shardingjdbc之shardingjdbc入门
在上文中,我们讲解了分布式环境下的分库分表,从概念及案例上分析了何为分库分表及其优缺点。
我说分布式之分库分表
从本文开始我们一起学习一下如何使用当前比较成熟的分库分表框架 Sharding-JDBC 实现分库分表。
什么是Sharding-JDBC
Sharding-JDBC是分布式数据中间件Sharding-Sphere中的重要组成部分,官方的介绍如下:
Sharding-Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-JDBC 是Sharding-Sphere的第一款产品,也是最接近开发者的一款分库分表中间件,很有代表性,也值得我们深入的学习与应用。
Sharding-JDBC官方文档地址
这里我贴出官方的文档地址,版本为3.x,有问题先看文档是比较直接快速准确的trouble-shooting方式。
如何使用Sharding-JDBC3.x 实现分库分表
简单了解一下背景之后,我们用一个案例先把它用起来,直观地感受一下Sharding-JDBC的魅力,后续我们会对它做进一步的讲解。
由于目前的后端Java开发主要以Spring Boot为主,因此我将主要依据Spring Boot的2.x进行讲解。
建立数据库表
首先建立一个4库8表的数据库结构。数据库名为db_00–db_03,建立一个简单的订单表名为t_order_0000-t_order_0001,每个库中两张表
表结构比较简单,因为我们的目的是尽快的将框架用起来,太复杂的表结构容易让我们陷入业务中而偏离了我们的主旨。
订单表t_order的建表语句如下:
-- ----------------------------
-- Table structure for t_order_0000
-- ----------------------------
DROP TABLE IF EXISTS `t_order_0000`;
CREATE TABLE `t_order_0000` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) DEFAULT NULL,
`order_id` bigint(20) DEFAULT NULL,
`user_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1239 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for t_order_0001
-- ----------------------------
DROP TABLE IF EXISTS `t_order_0001`;
CREATE TABLE `t_order_0001` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) DEFAULT NULL,
`order_id` bigint(20) DEFAULT NULL,
`user_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1239 DEFAULT CHARSET=utf8;
在每个分库中均建立表t_order_0000,t_order_0001
数据库结构如下
db_00--
|--t_order_0000
|--t_order_0001
db_01--
|--t_order_0000
|--t_order_0001
db_02--
|--t_order_0000
|--t_order_0001
db_03--
|--t_order_0000
|--t_order_0001
宏观上我们就有了8个数据节点,如下:
db_00.t_order_0000, db_00.t_order_0001
db_01.t_order_0000, db_01.t_order_0001
db_02.t_order_0000, db_02.t_order_0001
db_03.t_order_0000, db_03.t_order_0001
建立demo工程
这里直接使用IDEA的spring-boot-initializer建立了一个demo工程,工程名为snowalker-shardingjdbc-demo,文章末尾会放上demo工程的github地址。
工程的结构如下:
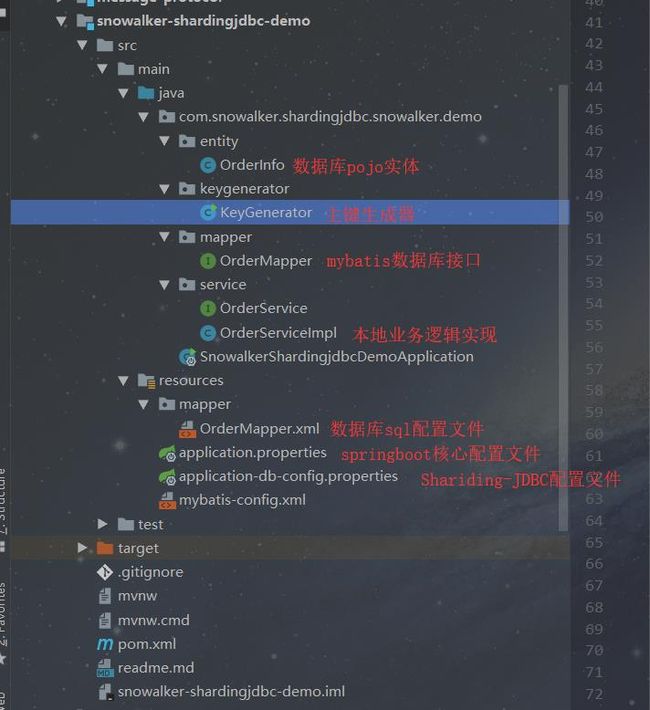 project.png
project.png
引入sharding-jdbc-spring-boot-starter依赖如下
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.0.0
数据库访问组件使用mybatis,这里直接使用了mybatis-spring-boot-starter
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.2
完整的pom.xml内容如下
4.0.0
com.snowalker.shardingjdbc
snowalker-shardingjdbc-demo
0.0.1-SNAPSHOT
snowalker-shardingjdbc-demo
Demo project for Spring Boot
1.8
1.8
1.8
UTF-8
UTF-8
1.3.2
1.1.6
3.0.0
1.14
1.2.28
3.8
org.springframework.boot
spring-boot-starter-web
io.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-jdbc-version}
mysql
mysql-connector-java
org.mybatis.spring.boot
mybatis-spring-boot-starter
${mybatis-spring-boot-starter-version}
com.alibaba
druid
${druid-version}
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
配置mybatis
