大数据技术栈速览之:YARN
在Hadoop 2.0及后续版本中,MapReduce的调度部分被外部化并重新编写为名为Yarn的新组件,但Yarn执行调度与Hadoop上运行的任务类型无关,Yarn可在Hadoop上执行除MapReduce以外的工作。
YARN生产背景
MapReduce1.x存在的问题:
1.JobTracker单点故障&节点压力大不易扩展&不支持mapreduce以外的计算框架(spark,storm)
在MapReduce1.x下的架构:MapReduce:Master/Slave架构,1个JobTracker带多个 TaskTracker
JobTracker:负责资源管理和作业调度,承受的访问压力大,影响系统扩展
TaskTracker:定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况
接收来自JT的命令:启动任务/杀死任务
单点故障:整个集群中只有一个JobTracker如果JT挂掉了全部TT都完蛋了
2.资源利用率&运维成本
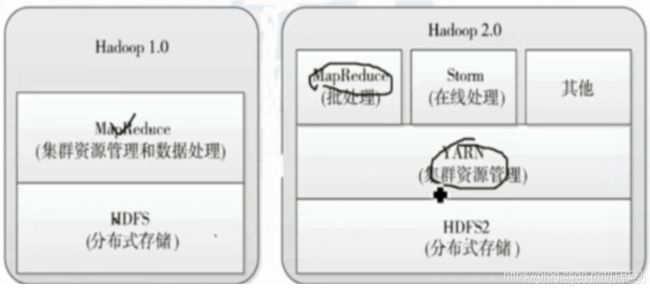
由于在MapReduce1.x的架构加只能跑MapReduce,不支持MapReduce之外的计算框架,比如Storm,spark,flink,所以想要用其他的计算框架就必须在搭建支持其他计算框架的集群。

所以由上面的图产生了共享集群的意愿,同时催生了YARN:不同的计算框架可以共享同一个HDFS集群上的数据。
YARN是一个资源管理系统,负责资源管理和调度
MapReduce只是运行在YARN上的一个应用程序
如果把YARN看作android,则mapreduce只是一个app
mapreduce1.0是一个独立系统,直接运行在linux上
mapreduce2.0则是运行在YARN上的框架,且可以与多种框架一起运行在YARN上
YARN核心思想:
将MapReduce1中的JobTracker的资源管理和作业调度两个功能分开,分别由
ResourceManager和ApplicationMaster进程来实现
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度,任务监控和容错等
Yarn与MapReduce的关系
MapReduce是一个功能强大的分布式框架和编程模型,允许在多节点集群上执行基于批处理的并行化工作。尽管MapReduce功能强大,但它也有一些缺点,比如不适合实时甚至近实时的数据处理。但是,Yarn可以弥补MapReduce的不足,其核心是分布式调度程序,负责两项工作:
-
响应客户端创建容器的请求——容器本质上可理解为一个进程(也有人理解为服务程序),其中包含允许使用的物理资源。
-
监视正在运行的容器,并在需要时终止。如果YARN调度程序想要释放资源以便其他应用程序的容器运行,或者容器使用的资源多于其分配的资源,则可以选择终止容器。
工作机制概述
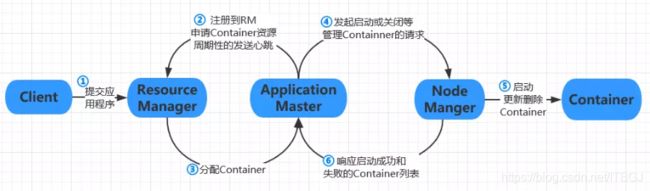
Client向RM提交应用程序,应用程序提交到RM后,AM注册到RM上,RM计算所需资源并向RM提出申请,RM返给AM资源信息,AM向NM发起启动container的请求,container启动后,NM将启动成功和启动失败的container列表发送给AM,由AM重新向RM申请资源,期间AM和NM定期的向RM发送心跳。
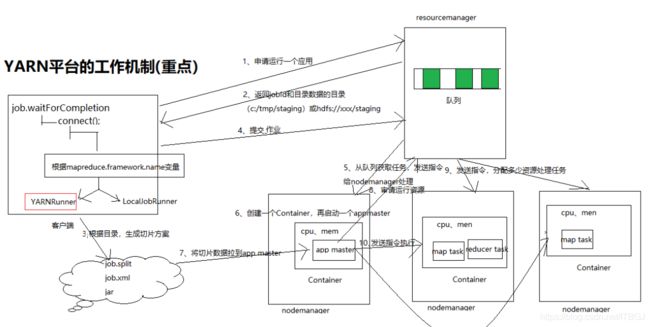
1、连接运行器平台
根据mapreduce.framework.name变量配置
如果等于yarn:则创建YARNRunner对象
如果等于Local:则创建LocalJobRunner对象
2、如果是yarn平台,对resoucemanager提交作业审请
3、resourcemanager返回一个jobid和数据保存目录(hdfs://xxx/staging/xxx)
4、客户端根据返回数据保存目录路径,将job.split、job.xml、jar文件提交到hdfs://xxx/staging/xxx目录
5、提交数据资源之后,客户端对resouremanager提交任务运行
6、resourcemanager将任务存储任务队列
7、resourcemanager发送命令nodemanager处理从任务取出的任务
8、nodemanager往resourcemanageer审请我要创建一个app master
a、在nodemanager创建一个container,再启动app master
9、app master读取数据切片处理方案
