第四天:Spark Streaming
Spark Streaming概述
1. Spark Streaming是什么
Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。

和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间(采集周期)收到的数据都作为 RDD 存在,而DStream是由这些RDD所组成的序列(因此得名离散化)。
2. Spark Streaming特点
- 易用
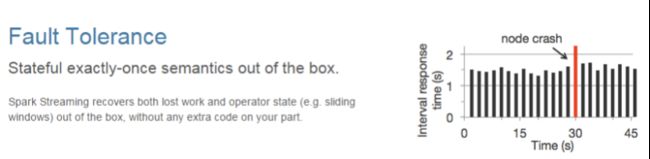
- 容错
- 易整合到Spark体系

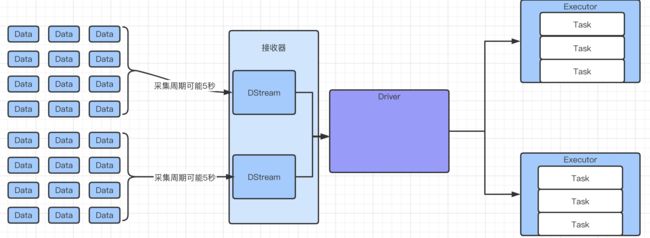
3. Spark Streaming架构
架构图
多了一个接收器,一个StreamingContext。
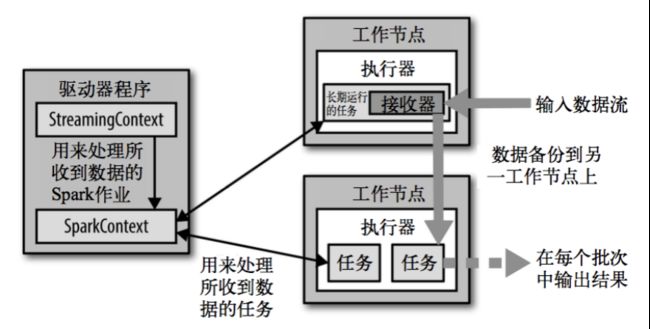
整体架构图:
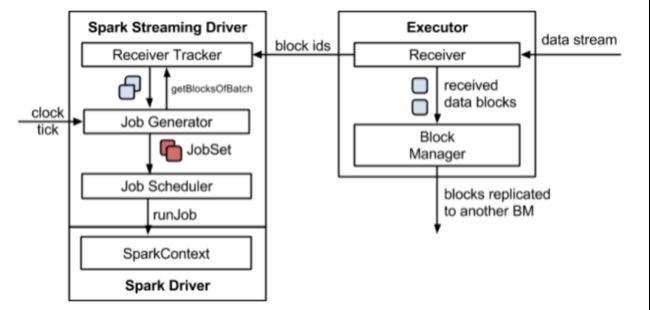
形象图
背压机制
Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数spark.streaming.receiver.maxRate的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure):
根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。 通过属性spark.streaming.backpressure.enabled来控制是否启用backpressure`机制,默认值false,即不启用。
第2章 Dstream入门
WordCount案例实操
需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!--<scope>provided</scope>-->
</dependency>
</dependencies>
scala
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by wuyufei on 06/09/2017.