接着我们在application.properties中配置mybatis,指定mapper配置文件的位置
########################################################################
#
# mybatis配置
#
#########################################################################
mybatis.config-location=classpath:mybatis-config.xml
mybatis.mapper-locations=classpath:mapper/*.xml
这里我在resources下建立一个目录mapper,将mapper配置文件均放置在该目录下。
配置基本分库分表规则
由于我们使用了Spring Boot作为基础框架,因此只需要通过groovy表达式的方式进行分库分表规则的配置。
引入分库分表配置文件
这里在resources下建立一个application-db-config.properties配置,用于配置分库分表相关的配置项。 注意 一定要以application- 开头,否则不能正常的引入。
在application.properties中添加如下配置,引入分库分表的配置项
spring.profiles.include=db-config
application-db-config.properties分库分表配置项详解
这里使用druid作为数据库的连接池,我们需要在 application-db-config.properties 中配置数据源及分库分表的规则等信息。
数据源分片详细配置
###########################################################
#
# 数据源分片详细配置
#
###########################################################
#打印sql日志
sharding.jdbc.config.sharding.props.sql.show=true
#数据源名称,多数据源以逗号分隔
sharding.jdbc.datasource.names=ds0,ds1,ds2,ds3
###########################################################
#
# 数据源参数配置-druid
#
###########################################################
initialSize=5
minIdle=5
maxIdle=100
maxActive=20
maxWait=60000
timeBetweenEvictionRunsMillis=60000
minEvictableIdleTimeMillis=300000
这里主要配置了分片数据源及公共的数据源配置参数,我们通过sharding.jdbc.datasource.names 指定了ds0,ds1,ds2,ds3四个物理分片数据源
默认分片规则配置
一般在线上业务中,会有配置信息表,比如: 省市区编码字典表,错误码字典表 等类型的不需要进行分库分表的数据表,那么我们就可以将他们放置在默认的分片中,这样,当我们的sql执行对这些表的操作,Sharding-JDBC的sql解析器解析这些sql时会路由到默认的数据源进行对应的操作。
###########################################################
#
# 默认分片规则配置--字典表使用
#
###########################################################
#未配置分片规则的表将通过默认数据源定位-适用于单库单表,该表无需配置分片规则
sharding.jdbc.config.sharding.defaultDataSourceName=ds0
通过 sharding.jdbc.config.sharding.defaultDataSourceName 指定我们在上文中配置的分片中的某一个数据源别名作为默认数据源
数据源详细配置
这里是对上述四个数据源的详细配置,篇幅可能较长,我先以一个详细的配置进行讲解
###########################################################
#
# 数据源详细配置
#
###########################################################
#################### 00库配置 ##############################
sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:3306/db_00?useUnicode=true&characterEncoding=utf8
&useSSL=true&serverTimezone=GMT%2B8
sharding.jdbc.datasource.ds0.username=xxxxxxx
sharding.jdbc.datasource.ds0.password=xxxxxxx
# 连接池的配置信息
# 初始化大小,最小,最大
sharding.jdbc.datasource.ds0.initialSize=${initialSize}
# 只需配置minIdle最小连接池数量,maxIdle已经不再使用,配置了也没效果
sharding.jdbc.datasource.ds0.minIdle=${minIdle}
# 最大连接池数量
sharding.jdbc.datasource.ds0.maxActive=${maxActive}
# 配置获取连接等待超时的时间
sharding.jdbc.datasource.ds0.maxWait=${maxWait}
# 用来检测连接是否有效的sql
sharding.jdbc.datasource.ds0.validationQuery=SELECT 1 FROM DUAL
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
