Spark Streaming结合 Kafka 两种不同的数据接收方式比较
揭开Spark Streaming神秘面纱⑥ - Spark Streaming结合 Kafka 两种不同的数据接收方式比较
DirectKafkaInputDStream 只在 driver 端接收数据,所以继承了 InputDStream,是没有 receivers 的
在结合 Spark Streaming 及 Kafka 的实时应用中,我们通常使用以下两个 API 来获取最初的 DStream(这里不关心这两个 API 的重载):
KafkaUtils#createDirectStream及
KafkaUtils#createStream这两个 API 除了要传入的参数不同外,接收 kafka 数据的节点、拉取数据的时机也完全不同。本文将分别就两者进行详细分析。
KafkaUtils#createStream
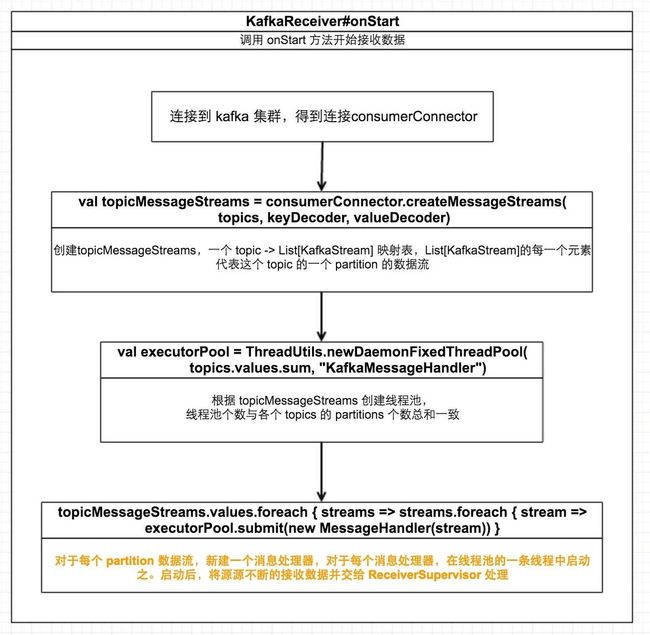
先来分析 createStream,在该函数中,会新建一个 KafkaInputDStream对象,KafkaInputDStream继承于 ReceiverInputDStream。我们在文章揭开Spark Streaming神秘面纱② - ReceiverTracker 与数据导入分析过
- 继承ReceiverInputDStream的类需要重载 getReceiver 函数以提供用于接收数据的 receiver
- recever 会调度到某个 executor 上并启动,不间断的接收数据并将收到的数据交由 ReceiverSupervisor 存成 block 作为 RDD 输入数据
KafkaInputDStream当然也实现了getReceiver方法,如下:
def getReceiver(): Receiver[(K, V)] = {
if (!useReliableReceiver) {
//< 不启用 WAL
new KafkaReceiver[K, V, U, T](kafkaParams, topics, storageLevel)
} else {
//< 启用 WAL
new ReliableKafkaReceiver[K, V, U, T](kafkaParams, topics, storageLevel)
}
}根据是否启用 WAL,receiver 分为 KafkaReceiver 和 ReliableKafkaReceiver。揭开Spark Streaming神秘面纱②-ReceiverTracker 与数据导入一文中详细地介绍了
- receiver 是如何被分发启动的
- receiver 接受数据后数据的流转过程
并在 揭开Spark Streaming神秘面纱③ - 动态生成 job 一文中详细介绍了 - receiver 接受的数据存储为 block 后,如何将 blocks 作为 RDD 的输入数据
- 动态生成 job
以上两篇文章并没有具体介绍 receiver 是如何接收数据的,当然每个重载了 ReceiverInputDStream 的类的 receiver 接收数据方式都不相同。下图描述了 KafkaReceiver 接收数据的具体流程:
KafkaUtils#createDirectStream
在揭开Spark Streaming神秘面纱③ - 动态生成 job中,介绍了在生成每个 batch 的过程中,会去取这个 batch 对应的 RDD,若未生成该 RDD,则会取该 RDD 对应的 blocks 数据来生成 RDD,最终会调用到DStream#compute(validTime: Time)函数,在KafkaUtils#createDirectStream调用中,会新建DirectKafkaInputDStream,DirectKafkaInputDStream#compute(validTime: Time)会从 kafka 拉取数据并生成 RDD,流程如下:
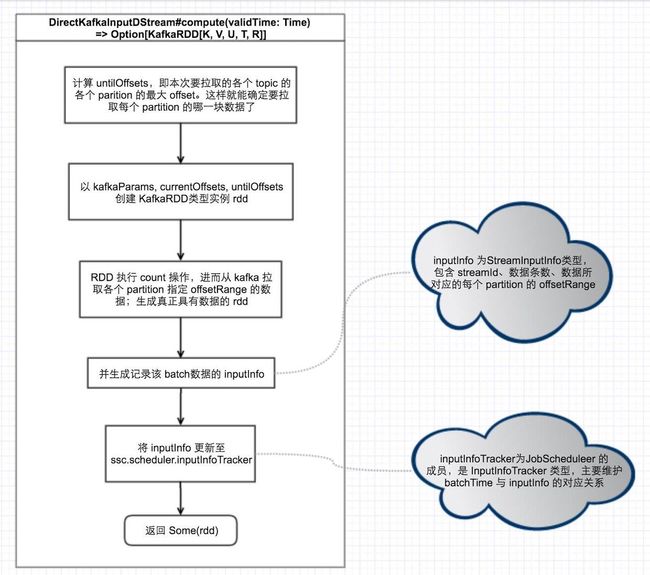
如上图所示,该函数主要做了以下三个事情:
- 确定要接收的 partitions 的 offsetRange,以作为第2步创建的 RDD 的数据来源
- 创建 RDD 并执行 count 操作,使 RDD 真实具有数据
- 以 streamId、数据条数,offsetRanges 信息初始化 inputInfo 并添加到 JobScheduler 中
进一步看 KafkaRDD 的 getPartitions 实现:
override def getPartitions: Array[Partition] = {
offsetRanges.zipWithIndex.map { case (o, i) =>
val (host, port) = leaders(TopicAndPartition(o.topic, o.partition))
new KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset, host, port)
}.toArray
}从上面的代码可以很明显看到,KafkaRDD 的 partition 数据与 Kafka topic 的某个 partition 的 o.fromOffset 至 o.untilOffset 数据是相对应的,也就是说 KafkaRDD 的 partition 与 Kafka partition 是一一对应的
通过以上分析,我们可以对这两种方式的区别做一个总结:
- createStream会使用 Receiver;而createDirectStream不会
- createStream使用的 Receiver 会分发到某个 executor 上去启动并接受数据;而createDirectStream直接在 driver 上接收数据
- createStream使用 Receiver 源源不断的接收数据并把数据交给 ReceiverSupervisor 处理最终存储为 blocks 作为 RDD 的输入,从 kafka 拉取数据与计算消费数据相互独立;而createDirectStream会在每个 batch 拉取数据并就地消费,到下个 batch 再次拉取消费,周而复始,从 kafka 拉取数据与计算消费数据是连续的,没有独立开
- createStream中创建的KafkaInputDStream 每个 batch 所对应的 RDD 的 partition 不与 Kafka partition 一一对应;而createDirectStream中创建的 DirectKafkaInputDStream 每个 batch 所对应的 RDD 的 partition 与 Kafka partition 一一对应