- 代码练习
- 1.1 HybridSN模型的思考
- 1.2 HybridSN的SENet改进
- 视频学习
- 2.1 语义分割中的自注意力机制和低秩重重建
- 2.1.1 Fully Convolutional Networks for Semantic Segmentation
- 2.1.2 Rethinking Atrous Convolution for Semantic Image Segmentation
- 2.1.3 Non-local Neural Networks
- 2.2 图像语义分割前沿进展
- 2.2.1 Res2Net
- 2.2.2 Strip Pooling
- 2.1 语义分割中的自注意力机制和低秩重重建
- 论文阅读
- 3.1 Selective Kernel Networks
- 3.2 Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
- 3.3 HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation
-
代码练习
-
1.1 HybridSN模型的思考
-
对之前的HybridSN模型,在训练过后,多次进行测试,会发现每一次测试的准确率都不一致,之前测试的代码如下
count = 0 # 模型测试 for inputs, _ in test_loader: inputs = inputs.to(device) outputs = net(inputs) outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1) if count == 0: y_pred_test = outputs count = 1 else: y_pred_test = np.concatenate( (y_pred_test, outputs) ) # 生成分类报告 classification = classification_report(ytest, y_pred_test, digits=4) print(classification)测试结果的不确定性是由于dropout层引起的,该层用于减少过拟合现象,通常加在全连接层之后。对于dropout和batch normalization,在测试之前要使用
net.eval()来将他们固定住,否则就算不进行训练,也会更改参数。
更改后的代码如下
count = 0 # 模型测试 for inputs, _ in test_loader: net.eval() inputs = inputs.to(device) outputs = net(inputs) outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1) if count == 0: y_pred_test = outputs count = 1 else: y_pred_test = np.concatenate( (y_pred_test, outputs) )
-
-
1.2 HybridSN的SENet改进
-
SENet全称Squeeze-and-Excitation Networks,是对不同通道的输入分配不同权重的一种机制,为的是根据输入来重视某些通道,忽视某些通道。其网络整体结构为

