pandas1-数据的增删改查
文章目录
- 核心数据结构
- Series
- DataFrame
- 数据查改
- 对Series操作
- 对DataFrame操作
- 对单列数据访问
- 对多列数据访问
- 对某几行访问
- loc与iloc
- ix方法
- 数据修改
- 更新修改DataFrame中的数据
- 为DataFrame增加数据
- 删除数据
- 数据排序
- 描述分析DataFrame数据
- 获取数据
- 文本文件读取
- Excel文件读取
- 存储数据
- 文本文件存储
- Excel文件存储
核心数据结构
Series
Series可以理解为一个一维的数组,只是index可以自己改动。类似于定长的有序字典,有Index和value。
创建:pd.Series(data,index=)。
打印的时候按照index赋值的顺序,
index参数默认从0开始的整数,也是Series的绝对位置,即使index被赋值之后,绝对位置不会被覆盖。
Series可以通过以下形式创建:
python的dict、 numpy当中的ndarray、 具体某个数值。index赋值必须是list类型。
s1=pd.Series(data: Any = None,
index: Any = None,
dtype: Optional[dtype] = None,
name: Any = None,
copy: Any = False,
fastpath: bool = False)
例:
import pandas as pd
import numpy
data=[1,2,3]
index=["a","b","c"]
s1=pd.Series()
print(s1)
结果:
a 1
b 2
c 3
DataFrame
DataFrame是一个类似于表格的数据类型,有这样一些参数:data (方框内的数据): numpy ndarray (structured or homogeneous), dict, or DataFrame
s1=pd.DataFrame(data: Any = None,
index: Any = None,
dtype: Optional[dtype] = None,
name: Any = None,
copy: Any = False,
fastpath: bool = False)
index(行索引索引) : Index or array-like
columns (列索引): Index or array-like
dtype(data的数据类型) : dtype, default None
DataFrame可以理解为一个二维数组,index有两个维度,可更改。
例:
import pandas as pd
df = pd.DataFrame([['Snow', 'M', 22], ['Tyrion', 'M', 32], ['Sansa', 'F', 18], ['Arya', 'F', 14]],columns=['name', 'gender', 'age'])
结果:
name gender age
0 Snow M 22
1 Tyrion M 32
2 Sansa F 18
3 Arya F 14
数据查改
对数据操作简单来说就是通过索引查看:(1) 通过index对应的标签;(2)通过绝对位置查看。
如果通过绝对位置查看,会使用s[XXX],XXX可以是绝对位置的数字,列表,或者表达式等。
基础属性

对Series操作
对Series操作简单来说就是通过索引查看:(1) 通过index对应的标签;(2)通过绝对位置查看。
如果通过绝对位置查看,会使用s[XXX],XXX可以是绝对位置的数字,列表,或者表达式等
对DataFrame操作
对单列数据访问
对单列数据的访问:DataFrame的单列数据为一个Series。根据DataFrame的定义可以知晓DataFrame 是一个带有标签的二维数组,每个标签相当每一列的列名。df.a df[‘a’]
对多列数据访问
对多列数据访问:访问DataFrame多列数据可以将多个列索引名称视为一个列表,df[[‘a’,‘b’]]
对某几行访问
对某几行访问:
- 如果只是需要访问DataFrame某几行数据的实现方式则采用数组的选取方式,使用“:”,如df[1:3],只能分割一次
- head和tail也可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取的连续数据 。默认参数为访问5行,只要在方法后方的“()”中填入访问行数即可实现目标行数的查看。
loc与iloc
loc方法是针对DataFrame索引名称的切片方法,如果传入的不是索引名称,那么切片操作将无法执行。 利用loc方法,能够实现所有单层索引切片操作。loc方法使用方法如下。
DataFrame.loc[行索引名称或条件,列索引名称]