*/
object WorldCount {
def main(args: Array[String]) {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
// 间隔采集周期, 若干半生类
val ssc = new StreamingContext(conf, Seconds(2))
ssc.checkpoint("./checkpoint")
// Create a DStream that will connect to hostname:port, like localhost:9999, 一行一行的接受数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9000)
val linesFile: DStream[String] = ssc.textFileStream("test")
//监控文件夹里的内容,然后从别的地方把文件移动到test中即可。不过Flume 也可以做并且做的更好, 一般不会用上述方法。
// Split each line into words
val words: DStream[String] = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs: DStream[(String, Int)] = words.map(word => (word, 1))
val wordCounts: DStream[(String, Int)] = pairs.reduceByKey(_ + _)
wordCounts.print()
// 启动采集器
ssc.start()
// Driver等待采集器执行
ssc.awaitTermination()
//ssc.stop() // 把采集流停止 一般不用 因为是不间断的
}
}
测试:
[atguigu@hadoop102 spark]$ nc -lk 9000
hello sowhat
hello hello
hello hello
s s s
注意:如果程序运行时,log日志太多,可以将spark conf目录下的log4j文件里面的日志级别改成WARN或者ERROR。
WordCount解析
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
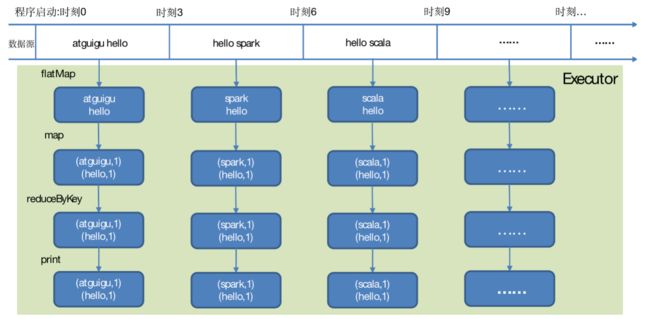
第三章 Dstream创建
1. RDD队列
用法及说明
测试过程中,可以通过使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
需求:间隔性的发送数据, 间隔性的从内存队列取出数据,统计取出数据%10的结果个数
编写代码
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
/**
* 间隔性的发送数据, 间隔性的从内存队列取出数据,统计取出数据%10的结果个数
* */
object QueueRdd {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("QueueRdd")
val ssc = new StreamingContext(conf, Seconds(1))
// Create the queue through which RDDs can be pushed to
// a QueueInputDStream
//创建RDD队列
val rddQueue = new mutable.SynchronizedQueue[RDD[Int]]()
// Create the QueueInputDStream and use it do some processing
// 创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue)
//处理队列中的RDD数据
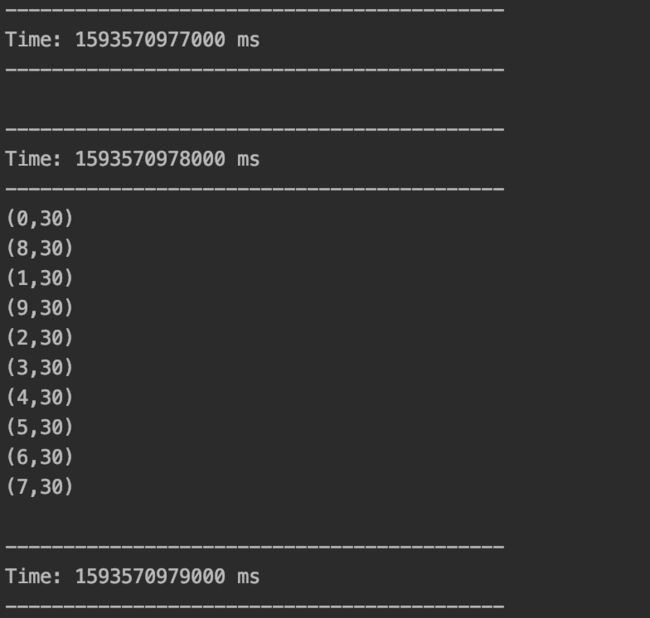
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
//启动计算
ssc.start()
// Create and push some RDDs into
for (i <- 1 to 30) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
//通过程序停止StreamingContext的运行
//ssc.stop()
}
ssc.awaitTermination()
}
}
2. 自定义数据源
用法及说明
需要继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
案例实操
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
代码:
package com.atguigu.streaming
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 模仿 package org.apache.spark.streaming.dstream.SocketReceiver
*/
// String就是接收數據的類型
class CustomReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
override def onStart(): Unit = {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
override def onStop(): Unit = {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself if isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
// Connect to host:port
socket = new Socket(host, port)
// Until stopped or connection broken continue reading
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while (!isStopped && userInput != null) {
// socket 接受数据 需要一个结束的信号
// 內部的函數,將數據存儲下倆
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
// Restart in an attempt to connect again when server is active again
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
// restart if could not connect to server
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
