yolov3实现之模型训练,测试,检测
前面几篇博客已经对yolov3的具体实现模块已经做了大致的讲解,基于pytorch进行模型训练,测试,检测只是对前面的模块进行组合实现,主要的还是数据的准备,加载,模型搭建,代价函数的求解。
train.py
from __future__ import division
from models import *
from utils.logger import *
from utils.utils import *
from utils.datasets import *
from utils.parse_config import *
from test import evaluate
from terminaltables import AsciiTable
import os
import sys
import time
import datetime
import argparse
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable
import torch.optim as optim
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--epochs", type=int, default=100, help="number of epochs")
parser.add_argument("--batch_size", type=int, default=8, help="size of each image batch")
parser.add_argument("--gradient_accumulations", type=int, default=2, help="number of gradient accums before step")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file")
parser.add_argument("--pretrained_weights", type=str, help="if specified starts from checkpoint model")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_interval", type=int, default=1, help="interval between saving model weights")
parser.add_argument("--evaluation_interval", type=int, default=1, help="interval evaluations on validation set")
parser.add_argument("--compute_map", default=False, help="if True computes mAP every tenth batch")
parser.add_argument("--multiscale_training", default=True, help="allow for multi-scale training")
opt = parser.parse_args()
print(opt)
logger = Logger("logs")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs("output", exist_ok=True)
os.makedirs("checkpoints", exist_ok=True)
# Get data configuration
data_config = parse_data_config(opt.data_config)
train_path = data_config["train"]
valid_path = data_config["valid"]
class_names = load_classes(data_config["names"])
# Initiate model
model = Darknet(opt.model_def).to(device)
model.apply(weights_init_normal)
# If specified we start from checkpoint
if opt.pretrained_weights:
if opt.pretrained_weights.endswith(".pth"):
model.load_state_dict(torch.load(opt.pretrained_weights))
else:
model.load_darknet_weights(opt.pretrained_weights)
# Get dataloader
#加载数据
dataset = ListDataset(train_path, augment=True, multiscale=opt.multiscale_training)
#整合为torch批量处理格式
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
pin_memory=True,
collate_fn=dataset.collate_fn,
)
#网络优化器
optimizer = torch.optim.Adam(model.parameters())
metrics = [
"grid_size",
"loss",
"x",
"y",
"w",
"h",
"conf",
"cls",
"cls_acc",
"recall50",
"recall75",
"precision",
"conf_obj",
"conf_noobj",
]
#迭代实现模型训练
for epoch in range(opt.epochs):
model.train()
start_time = time.time()
for batch_i, (_, imgs, targets) in enumerate(dataloader):
batches_done = len(dataloader) * epoch + batch_i
imgs = Variable(imgs.to(device))
targets = Variable(targets.to(device), requires_grad=False)
loss, outputs = model(imgs, targets) #前向获取模型的图片,标签
loss.backward() #反向传播
#参数更新
if batches_done % opt.gradient_accumulations:
# Accumulates gradient before each step
optimizer.step()
optimizer.zero_grad()
# ----------------
# Log progress
# ----------------
log_str = "\n---- [Epoch %d/%d, Batch %d/%d] ----\n" % (epoch, opt.epochs, batch_i, len(dataloader))
metric_table = [["Metrics", *["YOLO Layer {i}" for i in range(len(model.yolo_layers))]]]
# Log metrics at each YOLO layer
for i, metric in enumerate(metrics):
formats = {m: "%.6f" for m in metrics}
formats["grid_size"] = "%2d"
formats["cls_acc"] = "%.2f%%"
row_metrics = [formats[metric] % yolo.metrics.get(metric, 0) for yolo in model.yolo_layers]
metric_table += [[metric, *row_metrics]]
# Tensorboard logging
tensorboard_log = []
for j, yolo in enumerate(model.yolo_layers):
for name, metric in yolo.metrics.items():
if name != "grid_size":
tensorboard_log += [("{name}_{j+1}", metric)]
tensorboard_log += [("loss", loss.item())]
logger.list_of_scalars_summary(tensorboard_log, batches_done)
log_str += AsciiTable(metric_table).table
log_str += "\nTotal loss {loss.item()}"
# Determine approximate time left for epoch
epoch_batches_left = len(dataloader) - (batch_i + 1)
time_left = datetime.timedelta(seconds=epoch_batches_left * (time.time() - start_time) / (batch_i + 1))
log_str += "\n---- ETA {time_left}"
print(log_str)
model.seen += imgs.size(0)
