基于U-net的医学影像分割 / pytorch实现
一、简介
U-net是一种基于CNN神经网络的图像分割模型,模型主要包括两个部分:对图片的特征提取与上采样。模型的巧妙之处在于在上采样时,会将上采样结果与特征提取中对应通道的特征进行拼接,然后接着进行卷积运算。这样能更多地利用原图片的特征信息。网络结构图与大写字母U非常类似,因此称为U-net,模型结构图如下。

二、U-net实现
由于数图课程的作业要求,作为一个初学者,近期学习并实现了U-net模型,现将过程做一个简单的回顾,希望能给有需要的初学者一点小小的帮助。
1、实验环境
本次实验环境如下:Ubuntu 16.04,python 3.6,cuda 9.0,pytorch
数据集:数据使用ISBI Challenge 2012的数据(已存放在GitHub中)
2、U-net模型
import torch
from torch import nn
# 卷积层代码块,进行两次卷积晕眩
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, input):
return self.conv(input)
# 模型实现,可参照模型图
class Unet(nn.Module):
def __init__(self,in_ch,out_ch):
super(Unet, self).__init__()
self.conv1 = DoubleConv(in_ch, 64)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = DoubleConv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = DoubleConv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.conv4 = DoubleConv(256, 512)
self.pool4 = nn.MaxPool2d(2)
self.conv5 = DoubleConv(512, 1024)
self.up6 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.conv6 = DoubleConv(1024, 512)
self.up7 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.conv7 = DoubleConv(512, 256)
self.up8 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.conv8 = DoubleConv(256, 128)
self.up9 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.conv9 = DoubleConv(128, 64)
self.conv10 = nn.Conv2d(64, out_ch, 1)
def forward(self, x):
c1 = self.conv1(x)
p1 = self.pool1(c1)
c2 = self.conv2(p1)
p2 = self.pool2(c2)
c3 = self.conv3(p2)
p3 = self.pool3(c3)
c4 = self.conv4(p3)
p4 = self.pool4(c4)
c5 = self.conv5(p4)
up_6 = self.up6(c5)
merge6 = torch.cat([up_6, c4], dim=1)
c6=self.conv6(merge6)
up_7 = self.up7(c6)
merge7 = torch.cat([up_7, c3], dim=1)
c7 = self.conv7(merge7)
up_8 = self.up8(c7)
merge8 = torch.cat([up_8, c2], dim=1)
c8 = self.conv8(merge8)
up_9 = self.up9(c8)
merge9 = torch.cat([up_9, c1], dim=1)
c9 = self.conv9(merge9)
c10 = self.conv10(c9)
return c10
3、DataHelper
这里主要是对图片数据进行处理的代码,主要有两个功能:
1、训练集与测试机数据的读取
2、将预测结果进行处理
from torch.utils.data import Dataset
import PIL.Image as Image
import os
import numpy as np
def train_dataset(img_root, label_root):
imgs = []
n = len(os.listdir(img_root))
for i in range(n):
img = os.path.join(img_root, "%d.png" % i)
label = os.path.join(label_root, "%d_mask.png" % i)
imgs.append((img, label))
return imgs
def test_dataset(img_root):
imgs = []
n = len(os.listdir(img_root))
for i in range(n):
img = os.path.join(img_root, "%d.png" % i)
imgs.append(img)
return imgs
class TrainDataset(Dataset):
def __init__(self, img_root, label_root, transform=None, target_transform=None):
imgs = train_dataset(img_root, label_root)
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
x_path, y_path = self.imgs[index]
img_x = Image.open(x_path)
img_y = Image.open(y_path)
if self.transform is not None:
img_x = self.transform(img_x)
if self.target_transform is not None:
img_y = self.target_transform(img_y)
return img_x, img_y
def __len__(self):
return len(self.imgs)
class TestDataset(Dataset):
def __init__(self, img_root, transform=None, target_transform=None):
imgs = test_dataset(img_root)
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
x_path = self.imgs[index]
img_x = Image.open(x_path)
if self.transform is not None:
img_x = self.transform(img_x)
return img_x
def __len__(self):
return len(self.imgs)