sharding.jdbc.datasource.ds0.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
# 配置一个连接在池中最小生存的时间,单位是毫秒
sharding.jdbc.datasource.ds0.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
由于使用了Sharding-JDBC,因此我们需要使用它的数据源配置,配置数据源为druid,配置数据库连接地址及用户名密码。
注意:
- 由于我们使用的Spring Boot2.x默认使用的mysql驱动为8.x,因此将驱动设置为: com.mysql.cj.jdbc.Driver
- 数据库连接串中需要显式的指定当前的时区,这里我们使用东八区,即 serverTimezone=GMT%2B8
- 生产环境数据库的密码应当使用加密方式,这块儿的详细配置我会在下一篇文章中展开详述
关于mysql驱动及时区,可以看我之前写的文章
com.mysql.jdbc.Driver 和 com.mysql.cj.jdbc.Driver的区别 serverTimezone设定
其余的数据源分片的配置是类似的,嫌太长的读者可以直接跳过。
#################### 01库配置 ##############################
sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:3306/db_01?useUnicode=true&characterEncoding=utf8&useSSL=true
&serverTimezone=GMT%2B8
sharding.jdbc.datasource.ds1.username=xxxxxxx
sharding.jdbc.datasource.ds1.password=xxxxxxx
# 连接池的配置信息
# 初始化大小,最小,最大
sharding.jdbc.datasource.ds1.initialSize=${initialSize}
# 只需配置minIdle最小连接池数量,maxIdle已经不再使用,配置了也没效果
sharding.jdbc.datasource.ds1.minIdle=${minIdle}
# 最大连接池数量
sharding.jdbc.datasource.ds1.maxActive=${maxActive}
# 配置获取连接等待超时的时间
sharding.jdbc.datasource.ds1.maxWait=${maxWait}
# 用来检测连接是否有效的sql
sharding.jdbc.datasource.ds1.validationQuery=SELECT 1 FROM DUAL
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
sharding.jdbc.datasource.ds1.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
# 配置一个连接在池中最小生存的时间,单位是毫秒
sharding.jdbc.datasource.ds1.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
#################### 02库配置 ##############################
sharding.jdbc.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.ds2.url=jdbc:mysql://127.0.0.1:3306/db_02?useUnicode=true&characterEncoding=utf8&useSSL=true
&serverTimezone=GMT%2B8
sharding.jdbc.datasource.ds2.username=xxxxxxx
sharding.jdbc.datasource.ds2.password=xxxxxxx
# 连接池的配置信息
# 初始化大小,最小,最大
sharding.jdbc.datasource.ds2.initialSize=${initialSize}
# 只需配置minIdle最小连接池数量,maxIdle已经不再使用,配置了也没效果
sharding.jdbc.datasource.ds2.minIdle=${minIdle}
# 最大连接池数量
sharding.jdbc.datasource.ds2.maxActive=${maxActive}
# 配置获取连接等待超时的时间
sharding.jdbc.datasource.ds2.maxWait=${maxWait}
# 用来检测连接是否有效的sql
sharding.jdbc.datasource.ds2.validationQuery=SELECT 1 FROM DUAL
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
sharding.jdbc.datasource.ds2.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
# 配置一个连接在池中最小生存的时间,单位是毫秒
sharding.jdbc.datasource.ds2.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
#################### 03库配置 ##############################
sharding.jdbc.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds3.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.ds3.url=jdbc:mysql://127.0.0.1:3306/db_03?useUnicode=true&characterEncoding=utf8&useSSL=true
&serverTimezone=GMT%2B8
sharding.jdbc.datasource.ds3.username=xxxxxxx