10、app master往resourcemanager审请运行资源
11、resourcemanager往空闲的nodemanager主机发送指令,要创建Container
12、app master往nodemanger发送运行指令,container运行任务。
如下图
YARN架构
YARN的出现可以使得多个计算框架运行在一个集群当中,每个应用程序对应一个ApplicatonMaster
目前可以支持多种计算框架运行在YARN上,比如MapReduce,Strom,Spark,Flink
Yarn主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。Yarn框架执行主要功能,即在集群中调度资源(上文提到的容器)。集群中的应用程序与YARN框架通信,要求分配特定于应用程序的容器资源,Yarn框架会评估这些请求并尝试实现。Yarn调度的一个重要部分是监视当前正在执行的容器,一旦容器完成,调度程序就可以释放容量来安排其他工作。此外,每个容器都有一个协议,指定允许使用的系统资源,并在容器超出边界的情况下终止容器,以避免恶意影响其他应用程序。

Yarn框架有意设计的尽可能简单,它不知道或不关心正在运行的应用程序类型,不保留有关集群上执行内容的任何历史信息,这些设计是Yarn可以扩展到MapReduce之外的主要原因。
-
ResourceManager——Hadoop集群具有至少一个ResourceManager(RM)。
RM作为一个独立的守护进程运行在专有机器上,RM拥有集群上所有资源的信息,是集群所有资源的仲裁者,只负责给应用进行资源的划分和资源的收回。这里的资源主要指:内存,带宽,内核数等。ResourceManager是Yarn的主进程,其唯一功能是仲裁Hadoop集群上的资源,响应客户端创建容器请求,调度程序根据特定的多租户规则确定何人可以在何时何地创建容器,正如Hadoop 1.0版本,ResourceManager调度程序是可选择的,这意味着你可以选择最适合的调度程序,而实际创建的容器被委托给NodeManager。
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求:提交一个作业、杀死一个作业
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何处理
RM是Master,仲裁集群中所有的可用资源,从而帮助管理运行在yarn平台上的分布式应用程序,他和下面的组件一起工作:
每个节点的NM。从RM中获取指令,管理单个节点上的可用资源,并接收AM的资源请求。
每个应用程序的AM,职责是向RM申请资源并且和NM一起工作、启动、监控和停止Container。
-
NodeManager——NodeManager是在集群每个节点上运行的从属进程。
NM是yarn在每个计算节点上的代理,他根据yarn应用程序的要求,使用每个节点上的物理资源来运行Container。NM本质上是YARN的工作守护进程。主要职责是:
保持与RM的同步
跟踪节点的健康状态
管理Container的生命周期,监控每个Container的资源使用情况(如内存,CPU等)
管理分布式缓存(对container所需的JAR,库等文件的本地文件系统缓存)
管理各个Container的日志
不同的YARN应用可能需要的辅助服务
其中Container的管理是NodeManager的核心功能。NodeManager接受来自ApplicationMaster对Container启动或者停止请求,对Container令牌进行鉴权(一种确保应用程序可以适当使用ResourceManager给定资源的安全机制),管理 Container执行依赖的库,监控 Container的执行过程。管理员通过配置文件( yarn-default. xml或yarm- site.xml)来配置每个 NodeManager的资源,包括节点上的内存、CPU及其他可用资源。在向 ResourceManager成功注册之后, NodeManager通过周期性的心跳汇报自己的状态并接收 ResourceManager可能发来的指令。
在YARN中,包括 ApplicationMaster在内的所有 Container都通过 Container launch
Context(CLC)来描述。CLC包括环境变量,依赖的库(可能存在远程存储中),下载库文件以及 Container自身运行需要的安全令牌,用于 NodeManager辅助服务的 Container专用的载荷,以及启动进程所需的命令。在验证启动 Container请求的有效性后, NodeManager会为Container配置环境,从而使管理员指定的设置生效。