# 调色板
Sky = [128,128,128]
Building = [128,0,0]
Pole = [192,192,128]
Road = [128,64,128]
Pavement = [60,40,222]
Tree = [128,128,0]
SignSymbol = [192,128,128]
Fence = [64,64,128]
Car = [64,0,128]
Pedestrian = [64,64,0]
Bicyclist = [0,128,192]
Unlabelled = [0,0,0]
COLOR_DICT = np.array([Sky, Building, Pole, Road, Pavement,
Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist, Unlabelled])
# 按照需求把结果处理成更容易辨认的结果,由于本次实验为图像分割,所以将num_class设为2,即分成两种颜色。
def labelVisualize(num_class,color_dict,img):
img = img[:,:,0] if len(img.shape) == 3 else img
img_out = np.zeros(img.shape + (3,))
for i in range(num_class):
img_out[img == i,:] = color_dict[i]
return img_out / 2554、main
完成以上准备后,在这里进行模型的训练。分为10个epoch对数据进行训练,取平均loss最小的model作为最终模型。
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torchvision.transforms import transforms
from unet import Unet
from DataHelper import *
from tqdm import tqdm
import numpy as np
import skimage.io as io
PATH = './model/unet_model.pt'
# 是否使用cuda
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# mask只需要转换为tensor
y_transforms = transforms.ToTensor()
def train_model(model, criterion, optimizer, dataload, num_epochs=10):
best_model = model
min_loss = 1000
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
# print('-' * 10)
dt_size = len(dataload.dataset)
epoch_loss = 0
step = 0
for x, y in tqdm(dataload):
step += 1
inputs = x.to(device)
labels = y.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# print("%d/%d,train_loss:%0.3f" % (step, (dt_size - 1) // dataload.batch_size + 1, loss.item()))
print("epoch %d loss:%0.3f" % (epoch, epoch_loss/step))
if (epoch_loss/step) < min_loss:
min_loss = (epoch_loss/step)
best_model = model
torch.save(best_model.state_dict(), PATH)
return best_model
# 训练模型
def train():
model = Unet(1, 1).to(device)
batch_size = 1
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters())
train_dataset = TrainDataset("dataset/train/image", "dataset/train/label", transform=x_transforms,target_transform=y_transforms)
dataloaders = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
train_model(model, criterion, optimizer, dataloaders)
# 保存模型的输出结果
def test():
model = Unet(1, 1)
model.load_state_dict(torch.load(PATH))
test_dataset = TestDataset("dataset/test", transform=x_transforms,target_transform=y_transforms)
dataloaders = DataLoader(test_dataset, batch_size=1)
model.eval()
import matplotlib.pyplot as plt
plt.ion()
with torch.no_grad():
for index, x in enumerate(dataloaders):
y = model(x)
img_y = torch.squeeze(y).numpy()
img_y = img_y[:, :, np.newaxis]
img = labelVisualize(2, COLOR_DICT, img_y) if False else img_y[:, :, 0]
io.imsave("./dataset/test/" + str(index) + "_predict.png", img)
plt.pause(0.01)
plt.show()
if __name__ == '__main__':
print("开始训练")
train()
print("训练完成,保存模型")
print("-"*20)
print("开始预测")
test()
三、结果及小结
1、训练结果
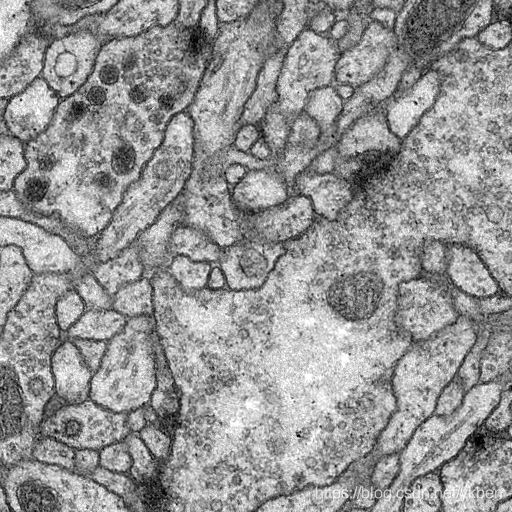
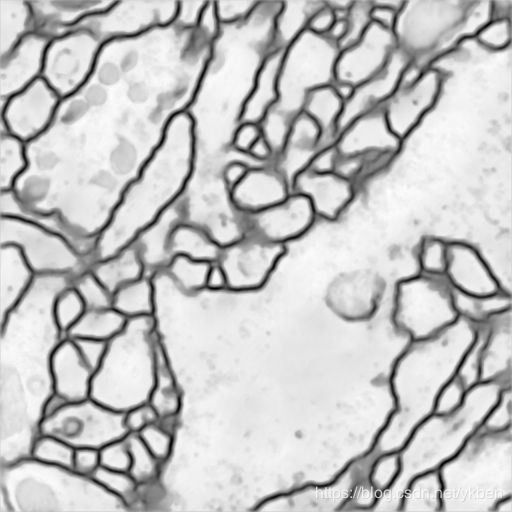
2、小结
本次实验主要参考的资料有https://github.com/JavisPeng/u_net_liver、https://github.com/zhixuhao/unet
与https://github.com/zhixuhao/unet中的结果进行对比,很容易看出还是有差距的,原因可能是没有进行数据增强处理,仅使用30张图片进行训练有一定的局限性。
U-net模型还是比较简明易懂的,但是实验过程确实非常曲折,在环境配置上花了非常多的时间,最后实在是觉得自己的笔记本顶不住,才借了实验室的电脑进行实验。在实验的开始,由于对pytorch的不熟悉,在输入的处理上花费了较多的精力,不过最后能完成还是挺开心的。也感谢这次作业吧,让自己对深度学习有多一点的学习了解。
完整的代码我已存放在Github中,有需要可以康康。