// restart if there is any other error
restart("Error receiving data", t)
}
}
}
object CustomReceiver {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999,自定义数据源的操作
val lines = ssc.receiverStream(new CustomReceiver("localhost", 9999))
// Split each line into words
val words = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
总结:依葫芦画瓢,继承必须的类,重写方法实现自己业务逻辑。
3. Kafka数据源(面试开发重点)
用法及说明
在工程中需要引入Maven工件spark-streaming-kafka-0-8_2.11来使用它。包内提供的 KafkaUtils对象可以在StreamingContext和JavaStreamingContext中以你的Kafka消息创建出 DStream。
两个核心类:KafkaUtils、KafkaCluster
案例实操
需求:通过SparkStreaming从Kafka读取数据,并将读取过来的数据做简单计算(WordCount),最终打印到控制台。
简单版
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>sparkStreamingartifactId>
<groupId>com.atguigugroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>sparkstreaming_windowWordCountartifactId>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.10.2.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>${spark.version}version>
dependency>
dependencies>
<build>
<finalName>statefulwordcountfinalName>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.atguigu.streaming.WorldCountmainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
plugins>
build>
project>
代码
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
// 间隔采集周期, 若干半生类
val ssc = new StreamingContext(conf, Seconds(2))
ssc.checkpoint("./checkpoint")
// Create a DStream that will connect to hostname:port, like localhost:9999, 一行一行的接受数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9000)
// 这里主要是创建好 sparkStream如何跟消费Kafka的 逻辑代码
val value: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, "zpIp:2181", "sowhatGroup", Map("sowhat" -> 3))
// Split each line into words 接受到的Kafka数据都是KV对,一般情况下不传K而已,
val words: DStream[String] = value.flatMap(_._2.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs: DStream[(String, Int)] = words.map(word => (word, 1))
val wordCounts: DStream[(String, Int)] = pairs.reduceByKey(_ + _)
wordCounts.print()
// 启动采集器
ssc.start()
// Driver等待采集器执行
ssc.awaitTermination()
//ssc.stop() // 把采集流停止 一般不用 因为是不间断的
}
}
连接池版
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<artifactId>sparkstreaming_kafkaartifactId>
<groupId>com.atguigugroupId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
<version>2.4.2version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.10.2.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>${spark.version}version>
dependency>
dependencies>
<build>
<finalName>kafkastreamingfinalName>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.atguigu.streaming.KafkaStreamingmainClass>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
plugins>
build>
project>
KafkaStreaming:
package com.atguigu.streaming
import org.apache.commons.pool2.impl.{GenericObjectPool, GenericObjectPoolConfig}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
//单例对象
object createKafkaProducerPool {
//用于返回真正的对象池GenericObjectPool
def apply(brokerList: String, topic: String): GenericObjectPool[KafkaProducerProxy] = {
val producerFactory = new BaseKafkaProducerFactory(brokerList, defaultTopic = Option(topic))
val pooledProducerFactory = new PooledKafkaProducerAppFactory(producerFactory)
//指定了你的kafka对象池的大小