#模型间隔评估
if epoch % opt.evaluation_interval == 0:
print("\n---- Evaluating Model ----")
# Evaluate the model on the validation set
precision, recall, AP, f1, ap_class = evaluate(
model,
path=valid_path,
iou_thres=0.5,
conf_thres=0.5,
nms_thres=0.5,
img_size=opt.img_size,
batch_size=8,
)
evaluation_metrics = [
("val_precision", precision.mean()),
("val_recall", recall.mean()),
("val_mAP", AP.mean()),
("val_f1", f1.mean()),
]
logger.list_of_scalars_summary(evaluation_metrics, epoch)
# Print class APs and mAP
ap_table = [["Index", "Class name", "AP"]]
for i, c in enumerate(ap_class):
ap_table += [[c, class_names[c], "%.5f" % AP[i]]]
print(AsciiTable(ap_table).table)
print("---- mAP {AP.mean()}")
if epoch % opt.checkpoint_interval == 0:
torch.save(model.state_dict(), "checkpoints/yolov3_ckpt_%d.pth" % epoch)
test.py
from __future__ import division
from models import Darknet
from utils.utils import non_max_suppression,bbox_iou,get_batch_statistics,compute_ap,ap_per_class,load_classes,weights_init_normal,to_cpu,rescale_boxes,xywh2xyxy
from utils.datasets import ListDataset,ImageFolder,pad_to_square,resize,random_resize
from utils.parse_config import parse_data_config
import os
import sys
import time
import datetime
import argparse
import tqdm
import numpy as np
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable
import torch.optim as optim
def evaluate(model, path, iou_thres, conf_thres, nms_thres, img_size, batch_size):
model.eval()
# Get dataloader
#加载数据
dataset = ListDataset(path, img_size=img_size, augment=False, multiscale=False)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=False, num_workers=0, collate_fn=dataset.collate_fn
)
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
labels = []
sample_metrics = [] # List of tuples (TP, confs, pred)
#for batch_i, (_, imgs, targets) in enumerate(tqdm.tqdm(dataloader, desc="Detecting objects")):
for batch_i,(_, imgs, targets) in enumerate(dataloader):
#imgs : [batch_size,channels,width,height]
#targets : [index,class_id,cx,cy,w,h]
# Extract labels
labels += targets[:, 1].tolist()
# Rescale target
targets[:, 2:] = xywh2xyxy(targets[:, 2:])
targets[:, 2:] *= img_size
imgs = Variable(imgs.type(Tensor), requires_grad=False)
with torch.no_grad():
outputs = model(imgs)
outputs = non_max_suppression(outputs, conf_thres=conf_thres, nms_thres=nms_thres)
sample_metrics += get_batch_statistics(outputs, targets, iou_threshold=iou_thres)
#这里需要注意,github上面的代码有错误,需要添加if条件语句,训练才能正常运行
if len(sample_metrics) == 0:
return np.array([]),np.array([]),np.array([]),np.array([]),np.array([])
# Concatenate sample statistics
true_positives, pred_scores, pred_labels = [np.concatenate(x, 0) for x in list(zip(*sample_metrics))]
precision, recall, AP, f1, ap_class = ap_per_class(true_positives, pred_scores, pred_labels, labels)
return precision, recall, AP, f1, ap_class
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--batch_size", type=int, default=8, help="size of each image batch")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file")
parser.add_argument("--weights_path", type=str, default="weights/yolov3.weights", help="path to weights file")
parser.add_argument("--class_path", type=str, default="data/coco.names", help="path to class label file")
parser.add_argument("--iou_thres", type=float, default=0.5, help="iou threshold required to qualify as detected")
parser.add_argument("--conf_thres", type=float, default=0.001, help="object confidence threshold")
parser.add_argument("--nms_thres", type=float, default=0.5, help="iou thresshold for non-maximum suppression")
parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
opt = parser.parse_args()
print(opt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#获取数据参数
data_config = parse_data_config(opt.data_config)
#验证集的路径
valid_path = data_config["valid"]
#类别名称--类别名称文本一定要空出一行,不然读到的类别会少一类从而报错
class_names = load_classes(data_config["names"])
print('val_path = ',valid_path)
# Initiate model
#加载模型以及初始化
model = Darknet(opt.model_def).to(device)
if opt.weights_path.endswith(".weights"):
# Load darknet weights
model.load_darknet_weights(opt.weights_path)
else:
# Load checkpoint weights
model.load_state_dict(torch.load(opt.weights_path))
print("Compute mAP...")