sharding.jdbc.datasource.ds3.password=xxxxxxx
# 连接池的配置信息
# 初始化大小,最小,最大
sharding.jdbc.datasource.ds3.initialSize=${initialSize}
# 只需配置minIdle最小连接池数量,maxIdle已经不再使用,配置了也没效果
sharding.jdbc.datasource.ds3.minIdle=${minIdle}
# 最大连接池数量
sharding.jdbc.datasource.ds3.maxActive=${maxActive}
# 配置获取连接等待超时的时间
sharding.jdbc.datasource.ds3.maxWait=${maxWait}
# 用来检测连接是否有效的sql
sharding.jdbc.datasource.ds3.validationQuery=SELECT 1 FROM DUAL
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
sharding.jdbc.datasource.ds3.timeBetweenEvictionRunsMillis=${timeBetweenEvictionRunsMillis}
# 配置一个连接在池中最小生存的时间,单位是毫秒
sharding.jdbc.datasource.ds3.minEvictableIdleTimeMillis=${minEvictableIdleTimeMillis}
配置数据库表分片规则
接下来讲解的数据库表分片规则是配置的重点,本文中我们使用默认的inline表达式作为讲解重点。
实战中,单纯使用inline表达式可能不满足我们的需求,这就需要我们对分片规则进行扩展,这块儿的内容会在系列的后半部分展开讲解。
首先看一下我们的配置详细内容
###########################################################
#
# shardingjdbc--分片规则--订单表
# 根据user_id取模分库, 且根据order_id取模分表的两库两表的配置。
#
###########################################################
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column
=user_id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression
=ds$->{user_id % 4}
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes
=ds$->{0..3}.t_order_000$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column
=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression
=t_order_000$->{order_id % 2}
订单表中保存了系统内部用户id,订单表主键order_id。实际的场景中,我们需要查询某一个用户的订单列表,因此需要将user_id作为查询条件,这里相信聪明的你已经猜到,需要将user_id作为数据库的分片键。
我们详细的看一下各个配置的含义
| 配置项 | 解释 |
|---|---|
| sharding.jdbc.config.sharding. default-database-strategy.inline.sharding-column |
表示默认的分片列名称,我们用user_id作为分片列 |
| sharding.jdbc.config.sharding. default-database-strategy.inline.algorithm-expression |
表示inline表达式指定的分片策略,这里我们配置 ds$->{user_id % 4} 表示 对user_id进行模4操作,余数即为路由后的数据分片下标,这里要保证user_id为纯数字,需要我们自行实现一个唯一id生成器,这里我是自己实现一个简单的demo级别的KeyGenerator。关于如何实现生产可用的唯一id生成器,我也会在后续的文章中通过一个单独的专题进行讲解。 |
| sharding.jdbc.config.sharding. tables.t_order.actual-data-nodes |
这个配置是需要我们通过inline表达式指定所有的实际数据分片节点。其中,tables后需要指定逻辑数据表名,我们指定为t_order。 这里我们配置的是ds$->{0..3}.t_order_000$->{0..1},通过groovy的遍历语法将配置的四个数据分片中的所有表指定为实际的数据节点。(这里的$符号一定是英文半角) |
| sharding.jdbc.config.sharding. tables.t_order.table-strategy.inline.sharding-column |
该配置表示表分片键,这里我们使用订单表的业务主键order_id作为表分片键,这样可以保证同一个用户的订单数据在同一个数据库分片中,但是不能保证在同一个数据表中。 |
| sharding.jdbc.config.sharding. tables.t_order.table-strategy.inline.algorithm-expression |
该配置为表分片策略的inline表达式,此处我们要对每个片上的所有订单表进行模2操作(2表示每个片有两个表节点),因此配置为t_order_000$->{order_id % 2} |
到这里,我们就通过默认的inline表达式方式将分片的配置设置完毕。接着看下代码逻辑
代码逻辑实现
先简单看下订单实体属性,很简单,就是对数据库表字段的映射
订单实体
public class OrderInfo {
private String id;
private Long userId;
private Long orderId;
private String userName;
...省略getter setter...
