R语言实现主成分分析与典型相关分析
《数据分析方法》–梅长林 各章原理及R语言实现
- 数据描述性分析
- 回归分析
- 方差分析
4. 主成分分析与典型相关分析 - 判别分析
- 聚类分析
- Bayes统计分析
4.1主成分分析
4.1.1总体主成分的求法
求主成分归结为求样本( X X X)的协方差矩阵 Σ \Sigma Σ的特征值和特征向量问题,具体由如下结论:
设 Σ \Sigma Σ是 X = ( X 1 , X 2 , . . . , X p ) T X=(X_1,X_2,...,X_p)^T X=(X1,X2,...,Xp)T的而协方差矩阵,其特征值按大小顺序排列为 λ 1 ≥ λ 2 ≥ . . . ≥ λ p ≥ 0 \lambda_1 \geq \lambda_2 \geq ...\geq \lambda_p \geq 0 λ1≥λ2≥...≥λp≥0,相应的正交单位化向量为 e 1 , e 2 , . . . , e p e_1,e_2,...,e_p e1,e2,...,ep,则 X X X的第 k k k个主成分可表示为
Y k = e k T X = e k 1 X 1 + e k 2 X 2 + . . . + e k p X p , k = 1 , 2 , . . . , p , Y_k = e_k ^ TX=e_{k1}X_1 + e_{k2}X_2 + ... + e_{kp}X_p, \quad k=1,2,...,p, Yk=ekTX=ek1X1+ek2X2+...+ekpXp,k=1,2,...,p,
其中 e k = ( e k 1 , e k 2 , . . . , e k p ) T e_k=(e_{k1},e_{k2},...,e_{kp})^T ek=(ek1,ek2,...,ekp)T,并且我们知道 e k 1 X 1 , e k 2 X 2 , . . . , e k p X p e_{k1}X_1 , e_{k2}X_2 , ... , e_{kp}X_p ek1X1,ek2X2,...,ekpXp相互独立,这时有:
{ V a r ( Y k ) = e k T Σ e k = λ k e k T e k = λ k , k = 1 , 2 , . . . , p , C o v ( Y j , Y k ) = e j T Σ e k = λ k e j T e k = 0 , j ≠ k , \begin{cases} &Var(Y_k) = e_k^T\Sigma e_k = \lambda_k e_k^Te_k = \lambda _k, \quad k=1,2,...,p,\\ &Cov(Y_j, Y_k) = e_j^T\Sigma e_k = \lambda_k e_j^Te_k = 0, \quad j\neq k, \end{cases} {Var(Yk)=ekTΣek=λkekTek=λk,k=1,2,...,p,Cov(Yj,Yk)=ejTΣek=λkejTek=0,j=k,
事实上,令 P = ( e 1 , e 2 , . . . , e p ) P=(e_{1},e_{2},...,e_{p}) P=(e1,e2,...,ep),则 P P P为正交矩阵,且
P T Σ P = Λ = D i a g ( λ 1 , λ 2 , . . . , λ p ) , P^T\Sigma P=\Lambda=Diag(\lambda_1 , \lambda_2 , ..., \lambda_p), PTΣP=Λ=Diag(λ1,λ2,...,λp),
其中 D i a g ( λ 1 , λ 2 , . . . , λ p ) Diag(\lambda_1 , \lambda_2 , ..., \lambda_p) Diag(λ1,λ2,...,λp)表示对角矩阵(因为协方差矩阵是实对称矩阵,所以可以正交对角化)。
若 Y 1 = a 1 T X Y_1=a_1^TX Y1=a1TX为 X X X的第一主成分,其中 a 1 T a 1 = 1 a^T _ 1a_1=1 a1Ta1=1(约束条件:a的模为1,要不方差可以无穷大)令
z 1 = ( z 11 , z 12 , . . . , z 1 p ) T = P T a 1 z_1=(z_{11},z_{12}, ...,z_{1p})^T=P^Ta_1 z1=(z11,z12,...,z1p)T=PTa1
则 z 1 T z 1 = a 1 T P P T a 1 = a 1 T a 1 = 1 , 且 z_1^Tz_1=a_1^TPP^Ta_1=a_1^Ta_1=1,且 z1Tz1=a1TPPTa1=a1Ta1=1,且
V a r ( Y 1 ) = a 1 T Σ a 1 = z 1 T P T Σ P z 1 = λ 1 z 11 2 + λ 2 z 12 2 + . . . + λ p z 1 p 2 ≤ λ 1 z 1 T z 1 = λ 1 \begin{aligned} Var(Y_1)&=a_1^T\Sigma a_1 = z_1^TP^T\Sigma Pz_1\\&= \lambda_1z_{11} ^2 + \lambda_2 z_{12} ^ 2 + ... + \lambda_pz_{1p} ^ 2 \\& \leq \lambda_1z_1^Tz_1=\lambda_1 \end{aligned} Var(Y1)=a1TΣa1=z1TPTΣPz1=λ1z112+λ2z122+...+λpz1p2≤λ1z1Tz1=λ1