首先对输入 \(X_{W^{'} \times H^{'} \times C^{'}}\) 进行卷积 \(\bold{F}_{tr}\) ,该卷积定义为
\[\bold{u}_c=\bold{v}_c*\bold{X}=\sum_{s=1}^{C^{'}}\bold{v}_c^s*\bold{x}^s \]其中,\(U=[\bold{u}_1,\bold{u}_2,...,\bold{u}_c]\) ,\(V=[\bold{v}_1,\bold{v}_2,...,\bold{v}_c]\)为卷积核,经过该常规卷积将 \(X_{W^{'} \times H^{'} \times C^{'}}\) 变换为 \(U_{W \times H \times C}\),而后进行 \(\bold{F}_{sq}\) 操作(即Squeeze操作),具体的做法是使用全剧平均池化对输入 \(U\) 进行缩小,该操作定义为
\[z_c=\bold{F}_{sq}(\bold{u}_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j) \]也就是对每个通道的二维图像 \(\bold{u}_{H\times W}\) 进行平均,之后得到一个 \(1\times 1\times C\) 的输出,而后,使用(excitation操作)
\[s=\bold{F}_{ex}(\bold{z},\bold{W})=\sigma(g(\bold{z},\bold{W}))=\sigma(\bold{W}_2\delta(\bold{W}_1\bold{z})) \]得到注意力权值,其中 \(\sigma\) 为sigmoid函数,\(\bold{W_1} \in \mathbb{R}^{\frac{C}{r}\times C}\) ,\(\bold{W_2} \in \mathbb{R}^{C\times \frac{C}{r}}\) ,这两个矩阵变换的引入是为了降低参数量,最后
\[\widetilde{x}_c=\bold{F}_{scale}(\bold{u}_c,s_c)=s_c\bold{u}_c \]即对最开始卷积后的结果进行倍乘即可
以上是SENet模型的基本模型,其引入了注意力机制,可以看到,将SENet基本思想添加到已有模型中是可行的
更改后的HybridSN如下
class HybridSN(nn.Module): def __init__(self, classes=16): super(HybridSN,self).__init__() self.conv3d1 = nn.Conv3d(1,8,(7,3,3)) self.conv3d2 = nn.Conv3d(8,16,(5,3,3)) self.conv3d3 = nn.Conv3d(16,32,(3,3,3)) self.conv2d1 = nn.Conv2d(576,64,(3,3)) self.relu = nn.ReLU() self.dense1 = nn.Linear(18496,256) self.dense2 = nn.Linear(256,128) self.drop = nn.Dropout(p=0.4) self.fc = nn.Linear(128,classes) self.softmax = nn.Softmax(dim=1) #se操作 self.gap = nn.AdaptiveAvgPool2d(1) # 全局平均池化 sq操作 self.SEfc = nn.Sequential( # 两个全连接层,ex操作 nn.Linear(64, 64//16, bias=False), # 从 c -> c/r nn.ReLU(inplace=True), nn.Linear(64//16, 64, bias=False), # 从 c/r -> c nn.Sigmoid() ) def forward(self,x): x = self.conv3d1(x) x = self.relu(x) x = self.conv3d2(x) x = self.relu(x) x = self.conv3d3(x) x = self.relu(x) b,c,d,h,w = x.size() x = x.view(b,c*d,h,w) x = self.conv2d1(x) x = self.relu(x) b, c, h, w = x.size() y = self.gap(x).view(b,c) # sq y = self.SEfc(y).view(b,c,1,1) # ex x = x*y x = x.reshape(b,-1) x = self.dense1(x) x = self.drop(x) x = self.dense2(x) x = self.drop(x) x = self.fc(x) return x加入SE结构(lr=0.001,both batchsize=128)
precision recall f1-score support 0.0 0.9500 0.9268 0.9383 41 1.0 0.9808 0.9518 0.9660 1285 2.0 0.9867 0.9960 0.9913 747 3.0 0.9726 1.0000 0.9861 213 4.0 0.9977 1.0000 0.9989 435 5.0 0.9909 0.9909 0.9909 657 6.0 1.0000 1.0000 1.0000 25 7.0 0.9885 1.0000 0.9942 430 8.0 0.9444 0.9444 0.9444 18 9.0 0.9853 0.9977 0.9915 875 10.0 0.9789 0.9864 0.9826 2210 11.0 0.9774 0.9719 0.9746 534 12.0 1.0000 1.0000 1.0000 185 13.0 0.9939 0.9965 0.9952 1139 14.0 0.9971 0.9971 0.9971 347 15.0 0.9737 0.8810 0.9250 84 accuracy 0.9851 9225 macro avg 0.9824 0.9775 0.9798 9225 weighted avg 0.9851 0.9851 0.9851 9225
-
-
-
视频学习
-
2.1 语义分割中的自注意力机制和低秩重重建
-
该视频讲解稍显简略,完全理解需要研究所给论文,但由于所给论文过多,只做了部分工作。
-
语义分割就是对输入的图像进行分割,使得不同物体属于不同的类别,具体做法是,对于输入 \(\bold{X}_{H\times W\times C}\),输出一个矩阵
\(\bold{Y}_{H\times W\times C^{'}}, \bold{Y}_{i,j,k}\in[0,1]\) ,其中其中 \(C\) 为图中物体的个数,也就是类别标记
-
2.1.1 Fully Convolutional Networks for Semantic Segmentation
-
该论文采用了FCN(fully convolutional networks)来进行语义分割,这样做的主要原因是传统的网络最后往往会产生一个 \(1\times 1\) 的特征图,这不利于语义分割,所以将全部的网络层次都转化为卷积层,也就是将最后几层 \(1\times 1\) 的层也改变为卷积层,即