OrderMapper订单数据库操作接口
Sharding-JDBC对我们使用何种数据库查询框架没有限制,可以是原生的JDBC,也可以是JDBCTemplate,或者mybatis均可。这体现出它设计上的高度抽象性。
public interface OrderMapper {
// 查询某个用户订单列表
List queryOrderInfoList(OrderInfo orderInfo);
// 通过订单号查询订单信息
OrderInfo queryOrderInfoByOrderId(OrderInfo orderInfo);
// 插入订单信息
int addOrder(OrderInfo orderInfo);
}
很简单,就是一个插入操作,一个列表查询,一个通过主键查询,我们用来测试配置项是否生效。
OrderServiceImpl订单操作业务实现类
这里主要展示的是订单操作业务实现类,接口内容不再赘述
@Service(value = "orderService")
public class OrderServiceImpl implements OrderService {
private static final Logger LOGGER = LoggerFactory.getLogger(OrderServiceImpl.class);
@Autowired
OrderMapper orderMapper;
@Override
public List queryOrderInfoList(OrderInfo orderInfo) {
return orderMapper.queryOrderInfoList(orderInfo);
}
@Override
public OrderInfo queryOrderInfoByOrderId(OrderInfo orderInfo) {
return orderMapper.queryOrderInfoByOrderId(orderInfo);
}
@Override
public int addOrder(OrderInfo orderInfo) {
LOGGER.info("订单入库开始,orderinfo={}", orderInfo.toString());
return orderMapper.addOrder(orderInfo);
}
}
代码几乎没有什么理解难度,就是直接代理Mapper,将上层的参数直接传递给数据持久层。
测试用例
这里通过一个测试用例测试上述的三个数据库操作是否能够正确执行。
测试数据插入
@RunWith(SpringRunner.class)
@SpringBootTest
public class SnowalkerShardingjdbcDemoApplicationTests {
private static final Logger LOGGER = LoggerFactory.getLogger(SnowalkerShardingjdbcDemoApplicationTests.class);
@Resource(name = "orderService")
OrderService orderService;
@Test
public void testInsertOrderInfo() {
for (int i = 0; i < 1000; i++) {
long userId = i;
long orderId = i + 1;
OrderInfo orderInfo = new OrderInfo();
orderInfo.setUserName("snowalker");
orderInfo.setUserId(userId);
orderInfo.setOrderId(orderId);
int result = orderService.addOrder(orderInfo);
if (1 == result) {
LOGGER.info("入库成功,orderInfo={}", orderInfo);
} else {
LOGGER.info("入库失败,orderInfo={}", orderInfo);
}
}
}
.....
这里我们进行1000次入库操作,将每次的循环次数作为user_id,循环次数+1作为订单id,后续的文章中我会讲解如何自定义生产可用的主键生成策略。
将数据填充到POJO中后执行入库操作。
日志如下:
2019-03-13 16:19:34.361 INFO 16388 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
2019-03-13 16:19:34.450 INFO 16388 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-2} inited
2019-03-13 16:19:34.518 INFO 16388 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-3} inited
2019-03-13 16:19:34.582 INFO 16388 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-4} inited
2019-03-13 16:19:35.888 INFO 16388 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2019-03-13 16:19:37.103 INFO 16388 --- [ main] nowalkerShardingjdbcDemoApplicationTests : Started SnowalkerShardingjdbcDemoApplicationTests in 6.993 seconds (JVM running for 8.214)
2019-03-13 16:19:37.529 INFO 16388 --- [ main] c.s.s.s.demo.service.OrderServiceImpl : 订单入库开始,orderinfo=OrderInfo{id='null', userId=0, orderId=1, userName='snowalker'}
2019-03-13 16:19
......