并且当 z 1 = ( 1 , 0 , . . , 0 ) T z_1=(1,0,..,0)^T z1=(1,0,..,0)T时,等号成立,这时
a 1 = P z 1 = e 1 , a_1=Pz_1=e_1, a1=Pz1=e1,
由此可知,在约束条件 a 1 T a 1 = 1 a_1^Ta_1=1 a1Ta1=1之下,当 a 1 = e 1 a_1=e_1 a1=e1时, V a r ( Y 1 ) Var(Y_1) Var(Y1)达到最大,且
m a x a 1 T Σ a 1 { V a r ( Y 1 ) } = V a r ( e 1 T X ) = e 1 T Σ e 1 = λ 1 \mathop{max}\limits_{a_1^T\Sigma a_1} \{Var(Y_1)\}=Var(e_1^TX)=e_1^T\Sigma e_1=\lambda_1 a1TΣa1max{Var(Y1)}=Var(e1TX)=e1TΣe1=λ1
设 Y 2 = a 2 T Y_2=a_2^T Y2=a2T为 X X X的第二主成分,则应有
a 2 T a 2 = 1 且 C o v ( Y 2 , Y 1 ) = a 2 T Σ e 1 = λ 1 a 2 T e 1 = 0 , ( Y 2 、 Y 1 相 互 独 立 ) a_2^Ta_2=1且Cov(Y_2,Y_1)=a_2^T\Sigma e_1=\lambda_1a_2^Te_1=0,(Y_2、Y_1相互独立) a2Ta2=1且Cov(Y2,Y1)=a2TΣe1=λ1a2Te1=0,(Y2、Y1相互独立)
即 a 2 T e 1 = 0. a_2^Te_1=0. a2Te1=0.令
z 2 = ( z 21 , z 22 , . . . , z 2 p ) T = P T a 2 z_2=(z_{21},z_{22}, ...,z_{2p})^T=P^Ta_2 z2=(z21,z22,...,z2p)T=PTa2
则 z 2 T z 2 = 1 z_2^Tz_2=1 z2Tz2=1,而由 a 2 T e 1 = 0 a_2^Te_1=0 a2Te1=0即有
a 2 T e 1 = z 2 T P T e 1 = z 21 e 1 T e 1 + z 22 e 2 T e 1 + . . . + z 2 p e p T e 1 = z 21 = 0 a_2^Te_1=z_2^TP^Te_1=z_{21}e_1^Te_1+z_{22}e_2^Te_1+...+z_{2p}e_p^Te_1=z_{21}=0 a2Te1=z2TPTe1=z21e1Te1+z22e2Te1+...+z2pepTe1=z21=0
故
V a r ( Y 2 ) = a 2 T Σ a 2 = z 2 T P T Σ P z 2 = z 2 T Λ z 2 = λ 1 z 21 2 + λ 2 z 22 2 + . . . + λ p z 1 p 2 = λ 2 z 22 2 + . . . + λ p z 1 p 2 ≤ λ 2 z 2 T z 2 = λ 2 \begin{aligned} Var(Y_2)&=a_2^T\Sigma a_2 = z_2^TP^T\Sigma Pz_2=z_2^T\Lambda z_2\\&= \lambda_1z_{21} ^2 + \lambda_{2}z_{22} ^ 2 + ... + \lambda_pz_{1p} ^ 2 \\&= \lambda_{2}z_{22} ^ 2 + ... + \lambda_pz_{1p} ^ 2 \leq \lambda_2 z_2^Tz_2 = \lambda_2 \end{aligned} Var(Y2)=a2TΣa2=z2TPTΣPz2=z2TΛz2=λ1z212+λ2z222+...+λpz1p2=λ2z222+...+λpz1p2≤λ2z2Tz2=λ2
当 z 2 = ( 0 , 1 , 0 , . . . , 0 ) T z_2=(0,1,0,...,0)^T z2=(0,1,0,...,0)T时,即 a 2 = P z 2 = e 2 a_2=Pz_2=e_2 a2=Pz2=e2时,满足 a 2 T a 2 = 1 a_2^Ta_2=1 a2Ta2=1,且 C o v ( Y 2 , Y 1 ) = λ 1 a 2 T e 1 = 0 Cov(Y_2, Y_1)=\lambda_1a_2^Te_1=0 Cov(Y2,Y1)=λ1a2Te1=0,并且使 V a r ( Y 2 ) = λ 2 Var(Y_2)=\lambda_2 Var(Y2)=λ2达到最大
4.1.2总体主成分的性质
(1)主成分的协方差矩阵及总方差
(2)主成分的贡献率与累计贡献率