-
使用了上采样处理(或者反卷积deconvolution),重叠处使用相加进行处理

-
多层叠加结构,即使用不同层的池化结果优化最后的池化输出,在后面的池化结果进行上采样的同时和前面的池化结果融合

-
-
2.1.2 Rethinking Atrous Convolution for Semantic Image Segmentation
-
Atrous Convolution为一种提高感受野的方法,可以在算力有限时增加感受野的大小,便于图像分割,即

其中rate表示两个方块距离的大小(例如123,1到3的距离为2)
-
Atrous Convolution的定义为
\[\boldsymbol{y}[\boldsymbol{i}]=\sum_\boldsymbol{k}\boldsymbol{x}[\boldsymbol{i}+r\ ·\ \boldsymbol{k}]\boldsymbol{w}[\boldsymbol{k}] \]其中 \(\boldsymbol{y}[\boldsymbol{i}]\) 为输出中指标为 \(\boldsymbol{i}\) 对应的元素(注意 \(\boldsymbol{i}\) 为向量,在二维中代表 \((x,y)\)
\(\boldsymbol{x}\) 为输入,\(r\) 为rate,\(\boldsymbol{k}\) 也是一个向量,以上图为例,分别代表\((-1,-1),(-1,0),(-1,1),...,(1,-1),(1,0),(1,1)\) 9个元组(若核为3×3)
-
以串行方式连接Atrous Convolution

以并行连接

-
-
2.1.3 Non-local Neural Networks
典型的工作还有Nonlocal Neural Networks,主要思想是建立各个点之间的关系,使用如下公式进行度量下公式进行度量
\[\bold{y}_i=\frac{1}{\mathcal{C(\bold{x})}}\sum_{\forall j}f(\bold{x}_i,\bold{x}_j)g(\bold{x}_j) \]其中f用以度量两点之间的相似度,g用以做变换
nonlocal networks与卷积层和fc层不同,它考虑到了全部点与当前点的关联,相比之下,卷积层只考虑核大小有关的范围,而fc层则是不考虑任意两点之间的关联,仅是由所有的输入点产生输出
在实验过程中可以看到f,g两个函数的选定对结果影响不大,所以是nonlocal这个行为造成了对结果性能的提升
可以考虑多种f,g函数的策略,在运用中,论文中对g只考虑了线性的情况,即
\[g(\bold{x}_j)=\bold{W}_g\bold{x}_j \]其中g往往使用1×1或者1×1×1的卷积核
第一种策略,可以考虑Gaussian策略
\[f(\bold{x}_i,\bold{x}_j)=e^{\bold{x}_i^T\bold{x}_j} \\ \mathcal C(\bold{x})=\sum_{\forall j}f(\bold{x}_i,\bold{x}_j) \]第二种策略,可以考虑embedded gaussian
\[f(\bold{x}_i,\bold{x}_j)=e^{\theta(\bold{x}_i)^T\phi(\bold{x}_j)} \\ \mathcal C(\bold{x})=\sum_{\forall j}f(\bold{x}_i,\bold{x}_j) \]其中
\[\theta(\bold{x}_i)=W_\theta\bold{x}_i \\ \phi(\bold{x}_j)=W_\phi \bold{x}_j \]第三种,可以考虑dot product
\[f(\bold{x}_i,\bold{x}_j)=\theta(\bold{x}_i)^T\phi(\bold{x}_j) \\ \mathcal C(\bold{x})=N \]N是x位置的个数
第四种,可以考虑Concatenation
\[f(\bold{x}_i,\bold{x}_j)=ReLU(\bold{w}_f^T[\theta(\bold{x}_i),\phi(\bold{x}_j)]) \\ \mathcal C(\bold{x})=N \]N的含义同上
根据上面的分析,可以定义Non-local Block如下
\[\bold{z}_i=W_z\bold{y}_i+\bold{x}_i \]其中 \(\bold{y_i}\) 在上面已经给定,\(+\bold{x}_i\) 则是引入了残差连接的形式
网络单元结构为