2019-03-13 16:19:38.456 INFO 16388 --- [ main] nowalkerShardingjdbcDemoApplicationTests : 入库成功,orderInfo=OrderInfo{id='null', userId=0, orderId=1, userName='snowalker'}
2019-03-13 16:19:38.456 INFO 16388 --- [ main] c.s.s.s.demo.service.OrderServiceImpl : 订单入库开始,orderinfo=OrderInfo{id='null', userId=4, orderId=5, userName='snowalker'}
2019-03-13 16:19:38.457 INFO 16388 --- [ main] Sharding-Sphere-SQL : Rule Type: sharding
2019-03-13 16:19:38.457 INFO 16388 --- [ main] Sharding-Sphere-SQL : Logic SQL: insert into t_order(
user_id,
order_id,
user_name
)
values
(
?,
?,
?
)
2019-03-13 16:19:38.457 INFO 16388 --- [ main] Sharding-Sphere-SQL : SQLStatement: InsertStatement(super=DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[Table(name=t_order, alias=Optional.absent())]), conditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[Condition(column=Column(name=user_id, tableName=t_order), operator=EQUAL, positionValueMap={}, positionIndexMap={0=0}), Condition(column=Column(name=order_id, tableName=t_order), operator=EQUAL, positionValueMap={}, positionIndexMap={0=1})])])), sqlTokens=[TableToken(skippedSchemaNameLength=0, originalLiterals=t_order), io.shardingsphere.core.parsing.parser.token.InsertValuesToken@79be91eb], parametersIndex=3)), columns=[Column(name=user_id, tableName=t_order), Column(name=order_id, tableName=t_order), Column(name=user_name, tableName=t_order)], generatedKeyConditions=[], insertValues=InsertValues(insertValues=[InsertValue(type=VALUES, expression=(
?,
?,
?
), parametersCount=3)]), columnsListLastPosition=83, generateKeyColumnIndex=-1, insertValuesListLastPosition=142)
2019-03-13 16:19:38.457 INFO 16388 --- [ main] Sharding-Sphere-SQL : Actual SQL: ds0 ::: insert into t_order_0001(
user_id,
order_id,
user_name
)
values
(
?,
?,
?
) ::: [[4, 5, snowalker]]
可以看到,Sharding-JDBC帮助我们将逻辑sql及实际执行的sql均打印出来,这个配置在开发阶段能够帮助我们更快的定位数据的分布情况,生产环境设置为 sharding.jdbc.config.sharding.props.sql.show=false 关闭。
查看数据库,看到的效果如下:
首先找库,
user_id mod 4 == 0 入 db_00,user_id mod 4 == 1 入 db_01
user_id mod 4 == 2 入 db_02,user_id mod 4 == 3 入 db_03
接着找表
order_id mod 2 == 0 入 t_order_0000
order_id mod 2 == 1 入 t_order_0001
二者结合起来一共有八种组合
user_id mod 4 == 0 入 db_00, order_id mod 2 == 0 入 t_order_0000
user_id mod 4 == 0 入 db_00, order_id mod 2 == 1 入 t_order_0001
user_id mod 4 == 1 入 db_01, order_id mod 2 == 0 入 t_order_0000
user_id mod 4 == 1 入 db_01, order_id mod 2 == 1 入 t_order_0001
user_id mod 4 == 2 入 db_02, order_id mod 2 == 0 入 t_order_0000
user_id mod 4 == 2 入 db_02, order_id mod 2 == 1 入 t_order_0001
user_id mod 4 == 3 入 db_03, order_id mod 2 == 0 入 t_order_0000
user_id mod 4 == 3 入 db_03, order_id mod 2 == 1 入 t_order_0001
这样,至少能够保证同一个用户的数据都在一个物理分片上。
测试查询列表
列表查询测试用例很简单,代码如下:
/**
* 默认规则跨片归并
*/
@Test
public void testQueryList() {
List list = new ArrayList<>();
OrderInfo orderInfo = new OrderInfo();
orderInfo.setUserId(2l);
list = orderService.queryOrderInfoList(orderInfo);
LOGGER.info(list.toString());
}
这里我们查询一个user_id=21的用户的所有订单明细列表,21 mod 4 == 1, 该用户的所有数据分布在 db_01 片上,在该片上查询其所有的订单数据。
由于我们制定的默认分片策略是通过order_id mod 2,因此一定存在用户订单为奇数的分布在t_order_0001中,订单为偶数的分布在t_order_0000中。
这里就涉及到Sharding-JDBC的一个特性:结果归并。
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
归并方式分为如下几种方式:
| 归并方式 |
|---|
| 遍历归并 |
| 排序归并 |