(3)主成分 Y I Y_I YI与 X j X_j Xj的相关系数 C o v ( X ) = Σ = ( σ i j ) p × p Cov(X)=\Sigma=(\sigma_{ij})_{p\times p} Cov(X)=Σ=(σij)p×p
4.1.3 R语言根据原理自己实现
求协方差矩阵
[ 1 − 2 0 − 2 5 0 0 0 2 ] \begin{bmatrix} 1 & -2 & 0\\ -2 & 5 & 0 \\ 0 & 0 & 2 \end{bmatrix} ⎣⎡1−20−250002⎦⎤
的各主成分
## 生成协方差矩阵
df = matrix(c(1, -2, 0, -2, 5, 0, 0, 0, 2), ncol=3)
df
| 1 | -2 | 0 |
| -2 | 5 | 0 |
| 0 | 0 | 2 |
利用R语言的内置函数eigen求特征值特征向量
用法:
eigen(x, symmetric, only.values = FALSE, EISPACK = FALSE)
| 参数 | 说明 |
|---|---|
| x | a numeric or complex matrix whose spectral decomposition is to be computed. Logical matrices are coerced to numeric. |
| symmetric | if TRUE, the matrix is assumed to be symmetric (or Hermitian if complex) and only its lower triangle (diagonal included) is used. If symmetric is not specified, isSymmetric(x) is used. |
| only.values | if TRUE, only the eigenvalues are computed and returned, otherwise both eigenvalues and eigenvectors are returned. |
| EISPACK | logical. Defunct and ignored. |
结果有两个:
- values:特征值
- vectors:特征向量
## 特征向量
eigen(df)$vectors
| -0.3826834 | 0 | 0.9238795 |
| 0.9238795 | 0 | 0.3826834 |
| 0.0000000 | 1 | 0.0000000 |
## 特征值
eigen(df)$values
- 5.82842712474619
- 2
- 0.17157287525381
所以X的三个主成分为:
Y 1 = e 1 T X = − 0.383 X 1 + 0.924 X 2 ; Y 2 = e 2 T X = X 3 ; Y 3 = e 3 T X = 0.924 X 1 + 0.383 X 2 ; \begin{aligned} Y_1 &= e_1^TX = -0.383X_1+0.924X_2;\\ Y_2 &= e_2^TX = X_3;\\ Y_3 &= e_3^TX = 0.924X1+0.383X_2; \end{aligned} Y1Y2Y3=e1TX=−0.383X1+0.924X2;=e2TX=X3;=e3TX=0.924X1+0.383X2;
由上述结果可知,第一主成分的贡献率为:
5.83 5.83 + 2.00 + 0.17 = 73 \frac{5.83}{5.83 +2.00 + 0.17}=73% 5.83+2.00+0.175.83=73
前两主成分的累计贡献率为:
5.83 + 2.00 5.83 + 2.00 + 0.17 = 989 \frac{5.83+2.00}{5.83 +2.00 + 0.17}=989% 5.83+2.00+0.175.83+2.00=989
因此,若用前两个主成分代替原来的三个变量,其信息损失仅为2%,是很小的。
4.1.4 R语言内置方法
R中作为主成分分析最主要的函数是 princomp() 函数
- princomp() 主成分分析 可以从相关阵或者从协方差阵做主成分分析
- summary() 提取主成分信息
- loadings() 显示主成分分析或因子分析中载荷的内容
- predict() 预测主成分的值
- screeplot() 画出主成分的碎石图
- biplot() 画出数据关于主成分的散点图和原坐标在主成分下的方向
1.princomp()
## princomp()
df = data.frame(x1=rnorm(100), x2=rnorm(100), x3=rnorm(100))
df.pr=princomp(df,cor=FALSE) # cor=TRUE:以X的相关系数矩阵做主成分分析,其实就是X的标准化变量的主成分
df.pr
Call:
princomp(x = df, cor = FALSE)
Standard deviations:
Comp.1 Comp.2 Comp.3
1.0784416 0.9679190 0.8492227
3 variables and 100 observations.