这是在三维情况下的输入(比如视频等),输入 \(\bold x\) 经由三个1×1×1卷积分别计算出 \(\theta,\phi,g\) 而后使用矩阵乘法对 \(\theta,\phi\) 进行运算,后经过softmax函数后与 \(g\) 使用矩阵乘法进行运算,最后经由1×1×1卷积产生输出,最
后使用残差连接与原始输入进行加法运算得到最终输出 \(\bold z\)其中1024代表通道数
其中f用以度量两点之间的相似度,g用以做变换
-
-
2.2 图像语义分割前沿进展
-
报告中主要讲解了两个工作,分别是Res2Net和Strip Pooling
-
2.2.1 Res2Net
-
该论文对原始的bottleneck结构进行了改进,进行了分组后多次重组以获得更多尺度的信息,增大了感受野的范围,主要结构如下

新模块具备更强的多规模特征提取能力,但计算负载量与左侧架构类似。具体而言,新模块用一个较小的3×3过滤器取代了过滤器组,同时可以将不同的过滤器组以层级残差式风格连接。
-
-
2.2.2 Strip Pooling
-
Strip Pooling是将二维池化核和水平和垂直两个方向的池化核进行串接,以获得更多大尺度信息和细节信息。首先,传统的池化操作为
\[y_{i_o,j_o}=\frac{1}{h\times w}\sum_{0\le i其中 \(0\le i_o
引入strip pooling需要引入两个池化操作,分别为
\[y_i^h=\frac{1}{W}\sum_{0\le j第一个式子也就是将某列所有横向的像素相加求平均,得到数据,对所有行进行这样的操作,即得到一列输出数据。第二个式子就是对所有竖向的像素相加求平均,最后得到一行这样的数据。
模型的整体结构为

这里的sigmoid函数是为了将输入的值转化为输出值为(0,1)的情况,在下一个模型中,使用softmax函数是为了归一化概率
首先使用strip pooling对输入进行池化,而后经过核大小为3的一维卷积,而后对数据进行一个融合,具体策略为\[y_{c,i,j}=y_{c,i}^h+y_{c,j}^v \]其中 \(c\) 表示为某个特定的通道,也就是说输出的二维矩阵的第 \(i\) 行第 \(j\) 列为 \(y^h\) 的第 \(i\) 行,\(y^v\) 的第 \(j\) 列相加的结果,其含义正好为图中所示,先将条状池化结果进行复制在行和列上分别扩容,然后对应像素相加得到输出。然后经过 \(1\times 1\) 的卷积和sigmoid的函数。最后将结果和最开始的图像进行融合,经过 \(1\times 1\) 卷积核,然后通过sigmoid函数,最后融合的策略为
\[\bold{z}=Scale(\bold{x}, \sigma(f(\bold{y}))) \]其中,\(\bold{z}\) 为最终输出,Scale函数为像素级别上的乘法,\(\sigma\) 为sigmoid函数,\(f(\bold{x})\) 为核大小为 \(1\times 1\)的卷积操作
可以看出,结果的一个像素点(在结构中由黑色框表示)将会含有输入时的一行和一列的信息(在结构中由红色框表示),当然,这种表示对左上(↖),左下(↙),右上(↗),右下(↘)的信息表示能力不够好,所以接下来引入多尺度的常规池化来弥补该缺点
以上操作称为SPM
MPM由SPM和多个尺度的常规池化卷积核组成,结构如下
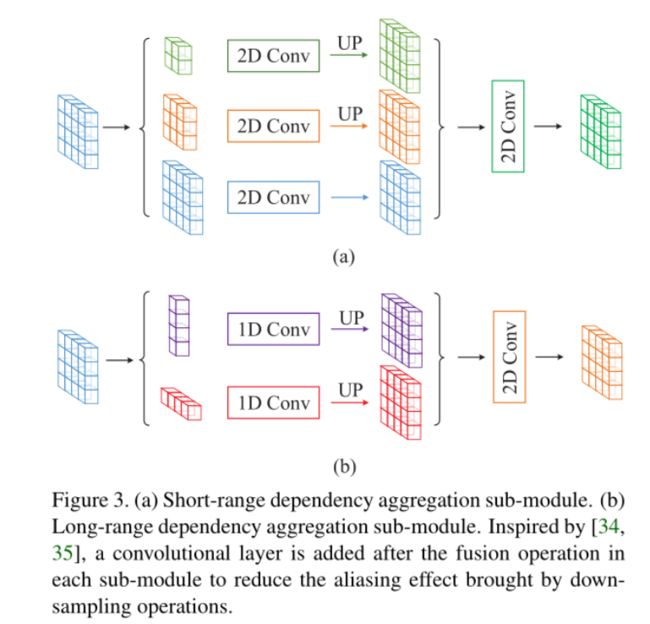
论文阅读
-
3.1 Selective Kernel Networks
-
该模型的总体结构为