iloc和loc区别是iloc接收的必须是行索引和列索引的位置。iloc方法的使用方法如下。
DataFrame.iloc[行索引位置,列索引位置]
- 使用loc方法和iloc实现多列切片,其原理的通俗解释就是将多列的列名或者位置作为一个列表或者数据传 入。
- 使用loc,iloc方法可以取出DataFrame中的任意数据。
- loc内部还可以传入表达式,结果会返回满足表达式的所有值。
- loc更加灵活多变,代码的可读性更高,iloc的代码简洁,但可读性不高。具体在数据分析工作中使用哪一 种方法,根据情况而定,大多数时候建议使用loc方法。
- 在loc使用的时候内部传入的行索引名称如果为一个区间,则前后均为闭区间;iloc方法使用时内部传入的 行索引位置或列索引位置为区间时,则为前闭后开区间。
ix方法
ix方法更像是loc和iloc两种切片方法的融合。ix方法在使用时既可以接收索引名称也可以接收索引位置。 其使用方法如下。
DataFrame.ix [行索引的名称或位置或者条件,列索引名称或位置]
使用ix方法时有个注意事项,第一条,当索引名称和位置存在部分重叠时,ix默认优先识别名称。
控制ix方法需要注意以下几点。
- 使用列索引名称,而非列索引位置。主要用来保证代码可读性。
- 使用列索引位置时,需要注解。同样保证代码可读性。
- 除此之外ix方法还有一个缺点,就是在面对数据量巨大的任务的时候,其效率会低于loc和iloc方法,所以 在日常的数据分析工作中建议使用loc和iloc方法来执行切片操作。
数据修改
更新修改DataFrame中的数据
更改DataFrame中的数据,原理是将这部分数据提取出来,重新赋值为新的数据。
需要注意的是,数据更改直接针对DataFrame原数据更改,操作无法撤销,如果做出更改,需要对更改 条件做确认或对数据进行备份。
eg: 请把上个例子中Snow年龄改为25 打开practice.py文件
#iat取某个单值,只能数字索引 df.iat[1,1]#第1行,1列
#at取某个单值,只能index和columns索引名称df.at[‘one’,‘a’]#one行,a列
为DataFrame增加数据
DataFrame添加一列的方法非常简单,只需要新建一个列索引。并对该索引下的数据进行赋值操作即可。
新增的一列值是相同的则直接赋值一个常量即可。
eg:给上个例子学生加上score一列。分别为:80,98,67,90
给上个例子学生加上一行信息 信息分别为:lisa F 19 100
例:
import numpy as np
import pandas as pd
import cv2
# 创建DataFrame
df = pd.DataFrame([['Snow', 'M', 22], ['Tyrion', 'M', 32], ['Sansa', 'F', 18], ['Arya', 'F', 14]],
columns=['name', 'gender', 'age'])
s2 = pd.DataFrame(data=[["chise", "M", 20]], columns=['name', 'gender', 'age'],index=["4"])
print(df)
print(s2)
#注意一定要等于,因为append是不会把值插入df的。。妈的
df=df.append(s2)
print(df)
删除数据
删除某列或某行数据需要用到pandas提供的方法drop,drop方法的用法如下。
axis为0时表示删除行,axis为1时表示删除列。
drop(labels, axis=0, level=None, inplace=False,errors=‘raise’)

例:
>>> df
name gender age
0 Snow M 22
1 Tyrion M 32
2 Sansa F 18
3 Arya F 14
>>> df.drop(labels=[0])
name gender age
1 Tyrion M 32
2 Sansa F 18
3 Arya F 14
>>>
数据排序
df.sort_index(axis=,ascending=) axis为0/1的参数,表示按行/按列排序;ascending为boolean参数,False表示降序,True表示升序。
df.sort_values(by=,ascending=) by表示按哪一个columns参数排序
>>> df.drop(labels=[0])
name gender age
1 Tyrion M 32
2 Sansa F 18
3 Arya F 14
>>> df.sort_values(by="age")
name gender age
3 Arya F 14
2 Sansa F 18
0 Snow M 22
1 Tyrion M 32
>>>
描述分析DataFrame数据
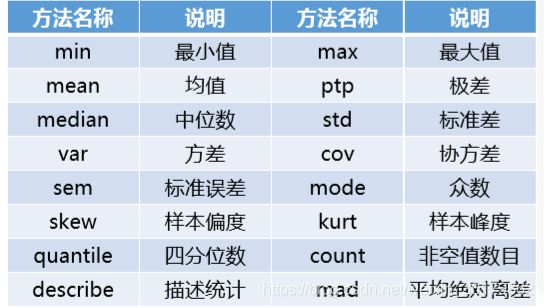