| 分组归并 |
| 聚合归并 |
| 分页归并 |
对归并的详细的介绍,请查看官网的讲解 归并引擎
这里我使用的是未排序的列表查询,sql语句如下:
没有指定order by 字段,因此使用最简单的遍历归并。Sharding-JDBC的归并引擎会结合具体的查询sql进行分析,选取最合适的归并方式,这对我们应用层都是无感知的。
执行一下这个测试用例,日志打印如下:
2019-03-13 17:23:06.928 INFO 16028 --- [ main] nowalkerShardingjdbcDemoApplicationTests : Started SnowalkerShardingjdbcDemoApplicationTests in 6.076 seconds (JVM running for 7.079)
2019-03-13 17:23:07.595 INFO 16028 --- [ main] Sharding-Sphere-SQL : Rule Type: sharding
2019-03-13 17:23:07.596 INFO 16028 --- [ main] Sharding-Sphere-SQL :
Logic SQL: select
t.id as id,
t.user_id as userId,
t.order_id as orderId,
t.user_name as userName
from t_order t
where t.user_id=?
2019-03-13 17:23:07.596 INFO 16028 --- [ main] Sharding-Sphere-SQL : SQLStatement: SelectStatement(super=DQLStatement(super=AbstractSQLStatement(type=DQL, tables=Tables(tables=[Table(name=t_order, alias=Optional.of(t))]), conditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[Condition(column=Column(name=user_id, tableName=t_order), operator=EQUAL, positionValueMap={}, positionIndexMap={0=0})])])), sqlTokens=[TableToken(skippedSchemaNameLength=0, originalLiterals=t_order)], parametersIndex=1)), containStar=false, selectListLastPosition=143, groupByLastPosition=0, items=[CommonSelectItem(expression=t.user_name, alias=Optional.of(userName)), CommonSelectItem(expression=t.id, alias=Optional.of(id)), CommonSelectItem(expression=t.user_id, alias=Optional.of(userId)), CommonSelectItem(expression=t.order_id, alias=Optional.of(orderId))], groupByItems=[], orderByItems=[], limit=null, subQueryStatement=null)
2019-03-13 17:23:07.596 INFO 16028 --- [ main] Sharding-Sphere-SQL :
Actual SQL: ds2 ::: select
t.id as id,
t.user_id as userId,
t.order_id as orderId,
t.user_name as userName
from t_order_0000 t
where t.user_id=? ::: [[2]]
2019-03-13 17:23:07.596 INFO 16028 --- [ main] Sharding-Sphere-SQL :
Actual SQL: ds2 ::: select
t.id as id,
t.user_id as userId,
t.order_id as orderId,
t.user_name as userName
from t_order_0001 t
where t.user_id=? ::: [[2]]
2019-03-13 17:23:08.200 INFO 16028 --- [ main] nowalkerShardingjdbcDemoApplicationTests :
[OrderInfo{id='975', userId=2, orderId=2, userName='snowalker'},
OrderInfo{id='1', userId=2, orderId=3, userName='snowalker'}]
通过日志可以看出,逻辑sql被sql解析器解析后改写为两个实际的sql,在ds2的t_order_0000与t_order_0001上均执行了一次,查询的结果在应用层进行了归并。
这种结果归并的方式由于涉及到了跨片查询,应用层的合并,因此有性能的损耗,而且由于数据跨片,因此可能导致事务失效。这个问题也是有解决方法的,我们可以通过自定义主键生成策略,强制同一个用户的所有的业务数据分布在同一个片(数据源)的同一个节点(表)上。详细方式我会在后续文章中展开讲解。
测试查询单条数据
查询单条数据就很简单了,在sql中指定了user_id和order_id两个分片键,首先通过user_id
找到数据源,再通过order_id查找节点找到对应表,最后在确定的数据源的某个确定的数据表上执行sql将数据查询后返回即可。
测试用例代码如下:
@Test
public void testQueryById() {
OrderInfo queryParam = new OrderInfo();
queryParam.setUserId(8l);
queryParam.setOrderId(8l);
OrderInfo queryResult = orderService.queryOrderInfoByOrderId(queryParam);
if (queryResult != null) {
LOGGER.info("查询结果:orderInfo={}", queryResult);
} else {
LOGGER.info("查无此记录");
}
}
我们尝试查找user_id为8,order_id为8的订单记录,执行后查看日志如下:
2019-03-13 17:34:42.975 INFO 15760 --- [ main] Sharding-Sphere-SQL : Rule Type: sharding
2019-03-13 17:34:42.975 INFO 15760 --- [ main] Sharding-Sphere-SQL : Logic SQL: select
t.id as id,
t.user_id as userId,
t.order_id as orderId,
t.user_name as userName
from t_order t
where t.order_id=?
