数据双向绑定浅析
近期看到一篇文章关于jquerymy.js ,是一个关于数据双向绑定的库,就想先把之前对于angular和vue的双向数据绑定给梳理一下。
数据绑定其实跟框架的设计模式相关,主要有MVC,MVP,MVVM三种,可参考我总结的另一篇文章 浅析MVC,MVP,MVVM
angular数据双向绑定模块:
angular其实是从MVC发展过来(MVC的界面和逻辑关联紧密,数据直接从数据库读取),慢慢演变为MVVM模式(MVVM的界面与viewmodel耦合比较松,界面数据是从viewmodel中获取的,也就是Scope),其实设计模式没什么关系,只要适合自己的项目就可以了。
angular的双向绑定主要是digest循环以及dirty-checking(脏数据检查),包括watch,digest,和apply。
1.Angular在浏览器循环监听事件中添加了自己的digest循环事件(核心)
浏览器一直在监听页面上的事件,当你点击一个按钮等等,操作触发之后,回调函数就会执行,然后你就可以做任何DOM操作,等回调+函数执行完成,浏览器就会相应更新DOM。 angular往里面加了监听事件。
2.watch队列
每次你绑定一些东西到你的UI界面上时你就会往watch队列里插入一条watch。watch就是那个可以检测它监视的model里时候有变化的东西。当我们的模版加载完毕时,Angular解释器会寻找每个directive(指令),然后生成每个需要的watch。
3.digest循环
当浏览器接收到可以被angular context处理的事件时,digest循环就会触发,这个循环包括了两个更小的循环组合起来的,一个是处理evalAsync队列,另一个是watch队列,其实就是digest会遍历我们的watch,然后问它有没有属性和值发生变化了,直到所有的watch队列全部都检查过,一旦有watch改变了,那就要循环从新触发,直到所有的watch都没有变化,这样才能保证所有的model都已经不会再变化了,但是如果循环超过10次的话,那么它将抛出一个异常,这是为了防止无限循环,当digest循环结束时,DOM相应的变化,这就是dirty-checking脏数据检查。
4.最后由apply来确定是否要进入到angular context实践中,调用了就进入,不调用就不用进入,当我们使用ng-click的时候,angular在时间触发的时候回自动封装到一个apply调用,比如我们写一个ng-model=‘data’,当敲入一个a时,时间就会这样调用apply(“data = a”)。之前我使用jquery时不会更新我绑定的东西,就是因为没有调用apply, 我之前在用JS获取一段视频的时长的时候,在使用oncanplay事件来获取时长之后,发现angular并没有将获取到的时长实时通知给界面,所以手动将事件嵌入apply事件,才得以解决。

5. $digest 和 $apply
在Angular中,有$apply和$digest两个函数,它们的差异是什么呢?
最直接的差异是,$apply可以带参数,它可以接受一个函数,上面代码写的例子。$scope.$apply(function(){ … }),然后在应用数据之后,调用这个函数。所以,一般在集成非Angular框架的代码时,可以把代码写在这个里面调用。
apply的内部实现:
function $apply(expr) {
try {
return $eval(expr);
} catch (e) {
$exceptionHandler(e);
} finally {
$root.$digest();
}
}
实例:
var app = angular.module("test", []);
app.directive("increasea", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.a++;
scope.$digest();
});
};
});
app.directive("increaseb", function() {
return function (scope, element, attr) {
element.on("click", function() {
scope.b++;
scope.$digest(); //这个换成$apply即可
});
};
});
app.controller("OuterCtrl", ["$scope", function($scope) {
$scope.a = 1;
$scope.$watch("a", function(newVal) {
console.log("a:" + newVal);
});
$scope.$on("test", function(evt) {
$scope.a++;
});
}]);
app.controller("InnerCtrl", ["$scope", function($scope) {
$scope.b = 2;
$scope.$watch("b", function(newVal) {
console.log("b:" + newVal);
$scope.$emit("test", newVal);
});
}]);
现在能看出差别了,在increase b按钮上点击,这时候,a跟b的值其实都已经变化了,但是界面上的a没有更新,直到点击一次increase a,这时候刚才对a的累加才会一次更新上来。