数值型数据的描述性统计主要包括了计算数值型数据的完整情况、最小值、均值、中位数、最大值、四分位数、极差、标准差、方差、协方差和变异系数等。在NumPy库中一些常用的统计学函数如下表所示。
pandas库基于NumPy,自然也可以用这些函数对数据框进行描述性统计。
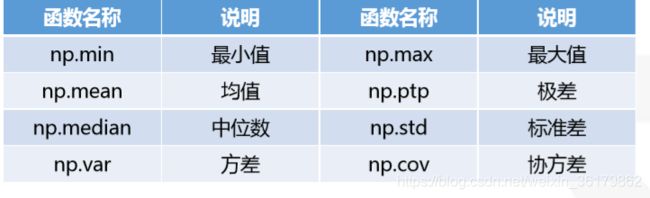
pandas描述性统计方法
平均绝对离差 平均绝对离差指的是各观察值与平均值的 距离总和,然后取其平均数 偏度含义是统计数据分布偏斜方向和程度 的度量,是统计数据分布非对称程度的数 字特征。 峰度,表征概率密度分布曲线在平均值处峰值高低的特征数,反映了峰部的尖度。
获取数据
文本文件读取
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
csv是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字符分隔文件,文件以纯文本形 式存储表格数据(数字和文本)。
- 使用read_table来读取文本文件。 pandas.read_table(filepath_or_buffer, sep=’\t’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)
- 使用read_csv函数来读取csv文件。 pandas.read_csv(filepath_or_buffer, sep=’,’, header=’infer’, names=None, index_col=None, dtype=None, engine=None, nrows=None)

read_table和read_csv函数中的sep参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时 候,每一行数据将连成一片。
header参数是用来指定列名的,如果是None则会添加一个默认的列名。
encoding代表文件的编码格式,常用的编码有utf-8、utf-16、gbk、gb2312、gb18030等。如果编码 指定错误数据将无法读取,IPython解释器会报解析错误
例:
#读取电影详情表 movies
# header是否读取表头,为none,
# names,没有读取表头的时候这里自定义表头
#sep="::"分隔符
# engine='python' 使用的软件,默认为C??
movies=pd.read_table(r'C:\Users\Cs\Desktop\pandas\pandas_day_02\pandas_student\movies.dat',header=None,names=["MovieID",'Title','Genres'],sep="::",engine='python')
print(movies.head(5))
#读取评分表 Ratings
ratings=pd.read_table(r'C:\Users\Cs\Desktop\pandas\pandas_day_02\pandas_student\ratings.dat',header=None,names=['UserID','MoiveID','Rating','Timestamp'],sep="::",engine='python')
print(ratings.head())
# 读取test.csv表格
csv=pd.read_csv('iris.csv')
print(csv.head())
Excel文件读取
pandas提供了read_excel函数来读取“xls”“xlsx”两种Excel文件。 pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)

存储数据
文本文件存储
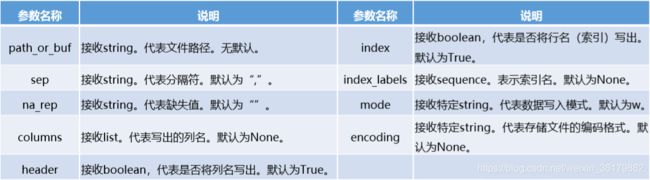
文本文件的存储和读取类似,结构化数据可以通过pandas中的to_csv函数实现以csv文件格式存储文件。 DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None)
Excel文件存储
将文件存储为Excel文件,可以使用to_excel方法。其语法格式如下。 DataFrame.to_excel(excel_writer=None, sheetname=None’’, na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
to_csv方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参数名称为excel_writer,并且 没有sep参数,增加了一个sheetnames参数用来指定存储的Excel sheet的名称,默认为sheet1