在真正拉起一个 Container之前, NodeManager会将所有需要的库文件下载到本地,包括数据文件,可执行文件、 tarball、JAR文件,shel脚本等。这些下载好的库文件可以通过本地应用级别缓存被同一应用的多个 Container共享,通过本地用户级别缓存被相同用户启动的多个 Container共享,甚至通过公用缓存的方式被多个用户共享,其共享方式是通过CLC来指定的。 NodeManager最终会回收不再被任何 Container使用的库文件NodeManager也可能按照 ResourceManager的指令去杀死 Container。 Container可能在以下情况下被杀死:
- ResourceManager发送应用程序已经完成的信号
- 调度器作出要为其他应用程序或者用户抢占该 Container的决策
- NodeMananger监控到这个 Container超出了 ContainerToken中指定的资源限制
Container退出时, Node Manager就会清理掉它的本地工作目录。当应用程序完成时,其对应的 Container所有的资源都会被清理掉。
除了 Container的启动和停止,完成 Container的清理,以及对本地资源的管理Node Manager还为运行在本节点上的 Container提供了其他本地服务,例如:当应用程序 束时,日志聚集服务可以将应用程序的 Container生成的日志以及对 stdout和 stderr重定向的文件上传到一个文件系统如 ResourceManager那一节所述,当有 NodeManager失败时(这可能由很多原因引), ResourceManager通过超时机制监控到这种失败,并将该失败报告给所有运行中的应用程序。如果引发超时的故障或原因是瞬时的, NodeManager会与 ResourceManager重新同步,清理它的本地状态,然后继续服务。同样的,当一个新的 NodeManager加入到集群 ResourceManager会将这个用于运行 Container的新资源通知所有的 ApplicationMastser.
NM管理集群中独立的计算节点。
NM是每个节点上的资源和任务管理器。一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container运行状态;另一方面,它接收并处理来自AM的 Container 启动/停止等各种请求
它的主要工作是创建、监视和杀死容器。它为来自ResourceManager和ApplicationMaster的请求提供服务以创建容器,并向ResourceManager报告容器的状态。ResourceManager使用这些状态消息中包含的数据对请求做出调度决策。在非HA模式下,只存在ResourceManager单个实例。
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接受并处理来自RM的各种命令:启动Container
处理来自AM的命令
单个节点的资源管理是由它自己管理,通过心跳机制告诉RM
- ApplicationMaster:AM
每个应用程序AM都是一个引导进程,一但应用程序的提交通过了,且自身加载完成,应用程序在RM中的代表将申请一个Container来启动此引导程序,如果RM分配了Container,AM的启动器将直接与NM进行通讯,以设置并启动该container,AM的生命周期就开始了。与hadoop1中的架构相比,本质上AM是一个应用程序的JobTracker。
这个过程以应用程序提交一个请求到 ResourceManager开始。接着, ApplicationMaster启动,向 ResourceManager注册。 ApplicationMaster向 ResourceManager请求 Container执行实际的工作。将分配的 Container告知 NodeManager以便 ApplicationMaster使用。计算过程在 Container 中进行,这些 Container将与 Application Master(不是 ResourceManager)保持通信,并告知任务过程。当应用程序完成后, Container被停止, ApplicationMaster从 ResourceManager中注销
一旦成功启动, Application Master将负责以下任务:
- 初始化向 ResourceManager报告自己活跃信息的进程
- 计算应用程序的资源需求
- 将需求转换成YARN调度器可以理解的 ReqsourceReques
- 与调度器协商申请资源