对于输入 \(\bold{X}_{H^{'}\times W^{'}\times C^{'}}\) ,使用 \(3\times 3\) 与 \(5\times 5\) 两种不同的卷积核进行卷积而后经过BN层与ReLU函数,得到 \(\widetilde{\bold{U}}_{H\times W\times C},\hat{\bold{U}}_{H\times W\times C}\) 两个不同的特征图,而后对两个特征图使用element-wise summation进行融合(即对应元素逐个相加),即为
\[\bold{U}=\widetilde{\bold{U}}+\hat{\bold{U}} \]之后经过全局平均池化对 \(\bold{U}\) 进行操作,即为
\[s_c=\mathcal{F}_{gp}(\bold{U}_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^W\bold{U}_c(i,j) \]也就是二维所有像素相加后取平均
而后经过全连接层 \(W_{d\times C}\) 得到 \(\bold{z}\) ,即为
\[\bold{z}=\mathcal{F}_{fc}(\bold{s})=\delta(\mathcal{B}(\bold{Ws})) \]其中 \(\delta\) 为ReLU函数,\(\mathcal{B}\) 为batch normalization,\(d\) 为了减少维度而增加,为
\[d=max(C/r,L) \]其中 \(L\) 常取32
之后经过升维和softmax层,得到注意力向量
\[a_c=\frac{e^{\bold{A}_c\bold{z}}}{e^{\bold{A}_c\bold{z}}+e^{\bold{B}_c\bold{z}}} \\ b_c=\frac{e^{\bold{B}_c\bold{z}}}{e^{\bold{A}_c\bold{z}}+e^{\bold{B}_c\bold{z}}} \]其中 \(A,B\in \mathbb{R}_{C\times d}\),也就是升维矩阵
最后将两者融合,使用对应元素相乘的方法,即为
\[\bold{V}_c=a_c\widetilde{\bold{U}}+b_c\hat{\bold{U}},a_c+b_c=1 \]这即是SK convolution,相加等于1的原因是因为经过了softmax函数
-
-
3.2 Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
对该论文的思考请参阅2.2部分第三条
-
3.3 HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation
-
传统网络的典型设计结构为以下四种

都没有在全局保留最高分辨率的情况,不可避免地造成了数据的丢失,所以本文引进了
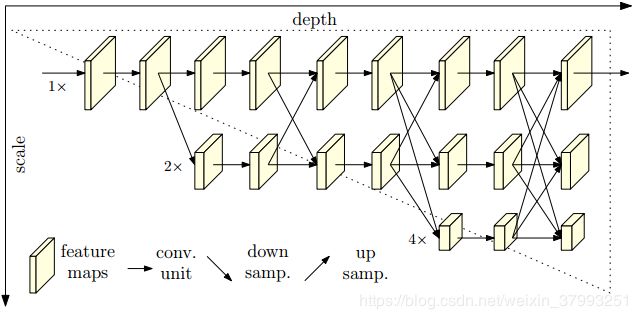
一致保留了原始分辨率信息,而后在下几层与上面层次进行连接以获得更丰富的信息
-
-
-
-