and t.user_id=?
2019-03-13 17:34:42.975 INFO 15760 --- [ main] Sharding-Sphere-SQL : SQLStatement: SelectStatement(super=DQLStatement(super=AbstractSQLStatement(type=DQL, tables=Tables(tables=[Table(name=t_order, alias=Optional.of(t))]), conditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[Condition(column=Column(name=order_id, tableName=t_order), operator=EQUAL, positionValueMap={}, positionIndexMap={0=0}), Condition(column=Column(name=user_id, tableName=t_order), operator=EQUAL, positionValueMap={}, positionIndexMap={0=1})])])), sqlTokens=[TableToken(skippedSchemaNameLength=0, originalLiterals=t_order)], parametersIndex=2)), containStar=false, selectListLastPosition=143, groupByLastPosition=0, items=[CommonSelectItem(expression=t.user_name, alias=Optional.of(userName)), CommonSelectItem(expression=t.id, alias=Optional.of(id)), CommonSelectItem(expression=t.user_id, alias=Optional.of(userId)), CommonSelectItem(expression=t.order_id, alias=Optional.of(orderId))], groupByItems=[], orderByItems=[], limit=null, subQueryStatement=null)
2019-03-13 17:34:42.975 INFO 15760 --- [ main] Sharding-Sphere-SQL :
Actual SQL: ds0 ::: select
t.id as id,
t.user_id as userId,
t.order_id as orderId,
t.user_name as userName
from t_order_0000 t
where t.order_id=?
and t.user_id=? ::: [[8, 8]]
2019-03-13 17:34:43.467 INFO 15760 --- [ main] nowalkerShardingjdbcDemoApplicationTests :
查询结果:orderInfo=OrderInfo{id='991', userId=8, orderId=8, userName='snowalker'}
sql解析器查找到该数据分布在0库0表中,执行查询语句并将结果返回。
遗留问题
- 后续需要实现自定义分片策略,配合自定义唯一主键的生成,保证同一个用户的数据分布在同一个片的同一个节点上
- 需要实现自定义唯一主键的编写,实现字符串形式的主键生成策略。这样我们就可以定义主键的不同位数的含义,将业务属性代入其中。如: OD0120180313194640123000802000923,表示order表的主键,包含了时间戳(精确到毫秒),包含了库表的下标。这样可读性更好,支持不同业务场景对主键生成的需求。
- 通过上述1.2两点,能够明显的规避由于数据分布在不同片上,导致的归并查询,这样,单库事务就又可以使用了,尽可能的减少分布式事务的引入。(分布式事务能避免就避免),当然我们在后续的讲解中也可能会对Sharding-Sphere原生的Saga事务做讲解。
小结
到这里,我们就完成了对Sharding-JDBC 3.x与Spring Boot 2.x的整合,配置了默认分片策略,完成了一个单表的主键查询、新增、列表查询等的操作。过程中对关键的配置和名词进行了解析,相信会对读者有所帮助。
工程地址,本系列中保持更新
snowalker-shardingjdbc-demo