#计算map
precision, recall, AP, f1, ap_class = evaluate(
model,
path=valid_path,
iou_thres=opt.iou_thres,
conf_thres=opt.conf_thres,
nms_thres=opt.nms_thres,
img_size=opt.img_size,
batch_size=opt.batch_size,
)
print("Average Precisions:")
for i, c in enumerate(ap_class):
print("+ Class '{c}' ({class_names[c]}) - AP: {AP[i]}")
print("mAP: {AP.mean()}")
detect.py
from __future__ import division
from models import Darknet
from utils.utils import non_max_suppression,bbox_iou,get_batch_statistics,compute_ap,ap_per_class,load_classes,weights_init_normal,to_cpu,rescale_boxes,xywh2xyxy
from utils.datasets import ListDataset,ImageFolder,pad_to_square,resize,random_resize
import os
import sys
import time
import datetime
import argparse
from PIL import Image
import numpy as np
import random
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.ticker import NullLocator
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--image_folder", type=str, default="data/samples", help="path to dataset")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--weights_path", type=str, default="weights/yolov3.weights", help="path to weights file")
parser.add_argument("--class_path", type=str, default="data/coco.names", help="path to class label file")
parser.add_argument("--conf_thres", type=float, default=0.8, help="object confidence threshold")
parser.add_argument("--nms_thres", type=float, default=0.4, help="iou thresshold for non-maximum suppression")
parser.add_argument("--batch_size", type=int, default=1, help="size of the batches")
parser.add_argument("--n_cpu", type=int, default=0, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_model", type=str, help="path to checkpoint model")
opt = parser.parse_args()
print(opt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs("output", exist_ok=True)
# Set up model
#构建网络以及初始化
model = Darknet(opt.model_def, img_size=opt.img_size).to(device)
if opt.weights_path.endswith(".weights"):
# Load darknet weights
model.load_darknet_weights(opt.weights_path)
else:
# Load checkpoint weights
model.load_state_dict(torch.load(opt.weights_path))
#设置为验证模式
model.eval() # Set in evaluation mode
#加载数据
dataloader = DataLoader(
ImageFolder(opt.image_folder, img_size=opt.img_size),
batch_size=opt.batch_size,
shuffle=False,
num_workers=opt.n_cpu,
)
classes = load_classes(opt.class_path) # Extracts class labels from file
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
imgs = [] # Stores image paths
img_detections = [] # Stores detections for each image index
print("\nPerforming object detection:")
prev_time = time.time()
#加载数据进行目标检测
for batch_i, (img_paths, input_imgs) in enumerate(dataloader):
# Configure input
input_imgs = Variable(input_imgs.type(Tensor))
# Get detections
with torch.no_grad():
detections = model(input_imgs)
detections = non_max_suppression(detections, opt.conf_thres, opt.nms_thres)
# Log progress
current_time = time.time()
inference_time = datetime.timedelta(seconds=current_time - prev_time)
prev_time = current_time
print("\t+ Batch %d, Inference Time: %s" % (batch_i, inference_time))
# Save image and detections
imgs.extend(img_paths)
img_detections.extend(detections)
# Bounding-box colors
cmap = plt.get_cmap("tab20b")
colors = [cmap(i) for i in np.linspace(0, 1, 20)]
print("\nSaving images:")
#绘制检测信息并保存图片
# Iterate through images and save plot of detections
for img_i, (path, detections) in enumerate(zip(imgs, img_detections)):
print("(%d) Image: '%s'" % (img_i, path))
# Create plot
img = np.array(Image.open(path))
plt.figure()
fig, ax = plt.subplots(1)
ax.imshow(img)
# Draw bounding boxes and labels of detections
if detections is not None:
# Rescale boxes to original image
detections = rescale_boxes(detections, opt.img_size, img.shape[:2])
unique_labels = detections[:, -1].cpu().unique()
n_cls_preds = len(unique_labels)
bbox_colors = random.sample(colors, n_cls_preds)
for x1, y1, x2, y2, conf, cls_conf, cls_pred in detections:
print("\t+ Label: %s, Conf: %.5f" % (classes[int(cls_pred)], cls_conf.item()))
box_w = x2 - x1
box_h = y2 - y1
color = bbox_colors[int(np.where(unique_labels == int(cls_pred))[0])]
# Create a Rectangle patch
bbox = patches.Rectangle((x1, y1), box_w, box_h, linewidth=2, edgecolor=color, facecolor="none")
# Add the bbox to the plot
ax.add_patch(bbox)
# Add label
plt.text(
x1,
y1,
s=classes[int(cls_pred)],
color="white",
verticalalignment="top",
bbox={"color": color, "pad": 0},
)
# Save generated image with detections
plt.axis("off")
plt.gca().xaxis.set_major_locator(NullLocator())
plt.gca().yaxis.set_major_locator(NullLocator())
filename = path.split("/")[-1].split(".")[0]
filename = filename.split('\\')[-1]
print('filename = ',filename)
plt.savefig("output/{filename}.png".format(filename = filename), bbox_inches="tight", pad_inches=0.0)
plt.close()
运行 detect.py,结果如下:
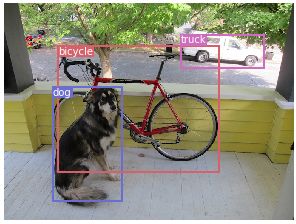







水平有限,若有不当之处,请指教,谢谢!