val poolConfig = {
val c = new GenericObjectPoolConfig
val maxNumProducers = 10
c.setMaxTotal(maxNumProducers)
c.setMaxIdle(maxNumProducers)
c
}
//返回一个对象池
new GenericObjectPool[KafkaProducerProxy](pooledProducerFactory, poolConfig)
}
}
object KafkaStreaming {
def main(args: Array[String]) {
//设置sparkconf
val conf = new SparkConf().setMaster("local[4]").setAppName("NetworkWordCount")
//新建了streamingContext
val ssc = new StreamingContext(conf, Seconds(1))
//kafka的地址
val brobrokers = "192.168.56.150:9092,192.168.56.151:9092,192.168.56.152:9092"
//kafka的队列名称
val sourcetopic = "source1";
//kafka的队列名称
val targettopic = "target1";
//创建消费者组名
var group = "con-consumer-group"
//kafka消费者配置
val kafkaParam = Map(
"bootstrap.servers" -> brobrokers, //用于初始化链接到集群的地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
"group.id" -> group,
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "latest",
//如果是true,则这个消费者的偏移量会在后台自动提交
"enable.auto.commit" -> (false: java.lang.Boolean),
//ConsumerConfig.GROUP_ID_CONFIG
);
//创建DStream,返回接收到的输入数据
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Array(sourcetopic), kafkaParam))
//每一个stream都是一个ConsumerRecord
stream.map(s => ("id:" + s.key(), ">>>>:" + s.value())).foreachRDD(rdd => {
//对于RDD的每一个分区执行一个操作
rdd.foreachPartition(partitionOfRecords => {
// kafka连接池。
val pool = createKafkaProducerPool(brobrokers, targettopic)
//从连接池里面取出了一个Kafka的连接
val p = pool.borrowObject()
//发送当前分区里面每一个数据
partitionOfRecords.foreach { message => System.out.println(message._2); p.send(message._2, Option(targettopic)) }
// 使用完了需要将kafka还回去
pool.returnObject(p)
})
//更新offset信息
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
})
ssc.start()
ssc.awaitTermination()
}
}
第4章 DStream转换
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
1. 无状态转化操作
无状态转化操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。部分无状态转化操作列在了下表中。注意,针对键值对的DStream转化操作(比如 reduceByKey())要添加import StreamingContext._才能在Scala中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。
例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by wuyufei on 06/09/2017.
*/
object WorldCount {
def main(args: Array[String]) {
val conf:SparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc:StreamingContext = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("./checkpoint")
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 注意此处是无状态的,每次只处理对应的时间间隔数据!!
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
2. 有状态转化操作
1. UpdateStateByKey
UpdateStateByKey原语用于记录历史记录,有时,我们需要在DStream中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的DStream,其内部的RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。 - 整体过程有点类似 SparkSQL中的 自定义函数求均值,其中中间和跟个数的存储,不过这里是存储早checkpoint中,保存到硬盘。
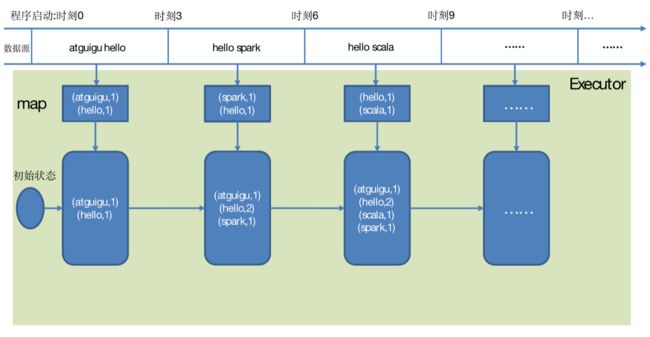
更新版的 wordcount
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by wuyufei on 06/09/2017.
*/
object WorldCount {
def main(args: Array[String]) {
val conf:SparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc:StreamingContext = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("./checkpoint")
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 上面给每个数据提供了 个数1, 然后 根据key 分组后就有个Seq[Int]的数据,然后不同的时间段数据需要累计 需要一个中间缓冲变量 buffer .