怎么解决这个问题呢?只需在increaseb这个指令的实现中,把$digest换成$apply即可。

区别:当调用$digest的时候,只触发当前作用域和它的子作用域上的监控,但是当调用$apply的时候,会触发作用域树上的所有监控。
因此,从性能上讲,如果能确定自己作的这个数据变更所造成的影响范围,应当尽量调用$digest,只有当无法精确知道数据变更造成的影响范围时,才去用$apply,很暴力地遍历整个作用域树,调用其中所有的监控。
从另外一个角度,我们也可以看到,为什么调用外部框架的时候,是推荐放在$apply中,因为只有这个地方才是对所有数据变更都应用的地方,如果用$digest,有可能临时丢失数据变更。
VUE数据双向绑定模块:
VUE之前我一直没正式接触使用过,最近也正开始学习,所以可能有点不全面。
VUE双向绑定其实是利用了Object.defineProperty(要操作的对象,要定义或修改的对象属性名,具体行为)这个方法重新定义了对象获取属性值(get)和设置属性值(set)的操作来实现的(核心)。
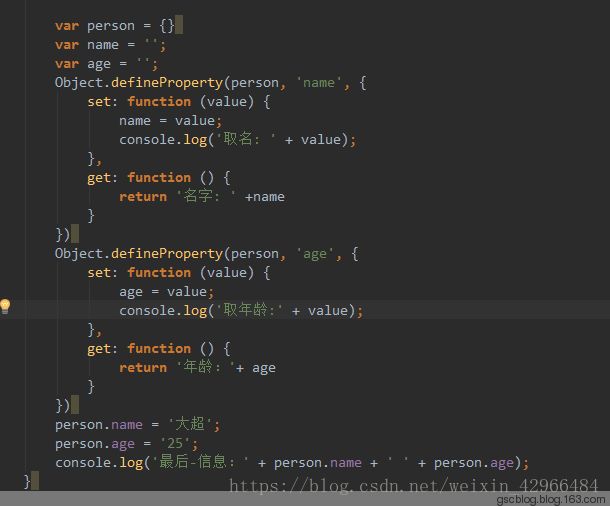

自己尝试了一下,因为之前写过JAVA,所以感觉就是跟JAVA中定义属性是一个意思,无非是JAVA中有private等性质。
VUE采用的是数据劫持(通过Object.defineProperty劫持各个属性)结合发布者-订阅者的模式,发布者就是向订阅者告知事件已经到达了,你可以执行相应动作了,而订阅者就是在某些时间到达的时候可以通知它并执行相应的动作。
-
设置一个监听器,也就是Observe(发布者),用来监听所有的属性。Observe的就是之前写的Object.defineProperty(),因为属性值一般都是比较多,所有采用递归的方式遍历所有的属性值,从而达到监听所有属性的功能。
-
指令解析器Compile,对页面上的每个元素节点的指令进行扫描和解析,根据指令模板替换数据,以及绑定相应的更新函数。
-
Watcher(订阅者)是连接Observe和compile的桥梁,可以收到每个属性变化的通知,也就是说Observe一旦监听到属性有了变动,就需要去通知watcher,watcher收到属性变化然后去通知Compile并执行相应的更新函数,然后更新界面。
总结:总的来说,数据的双向绑定,难点是在data改变引起view改变,因为view改变的话,比如input,可以通过监听oninput事件来实现。但是当数据data改变时,处理就比较麻烦,angular采用的是apply调用的方法,而Vue是通过Object.defineProperty()对属性设置一个set函数,当数据改变了就会触发这个函数的方式。两个进行对比来说,因为angular的数据绑定是脏数据检测,简单的说就是监测新值和旧值有没有变化,这样就要定时去检测,而vue触发set方法,各有其优缺点,比如:
比如一个带checkbox的列表,顶部有一个全选,假设这列表有200条数据,点一下全选,如果单条变更能导致界面reflow,那样的话vue的set/get将对导致大量reflow,而angular则是一次性处理完毕,更新所有数据,把结果数据一次应用到界面。
同理,如果只改变一个属性,angular会监听全部,而vue只是set/get某个,自然vue好一点。
总之最好的办法是了解各自使用方式的差异,考虑出它们性能的差异所在,在不同的业务场景中,避开最容易造成性能瓶颈的用法。