数组)转换为一个 JSON字符串,JSON.parse() 方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象。
//JSON.parse()
var json = '{"result":true, "count":42}';
obj = JSON.parse(json);
console.log(obj);
console.log(obj.result);
> { result: true, count: 42 }
> true
//JSON.stringify()
JSON.stringify({}); // '{}'
JSON.stringify(true); // 'true'
JSON.stringify("foo"); // '"foo"'
JSON.stringify([1, "false", false]); // '[1,"false",false]'
JSON.stringify({ x: 5 }); // '{"x":5}'
参考文章:
https://blog.csdn.net/qq_34645412/article/details/80087829
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/JSON/parse
post请求:
1.post请求,即客户端要向服务端传递数据,如新建博客
2.通过post data传递数据
3.浏览器无法直接模型,需要手写j,或者通过postman
post接收数据是通过数据流的方式,数据流就是所谓的stream。
post方式发送的数据,可大可小。小的话还好,数据量大的时候,不阔能一次性接收,而是分流接收
每次接收的到数据都会触发 req.on(‘data’,chunk=>{}),当接收完之后就会触发req.end 事件
const server = http.createServer((req,res) => {
if(req.method === 'POST'){ //POST
//数据格式
console.log('content-type',req.headers['content-type']);
//接收数据
let postData = ""
req.on('data',chunk => {
postData += chunk.toString();
})
req.on('end', () => {
console.log(postData);
res.end('hello world')
})
}
})
get和post
const http = require('http')
const querystring = require('querystring')
const server = http.createServer((req, res) => {
const method = req.method
const url = req.url
const path = url.split('?')[0]
const query = querystring.parse(url.split('?')[1])
// 设置返回格式为 JSON
res.setHeader('Content-type', 'application/json')
// 返回的数据
const resData = {
method,
url,
path,
query
}
// 返回
if (method === 'GET') {
res.end(
JSON.stringify(resData)
)
}
if (method === 'POST') {
let postData = ''
req.on('data', chunk => {
postData += chunk.toString()
})
req.on('end', () => {
resData.postData = postData
console.log(postData)
// 返回
res.end(
JSON.stringify(resData)
)
})
}
})
server.listen(8000)
console.log('OK')
3.搭建开发环境
1.初始化 npm 环境: npm init -y
2. package.json 的 main 值默认 index.js 为主程序
3. bin 目录里面一般为可执行文件
4. nodemon: 检测文件变化,自动重启 node
5.cross-env: 设置环境
5. 安装 nodemon 和 cross-env: npm install nodemon cross-env --save-dev --registry=https://registry.npm.taobao.org
6. process.env.NODE_ENV: 获取当前运行环境
nodemon监测文件变化,自动重启Node
cross-env设置环境变量,之后做环境区分使用,运行跨平台设置和使用环境变量的脚本
process是node的全局变量,process.env.NODE_ENV可以获取当前运行环境
cross-env介绍
这个小插件主要解决 windows 下 无法设置 NODE_ENV=development 这个东西. 因为程序可以根据 NODE的环境变量,做出不同选择,进行不同的设置.