- 与 NodeManager合作使用分配的 Container
- 跟踪正在运行的 Container的状态,监控它们的进程
- 对 Container或节点失败的情况进行处理,在必要的情况下重新申请资源
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例,每个应用程序对应唯一一个AM。 负责管理作业的生命周期,包括动态的增加和减少资源使用,管理作业执行流程,处理故障和计算偏差,以及执行其本地优化。
每个应用程序对应一个:MR、Spark,负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM进行通信:启动/停止task的运行,task试运行在container里面,AM也是运行在Container里面
- Container
Container是YARN中的资源抽象,是单个节点上内存,CPU,磁盘,网络等物理资源的集合,是一个任务运行环境的抽象。一个节点可以有一个或者多个container,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。其中AM可以看做是一种特殊的Container。
container由NM监控,RM调度。
Application Master从 ResourceManager获得 Container后,它就可以进行 Container的实际启动工作。启动 Container前,它首先根据需要构造 ContainerLaunchContext对象,该对象包括分配资源的大小、安全令牌(如果已启用)、启动 Container的执行命令、进程环境、必要的二进制文件/AR包/共享对象等。它可以通过与 NodeManager通信,逐一启动Container,也可以批量运行单个节点上的所有Container,向 NodeManager在单个调用里提供一系列Start ContainerRequest来启动它们。
NodeManager通过 Start ContainerResponse回应:该回应包含成功启动的 Container列表、每个失败的 Start ontainerRequest对应的 Container ID到异常的映射(记录了每个 Container的异常)、 allServices Data映射(从附加服务的名字到它们相应的元数据)。
ApplicationMaster能获取已经提交但未启动的 Container以及已经启动的 Container的更新状态。
ApplicationMaster可以向 Node Manager发送 Stop ContainersRequest请求,停止在该节点上运行的一系列 Container,该请求包含待停止的 Container ID。 NodeManager通过Stop ContainersResponse回应,它包含成功停止的 Container的列表以及每个失败的请求中Container id到异常的映射(异常信息表示了每个特定 Container的错误)。当 ApplicationMaster退出时, ResourceManager将根据它提交的上下文杀死所有正在运行而没有被 ApplicatMaster显示终止的 Container
如上文所述,当 Container结束时, ResourceManager将以事件的形式通知 Application Master
ResourceManager并不解释(也不关心) Container的状态,只有 ApplicationMaster才能决定ResourceManager报告的 Container的退出状态成功或失败的含义。
处理 Container失败是应用程序/框架的责任。YARN只负责为应用程序/框架提供信息。
ResourceManager收集所有已完成的 Container的信息,把它们作为 API allocate的回应信息部分返回给相应的 Application. ApplicationMaster负责查看如下信息: Container的状态、退出码和诊断信息,并恰当地处理它。例如,当 MapReduce Application Master知道Container失败时,它向 ResouceManager请求新的 Container,重新运行Map或 Reduce任务直到达到为单个任务配置的最大的尝试次数。
- Client
提交作业
查询作业的运行进度
杀死作业
小结:
Application Master需要在由于它自身原因重启后恢复应用程序。当 Application Master失败时, ResourceManager简单地通过重新启动一个新的 ApplicationMaster(更确切地说是运行 ApplicationMaster的 Container)来重启应用程序(新的 ApplicationMaster将启动新的Application Attempt,恢复应用程序的先前的状态是新 Application.的责任。这个目标可以通过以下方法实现:前 ApplicationAttempt将当前状态持久化到外部存储供后面的ApplicationAttempt使用显然 ApplicationMaster也可以从头开始运行应用程序,而不是恢复其过去的状态。例如,如本书所述不 Hadoop MapReduce框架的 Application Master会恢复已完成的任务,但会杀死正在运行的任务以及在 Application Master恢复时完成的任务,然后重新运行它们。
YARN的资源模型
在早期的 Hadoop版本中,集群中的每个节点被静态的分配好预先定义的Map槽位和Reduce槽位数,槽位不能在Map和 Reduce之间共享。槽位的这种静态分配不是最优的,因为对槽位的需求会在MapReduce应用程序的生命周期中变化。通常情况下,在作业刚启动时,有Map槽位的需求,相对的,在作业快结束时,主要是 Reduce槽位的需求。
YARN的资源分配模型通过提供了更大的灵活性,解决了静态分配的低效率问题。如先前所述,使用 Container的方式来请求资源,每个 Container都有一些非静态属性,YARN目前已经支持内存和CPU的动态属性,还可以支持如带宽和GPU等。在未来的资源管理模型中,每个属性定义一个最小和最大值, ApplicationManager可以请求最小值整数倍的资源container。在应用运行的过程中,AM可以对资源进行增加或者回收,达到动态调整资源的目的。

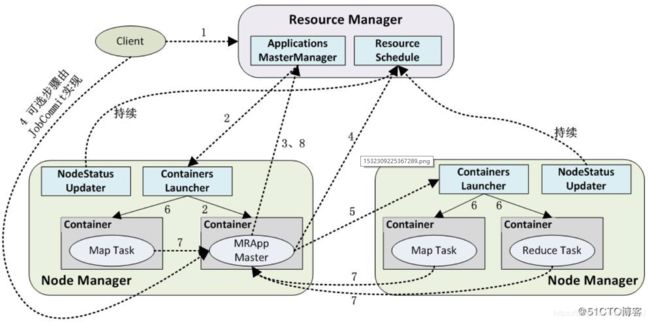
5.1、客户端资源请求
第一步:客户发送一个即将要提交程序的请求
第二步:RM在应答中给出一个ApplicationID,以及有助于客户端请求资源的就请你容量信息
5.2、Container分配
接下来,客户端在第3步中使用“ Application Submission Context”发出响应, Application
Submission上下文中包含了 ApplicationID、用户名、队列以及其他启动 Application Master所
需求(内存CPU)、作业文件、安全令牌以及在节点上启动 Application Master 需要的其他信息。应用程序被提交之后,客户端也可以向 ResourceManager请求杀死这个应用程序,或者提供该应用程序的状态报告
当ResourceManager收到来自客户端的应用程序提交上下文,它就会为ApplicationMaster调度一个可用 Container,这个 Container通常称为“ Container0”",因为它是ApplicationMaster,必须请求其他的 Container。如果没有适用的 Container,这个请求必须等待。如果找到了合适的 Container, ResourceManager就会联系相应的 NodeManager并启动 ApplicationMaster(图第4步)。作为此步骤的一部分,将建立 ApplicationMaster的RPC端口和用于跟踪的URL,用来监控应用程序的状态。
在注册请求的响应中, ResourceManager会发送关于集群的最小和最大容量信息(第5步)。在这一点上, ApplicationMaster须决定如何使用当前可用的资源。与一些客户端请求硬限制的资源调度系统不同,YARN允许应用程序适应当前的集群环境(如果可能的话)。基于来自 ResourceManager的可用资源报告, ApplicationMaster会请求一定量的Container(图第6步)。该请求可以非常具体,包括最小资源整数倍的 Container(例如,额外的内存)。 ResourceManager会基于调度策略,尽可能最优的Application Master分配Container资源,作为资源请求的应答发给 Application Master(图第7步)。
随着作业的执行, ApplicationMaster将心跳和进度信息通过心跳发给 ResourceManager。在这些心跳中, ApplicationMaster还可以请求和释放 Container,当作业结束时, Application Master向 ResourceManager发出一个 Finish消息,然后退出。
5.4、ApplicationMaster与Container管理器的通信