val wordCounts: DStream[(String, Int)] = pairs.updateStateByKey {
case (seq, buffer) => {
val sum: Int = buffer.getOrElse(0) + seq.sum
Option(sum)
}
}
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
2. WindowOperations
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
- 窗口时长:计算内容的时间范围;
- 滑动步长:隔多久触发一次计算。
注意:这两者都必须为批次大小的整数倍。
如下图所示WordCount案例:窗口大小为批次的2倍,滑动步等于批次大小。
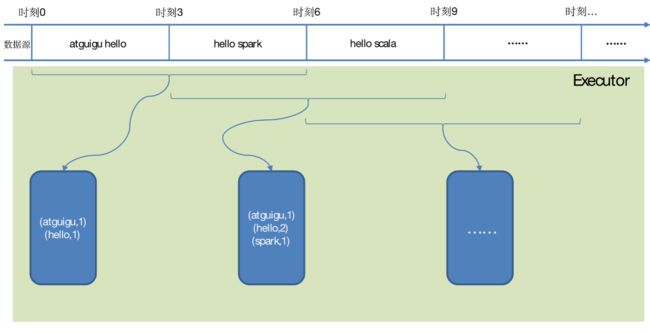
WordCount第三版:3秒一个批次,窗口12秒,滑步6秒。
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck")
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("hadoop102", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(12), Seconds(6))
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
关于Window的操作还有如下方法:
- window(windowLength, slideInterval):
基于对源DStream窗化的批次进行计算返回一个新的Dstream;
- countByWindow(windowLength, slideInterval):
返回一个滑动窗口计数流中的元素个数;
- reduceByWindow(func, windowLength, slideInterval):
通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]):
这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。
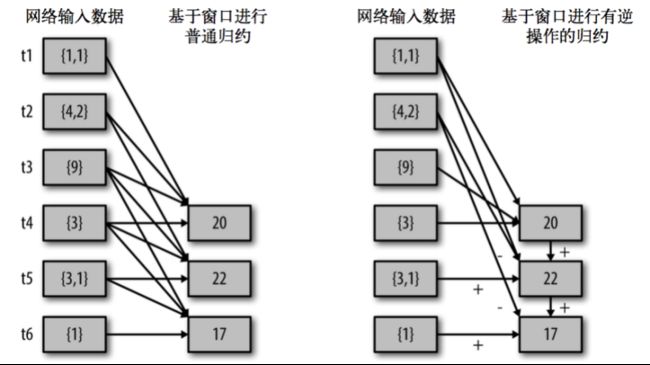
al ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y},
{(x, y) => x - y},
Seconds(30),
Seconds(10))
//加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长
countByWindow()和countByValueAndWindow()作为对数据进行计数操作的简写。countByWindow()返回一个表示每个窗口中元素个数的DStream,而countByValueAndWindow()返回的DStream则包含窗口中每个值的个数。
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))

3. 其他重要操作
1. Transform
Transform原语允许DStream上执行任意的RDD-to-RDD函数,即使这些函数并没有在DStream的API中暴露处理,通过改函数可以方便的扩展Spark API,改函数每一批次调用一次,其实也就是DStream中的RDD应用转换, 比如下面的例子,单词统计要过滤掉spam信息
val spamRDD = ssc.sparkContext.newAPIHadoopRDD()
val cleanDStream = wordCounts.transform{
rdd=> {rdd.join(spamInfoRDD).filter()}
}
---
关键是理解 执行次数的不同!
// 转换
// TODO 代码 Driver 执行 1次
val a = 1
socketLineDStream.map{
case x =>{
// TODO executor执行 n次
val a = 1 // 执行N 次
x
}
}
// TODO Driver中执行一次
socketLineDStream.transform{
case rdd=>{
// TODO Driver 执行 执行 周期次
rdd.map{
case x=> {
// todo Executor 执行 N次
x
}
}
}
}
2. Join
连接操作(leftOuterJoin、rightOutJoin、fullOuterJoin也可以),可以连接Stream-Stream,windows-Stream to windows-stream
第5章 DStream输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
输出操作如下:
- print():
在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。在Python API中,同样的操作叫print()。
- saveAsTextFiles(prefix, [suffix]):
以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”。
- saveAsObjectFiles(prefix, [suffix]):
以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。
- saveAsHadoopFiles(prefix, [suffix]):
将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API 中目前不可用。
- foreachRDD(func):
这是最通用的输出操作,即将函数 func 用于产生于 stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。通用的输出操作foreachRDD(),它用来对DStream中的RDD运行任意计算。这和transform() 有些类似,都可以让我们访问任意RDD。在foreachRDD()中,可以重用我们在Spark中实现的所有行动操作。比如,常见的用例之一是把数据写到诸如MySQL的外部数据库中。
注意:
6. 数据库的连接不能写在driver层面(因为链接无法序列化)
7. 如果写在foreach则每个RDD中的每一条数据都创建,得不偿失
8. 增加foreachPartition,在分区创建(获取)
参考
Spark全套资料