这个在 linux 下是可以设置的,但在 windows 下不行
package.json配置
//process是node提供的全局变量。
dev: cross-env NODE_ENV=dev nodemon ./bin/www.js //开发环境
prd: cross-env NODE_ENV=production nodemon ./bin/www.js //生产环境
参考文章:
http://elickzhao.github.io/2017/06/nodejs%20%E7%9A%84%20cross-env%20%E7%9A%84%E4%BD%BF%E7%94%A8%E5%8F%8A%E4%BB%8B%E7%BB%8D/
https://segmentfault.com/a/1190000005811347
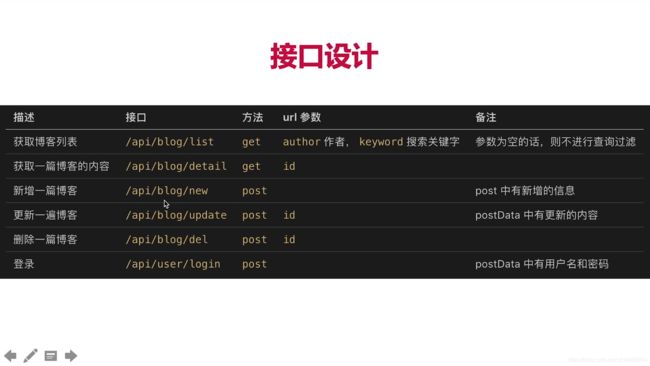
4.接口设计
app.js
//引用和处理路由(handleBlogRouter和handleUserRouter)
const handleBlogRouter = require('./src/router/blog')
const handleUserRouter = require('./src/router/user')
const serverHandle = (req,res) => {
//设置返回格式 JSON
res.setHeader('Content-type','application/json')
//处理blog路由
const blogData = handleBlogRouter(req,res)
if(blogData){
res.end(
JSON.stringify(blogData)
)
return
}
//处理user路由
const userData = handleUserRouter(req,res)
if(userData){
res.end(
JSON.stringify(userData)
)
return
}
//未命中路由,返回404
res.writeHead(404,{"Content-type":"text/plain"})
res.write("404 Not Found\n")
res.end()
}
module.exports = serverHandle
src/router/blog.js
const handleBlogRouter = (req,res)=> {
const method = req.method //GET POST
const url = req.url //获取url
const path = url.split('?')[0]
//获取博客列表
if (method === 'GET' && path === '/api/blog/list') {
return {
msg : '这是获取博客列表的接口'
}
}
//获取博客详情
if(method === 'POST' && path === '/api/blog/detail'){
return {
msg : '这是获取博客详情的接口'
}
}
//新建一篇博客
if(method === 'POST' && path === '/api/blog/new'){
return {
msg : '这是新建博客详情的接口'
}
}
//更新一篇博客
if(method === 'POST' && path === '/api/blog/update'){
return {
msg : '这是更新博客详情的接口'
}
}
//一篇博客
if(method === 'POST' && path === '/api/blog/del'){
return {
msg : '这是删除一篇博客的接口'
}
}
}
module.exports = handleBlogRouter
src/router/user.js
const handleUserRouter = (req,res)=> {
const method = req.method //GET POST
const url = req.url //获取url
const path = url.split('?')[0]
//获取博客列表
if (method === 'POST' && path === '/api/user/login') {
return {
msg : '这是登陆的接口'
}
}
}
module.exports = handleUserRouter
虽然路由没有写具体处理代码,但是展示了路由的使用和路由引用和处理,基本的路由创建,路由内容和路由使用有个框架,下一步就是具体代码编写和逻辑进一步划分。
5.博客系统的分层
上面只是把路由分离出来,我们要如何进一步划分代码见逻辑呢?
第一层是bin/www.js,这一层完全是createServer的逻辑。这个逻辑跟外面的业务代码没有任何关系。(关于数据的处理,使用回调函数,放在了app.js里面)
第二层是app.js,这是一个系统中关于http的基本设置(比如:设置返回格式JSON、获取path、解析jquery处理相关模块的路由和设置404情况),跟业务代码关系也不大。(只是负责调用路由,关于路由的具体逻辑放在router中)
第三层router,第二层中引用的路由,所以第三层就是路由。路由就有涉及到一些业务代码,有了会返回给请求一个正确的格式数据。这个路由会去处理一些数据,返回正确的格式。具体数据的处理它不用管,它只负责路由相关的事情。
第四层controller,处理和管理数据,到了controller里面就不用关心request和response、path、query等东西,就只关心数据。然后返回数据,数据之后怎么处理,controller是不管的。
第五层model
附注
第一层和第二层中的www.js 和 app.js 的目的不一样,第一个是启动服务,第二个是加载注册各种业务组件,两者应该分离,符合设计原则。
第一层(创建服务器)、第二层(系统基本设置)、第三层(路由)都属于 MVC 的C ,即 controller ,MVC 是一个大概念上的分层,不代表每个部分不能再分层。如果项目再复杂,C 和 M 之间可能还要加一个 services 层,如 egg.js 的目录,就有 services 层。
router层负责拿参数
controller层负责数据的计算 最终拿到数据
model层负责 生成一个实例 将data message errno 返回给前端
6.Nodejs读取文件
const fs = require('fs')
const path = require('path')
//resolve可以通过拼接多个步骤的方式把文件名拼出来,__dirname是指当前目录
const fullFileName = path.resolve(__dirname,'files','a.json')
fs.readFile(fullFileName,(err,data) => {
if(err){
console.error(err)
return
}
//fs.readFile 读出来的data数据是二进制的流文件,所以要经过toString转换
console.log(data.toString())
})
我们要注意resolve和toString的使用。