在这一点上, ResourceManager已经将分配 NodeManager的控制权移交给ApplicationMaster
,AM将独立联系其指定的节点管理器并提供 Container launch Context(CLC),CLC包括环境变量、远程存储依赖文件、安全令牌以及启动实际进程所需的命令。当 Container启动时,所有的数据文件,可执行文件以及必要的依赖文件都被拷贝到节点的本地存储上了。依赖文件可以被运行中的应用程序的 Container之间共享。一旦所有的 Container都被启动, ApplicationMaster就可以检查它们的状态, RM不参与应用程序的执行,只处理调度和监控其他资源。 RM可以命令NM杀死Container,在AM通知RM自己完成了,或者ResourceManager需要为另一个应用程序抢占资源,或者 Container超出资源限制时都可能发生杀死 Container事件。当 Container被杀死后, NodeManager会清理它的本地工作目录。作业结束后, ApplicationMaster通知 ResourceManager该作业成功完成,然后ResourceManager通知 NodeManager聚集日志并且清理 Container专用的文件。如果 Container还没有退出NodeManager也可以接受指令去杀死剩余的 Container(包括 ApplicationMaster)。
5.5、管理应用程序的依赖文件
在YARN中,应用程序通过运行 Container来执行它们的工作,这些 Container对应于运行在底层操作系统上的进程。 Container上有执行程序依赖的文件,这些文件在启动时或者应用程序的执行过程中可能需要一次或者多次。例如,要在 Container中启动一个简单的Java进程,我们需要一组类文件或更多依赖的JAR文件。YARN没有强迫每个应用程序每次都远程访问(大部分是读)这些文件或者让它们自己管理这些文件,而是为应用程序提供了本地化这些文件的能力。
当启动一个 Container时, Application Master可以指定该 Container需要的所有文件,因此,这些文件都应该被本地化。一且指定了这些文件,YARN就会负责本地化,并且隐藏所有安全拷贝、管理以及后续的删除等引入的复杂性。
YARN执行流程

Yarn应用程序具备在Hadoop上运行的特定功能,MapReduce是YARN应用程序的一个示例,Hoya等项目允许多个HBase实例在单个集群上运行,而Storm-yarn允许Storm在Hadoop集群内运行。


YARN应用程序典型交互
Yarn应用程序涉及三大组件 - 客户端,ApplicationMaster(AM)和容器,如图2.3所示。启动新的Yarn应用程序需从Yarn客户端开始,该客户端与ResourceManager通信以创建新的Yarn ApplicationMaster实例,此过程Yarn客户端会让ResourceManager通知ApplicationMaster物理资源要求。
ApplicationMaster是Yarn应用程序主进程,不执行任何特定于应用程序的工作,因为这些函数被委托给容器。但是,它负责管理特定于应用程序的容器:询问ResourceManager其创建容器的意图,然后与NodeManager联系以实际执行容器创建。作为此过程的一部分,ApplicationMaster必须根据主机启动容器,并确定容器的内存和CPU要求以指定容器所需资源。
ResourceManager根据资源要求安排工作,它使主机能够运行混合容器,如图2.4所示。ApplicationMaster负责应用程序的特定容错,在容器失败时从ResourceManager接收状态消息,并基于具体事件采取操作(通过要求ResourceManager创建新容器解决)或忽略这些事件。
容器是由NodeManager代表ApplicationMaster创建的特定于应用程序的进程。ApplicationManager本身也是一个由ResourceManager创建的容器。由ApplicationManager创建的容器可以是任意进程——例如,容器进程可以是简单的Linux命令,例如awk,Python应用程序或可由操作系统启动的任何进程,这也是YARN强大功能的体现——可以在Hadoop集群的任何节点启动和管理任何进程。
Yarn配置
Yarn为各组件带来了强大的配置,例如UI、远程进程调用(RPC)等。在选择之前,你需要弄清楚想要访问的正在运行的Hadoop集群配置,你可以使用ResourceManager UI查看相关配置。