其中Standard deviations代表各主成分的标准差,即根号特征值(特征值是主成分的方差)
2.summary()
summary(df.pr,loadings=TRUE)
Importance of components:
Comp.1 Comp.2 Comp.3
Standard deviation 1.078442 0.9679190 0.8492227
Proportion of Variance 0.412266 0.3320949 0.2556392
Cumulative Proportion 0.412266 0.7443608 1.0000000
Loadings:
Comp.1 Comp.2 Comp.3
x1 0.998
x2 -0.120 -0.991
x3 0.992 -0.121
其中Proportion of Variance是各主成分的贡献率
Cumulative Proportion是累计贡献率
Loadings是特征向量
3.predict()
predict(df.pr, data.frame(x1=c(1, 2), x2=c(3, 4), x3=c(4, 5))) # 预测自给的数据
#predirc(df.pr) # 预测已有数据的主成分
| Comp.1 | Comp.2 | Comp.3 |
|---|---|---|
| 3.770027 | 0.9634912 | -3.532819 |
| 4.671794 | 1.9991897 | -4.588350 |
4.loadings()
loadings(df.pr)
Loadings:
Comp.1 Comp.2 Comp.3
x1 0.998
x2 -0.120 -0.991
x3 0.992 -0.121
Comp.1 Comp.2 Comp.3
SS loadings 1.000 1.000 1.000
Proportion Var 0.333 0.333 0.333
Cumulative Var 0.333 0.667 1.000
5.screeplot()
## 条形碎石图
screeplot(df.pr)
## 折现碎石图
screeplot(df.pr, type='lines')
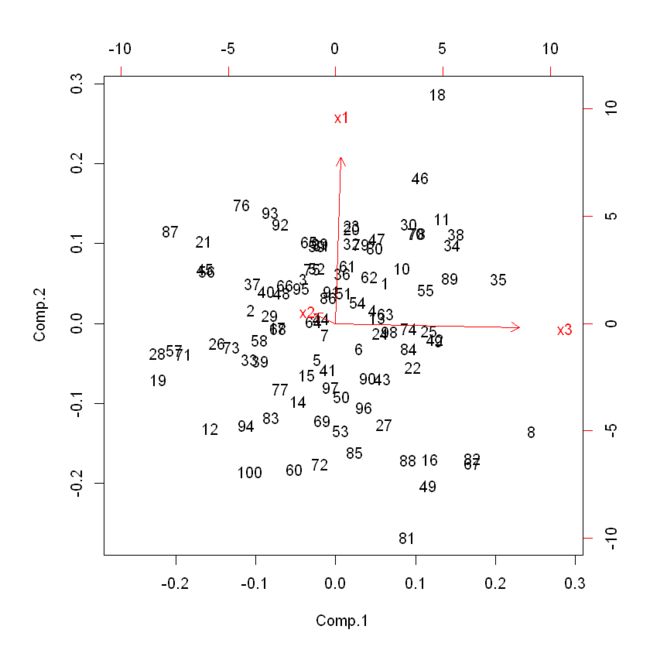
6.biplot()
## 主成分散点图
biplot(df.pr)
4.2 典型相关分析
## 相关系数矩阵
CorX `= matrix(c(1, 0.571, 0.875, 0.571, 1, 0.781, 0.875, 0.781, 1), ncol=3)
CorY = matrix(c(1, 0.671, 0.785, 0.671, 1, 0.932, 0.785, 0.932, 1), ncol=3)
CorXY = matrix(c(0.714, 0.840, 0.914, 0.380, 0.681, 0.591, 0.626, 0.819, 0.870), ncol=3)
CorYX = t(CorXY)
# 求负二次幂
fuermi<-function(Sigma){
lamda <- solve(eigen(Sigma)$vectors)%*%Sigma%*%(eigen(Sigma)$vectors)
sqrt(diag(lamda))
lamda_sqrt <- matrix(c(sqrt(diag(lamda))[1],0,0,0,sqrt(diag(lamda)[2]),0, 0, 0, sqrt(diag(lamda)[3])),nrow = 3,ncol = 3)
Sigma_sqrt <- (eigen(Sigma)$vectors)%*%lamda_sqrt%*%solve(eigen(Sigma)$vectors)
return(solve(Sigma_sqrt))
}
A2 = fuermi(CorX) %*% CorXY %*% solve(CorY) %*% CorYX %*% fuermi(CorX)
B2 = fuermi(CorY) %*% CorYX %*% solve(CorX) %*% CorXY %*% fuermi(CorY)
e1 = eigen(A2)$vectors
e2 = eigen(B2)$vectors
rho1 = eigen(B2)$values[1]
rho2 = eigen(B2)$values[2]
rho3 = eigen(B2)$values[3]
# 典型相关系数
c(rho1, rho2, rho3)
- 1.2116851534277
- 0.229934013998988
- 0.0274354332393604
## X的典型相关变量系数
e1
| -0.3287070 | 0.2380847 | 0.9139296 |
| -0.3796076 | -0.9193985 | 0.1029784 |
| -0.8647831 | 0.3130849 | -0.3925915 |
## Y的典型相关变量系数
e2
| -0.60894743 | -0.2898345 | 0.7383624 |
| 0.04600424 | -0.9421908 | -0.3319037 |
| -0.79187539 | 0.1681441 | -0.5870783 |
希望我的文章对您有所帮助,同时也感谢您能抽出宝贵的时间阅读,打公式不易,如果您喜欢的话,欢迎点赞、关注、收藏。您的支持是我创作的动力,希望今后能带给大家更多优质的文章