该功能的亮点在于UI不仅可以显示属性值,还可以显示文件来源。如果未在
Yarn开箱即用
Hadoop 2捆绑了两个Yarn应用程序——MapReduce 2和DistributedShell。如果你不清楚集群配置,则有两个办法可以解决:
-
检查yarn-site.xml的内容以查看属性值。如果不存在自定义值,则默认值将生效。
-
使用ResourceManager UI,它提供了有关运行配置的详细信息,包括默认值以及是否生效。
如果希望在Hadoop集群节点上运行Linux命令,可以使用与Hadoop捆绑在一起的DistributedShell示例应用程序。该应用程序也是在Hadoop集群中并行运行命令的便捷实用程序。
更多实战观摩:http://blog.itpub.net/31077337/viewspace-2213602/
YARN 系统架构
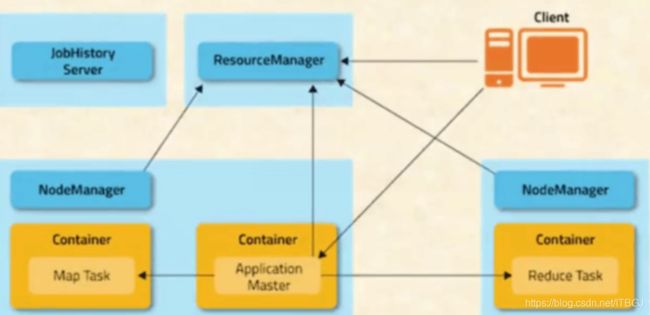
ResourceManager
负责集群中所有资源的统一管理和分配,它接受来自各个节点的NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序,是整个YARN集群中最重要的组件之一,他的设计直接决定了系统的可扩展性,可用性和容错性,它的功能较多,包括ApplicationMaster管理,NodeManager管理,Application管理,状态机管理等
主要有以下几个功能:
1.与客户端交互,处理来自客户端的请求
2.启动和管理ApplicationMaster,
并且在它失败时重新启动它
3.管理NodeManager,接受来自NodeManager的资源汇报信息,下达管理指令
4.资源管理和调度,接受来自ApplicationMaster的资源申请请求并向让NodeManager为之分配资源
Nodemanager
是运行在单个节点上的代理,管理hadoop集群中单个计算节点,他需要与相应用程序的ApplicationMaster和集群管理者ResourceManager交互
1.从ApplicationMaster上接收有关Contioner的命令并执行
2.向ResourceManager汇报各个container运行状态和节点健康状况,并领取有关的Container的命令并执行
ApplicationMaster
与应用程序相关的组件
1.负责数据切分,把每份数据分配给对应的Map Task
2.为应用程序申请资源并进一步分配给内部的任务。比如从ResourceManager获取分配的资源,然后分配给Task任务
3.任务的监控与容错。一旦一个任务挂掉之后,他可以重新向ResourceManager申请资源
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存,CPU,磁盘,网络等。当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。
YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。需要注意的是,Container不同于MR(mapreduce)v1中的slot(也是资源分配单位),他是一个动态资源划分单位,是根据应用程序的需求动态生成的
MapReduce on YARN
运行在YARN上的应用程序分为两类:短应用程序和长应用程序
短应用程序:是指在一定时间内可以运行完成并正常退出的应用程序,不如MapReduce作业 离线计算
长应用程序:是指不出意外,永不停止的应用程序,通常是一些服务
比如Storm Service(主要包括Nimbus和Supervisor两类服务)、HBase Service(包括Hmaste:和RegionServer两类服务)等,而他们本身作为一个框架提供了编程接口供用户使用 spark 实时计算
当用户向YARN中提交一个应用程序后,YARN将分为两个阶段运行该应用程序:
第一个阶段是启动ApplicationMaster
第二个阶段是由ApplicationMater创建应用程序,,为它申请资源,并监控它的整个运行过程,直到运行完成
YARN中内存和CPU两种资源的调度和隔离(转载自董的博客)
YARN同时支持内存和CPU两种资源的调度(默认只支持内存,如果想进一步调度CPU,需要自己进行一些配置)
【YARN中内存资源的调度和隔离】
基于以上考虑,YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的只是自己可以使用的,配置参数如下:
(1)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(2)yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。
(3) yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(4) yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(5)yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(6)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制。
【YARN中CPU资源的调度和隔离】
在YARN中,CPU资源的组织方式仍在探索中,目前(2.2.0版本)只是一个初步的,非常粗粒度的实现方式,更细粒度的CPU划分方式已经提出来了,正在完善和实现中。
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。在YARN中,CPU相关配置参数如下:
(1)yarn.nodemanager.resource.cpu-vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。
(2) yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
(3)yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是32。
默认情况下,YARN是不会对CPU资源进行调度的,你需要配置相应的资源调度器让你支持,具体可参考我的这两篇文章:
(1)Hadoop YARN配置参数剖析(4)—Fair Scheduler相关参数
(2)Hadoop YARN配置参数剖析(5)—Capacity Scheduler相关参数
默认情况下,NodeManager不会对CPU资源进行任何隔离,你可以通过启用Cgroups让你支持CPU隔离。
由于CPU资源的独特性,目前这种CPU分配方式仍然是粗粒度的。举个例子,很多任务可能是IO密集型的,消耗的CPU资源非常少,如果此时你为它分配一个CPU,则是一种严重浪费,你完全可以让他与其他几个任务公用一个CPU,也就是说,我们需要支持更粒度的CPU表达方式。
借鉴亚马逊EC2中CPU资源的划分方式,即提出了CPU最小单位为EC2 Compute Unit(ECU),一个ECU代表相当于1.0-1.2 GHz 2007 Opteron or 2007 Xeon处理器的处理能力。YARN提出了CPU最小单位YARN Compute Unit(YCU),目前这个数是一个整数,默认是720,由参数yarn.nodemanager.resource.cpu-ycus-per-core设置,表示一个CPU core具备的计算能力(该feature在2.2.0版本中并不存在,可能增加到2.3.0版本中),这样,用户提交作业时,直接指定需要的YCU即可,比如指定值为360,表示用1/2个CPU core,实际表现为,只使用一个CPU core的1/2计算时间。注意,在操作系统层,CPU资源是按照时间片分配的,你可以说,一个进程使用1/3的CPU时间片,或者1/5的时间片。对于CPU资源划分和调度的探讨,可参考以下几个链接:
https://issues.apache.org/jira/browse/YARN-1089
https://issues.apache.org/jira/browse/YARN-1024
Hadoop 新特性、改进、优化和Bug分析系列5:YARN-3
【总结】
目前,YARN 内存资源调度借鉴了Hadoop 1.0中的方式,比较合理,但CPU资源的调度方式仍在不断改进中,目前只是一个初步的粗糙实现,相信在不久的将来,YARN 中CPU资源的调度将更加完善。
附:
yarn的搭建(参考:https://www.cnblogs.com/yuanyifei1/p/8474196.html):
yarn是hadoop的一个子项目,在yarn上面搭建spark集群需要配置好hadoop和spark。 yarn的包是包含在hadoop里面的。
解压hadoop压缩包,配置环境变量,修改配置文件,node格式化……等后,直接启动就ok了。
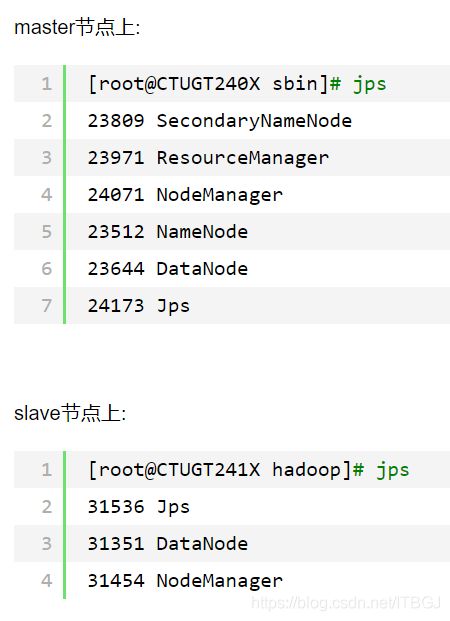
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh #启动yarn启动成功后可以使用jps命令查看各个节点上是否启动了对应进程。