ES整合HBase实现二级索引
前言;
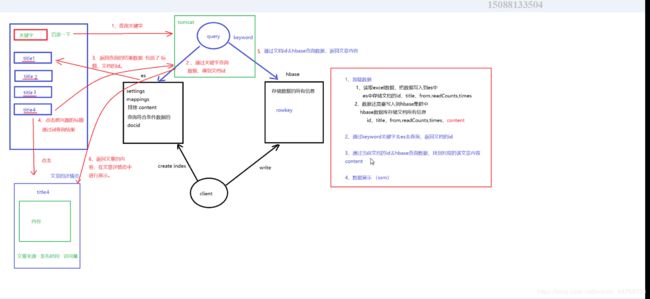
es整合hbase实现二级索引的目的,只要是因为hbase不具备全文检索,只有rowkey是全局的唯一标识,在大量数据的前提下,想要根据字段进行检索,没办法利用rowkey就会出现效率低下的情况.刚好es具备全文检索的优良传统,两个优秀的框架注定是要擦出点火花来的.
设计思想: 在es中存储标题,在hbase 中存储正文
实现思路:
1.使用代码解析excel,读取excel的内容
2.将读取到的内容保存到es和hbase中去
3.搜索es中的字段,然后选择详细信息
4.通过hbase显示具体文件内容
一:在es中构建索引库
PUT /articles
{
"settings":{
"number_of_shards":3, //分片个数
"number_of_replicas":1, //副本个数
"analysis" : {
"analyzer" : {
"ik" : { //ik分词器
"tokenizer" : "ik_max_word" //分词器
}
}
}
},
"mappings":{
"article":{
"dynamic":"strict", //动静态
"_source": { //字段来源
"includes": [
"id","title","from","readCounts","times" //包含字段
],
"excludes": [ //不包含字段
"content" //不包含文章内容
]
},
"properties":{ //属性
"id":{"type": "keyword", "store": true}, //id,keyword类型,存储
//标题,text类型,存储,索引存储,使用ik分词器
"title":{"type": "text","store": true,"index" : true,"analyzer": "ik_max_word"},
//from字段, keyword类型,存储
"from":{"type": "keyword","store": true},
//readcounts字段,integer类型,存储
"readCounts":{"type": "integer","store": true},
//文章内容,text类型,不存储,不做索引
"content":{"type": "text","store": false,"index": false},
//时间,keyword类型,不做索引
"times": {"type": "keyword", "index": false}
}
}
}
}
二:创建maven工程,导入依赖
org.apache.poi
poi-ooxml-schemas
3.8
org.apache.poi
poi-ooxml
3.8
org.apache.poi
poi
3.8
org.elasticsearch.client
transport
6.7.0
org.apache.logging.log4j
log4j-core
2.9.1
com.google.code.gson
gson
2.8.2
org.apache.hadoop
hadoop-client
2.7.5
org.apache.hbase
hbase-client
2.0.0
org.apache.hbase
hbase-server
2.0.0
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
三:创建javabean,映射文件所有字段,并提供get/set方法(省略)
public class Article {
private String id;
private String title;
private String from;
private String times;
private String readCounts;
private String content;
....
}
四:创建解析excel的工具类
public class ExcelUtil {
public static void main(String[] args) throws IOException {
//第一步:解析数据
List list = getArticleList();
}
public static List getArticleList() throws IOException {
//创建文件输入流
FileInputStream inputStream = new FileInputStream("C:\\Users\\93095\\Desktop\\baijia.xlsx");
//使用XSSFWorkbook获取文件解析对象来解析xlsx文件
XSSFWorkbook xssfSheets = new XSSFWorkbook(inputStream);
//获取第一个sheet页.因为一个文件可能有多个sheet页面
XSSFSheet sheetAt = xssfSheets.getSheetAt(0);
//获取页面最后一行数据的number号,已经自行减去头行,所以得到的就是数的具体条数
int lastRowNum = sheetAt.getLastRowNum();
//System.out.println(lastRowNum);
//创建集合存放Article
List list = new ArrayList<>();
//获取每一条数据
for (int i = 1; i<= lastRowNum;i++){
//创建Article对象
Article article = new Article();
//循环遍历每行数据,行数据封装成了XSSFRow对象
XSSFRow row = sheetAt.getRow(i);
//获取每一个单元格的信息,从0 开始,从左往右数
//第一行是标题
String title = row.getCell(0).toString();
//获取第二个单元格--数据来源
String from = row.getCell(1).toString();
//获取时间
String times = row.getCell(2).toString();
//获取阅读次数
String readCounts = row.getCell(3).toString();
//获取文字内容
String content = row.getCell(4).toString();
article.setId(i+"");
article.setTitle(title);
article.setFrom(from);
article.setTimes(times);
article.setReadCounts(readCounts);
article.setContent(content);
list.add(article);
}
inputStream.close();
return list;
}
}
五:具体实现思路和步骤
public class ES2HBase {
public static void main(String[] args) throws IOException {
//第一步: 解析excel
List list = ExcelUtil.getArticleList();
//第二步: 将excel数据保存到hbase和es中
//获取es集群客户端连接
TransportClient client = getClient();
//把数据存储到es中
//save2ES(list, client);
//创建表--接收数据
Table table = getTable();
//把数据保存到hbase中
save2HBase(list, table);
//第三步: 搜索es数据
//查询es中title有机器人关键字的内容
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "机器人");
SearchRequestBuilder builder = client.prepareSearch("articles").setTypes("article").setQuery(termQueryBuilder);
SearchResponse searchResponse = builder.get();
//获取外围hit
SearchHits hits = searchResponse.getHits();
//获取每一条数据
SearchHit[] hits1 = hits.getHits();
//遍历hit内容
for (SearchHit hit : hits1){
//获取系统id
String id = hit.getId();
String source = hit.getSourceAsString();
}
//第四步: 到hbase中获取详情内容
//获取系统id 就是 _id的值为123的内容--模拟用户点击词条显示内容
//es中的系统id 就是hbase中的rowkey
Get get = new Get("123".getBytes());
//获取一行数据
Result result = table.get(get);
//获取每个cell
Cell[] cells = result.rawCells();
for (Cell cell : cells){
//获取cell的值,转换成字符串
String string = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println(string);
}
table.close();
client.close();
}
//把数据保存到hbase表中
private static void save2HBase(List list, Table table) throws IOException {
//把数据保存到hbase中
ArrayList arrayList = new ArrayList<>();
//遍历文章内容集合
for (Article article : list){
//获取文章内容的id
Put put = new Put(article.getId().getBytes());
//添加列族和各个列和每个列的值
put.addColumn("f1".getBytes(),"titlt".getBytes(),article.getTitle().getBytes());
put.addColumn("f1".getBytes(),"from".getBytes(),article.getFrom().getBytes());
put.addColumn("f1".getBytes(),"times".getBytes(),article.getTimes().getBytes());
put.addColumn("f1".getBytes(),"readCounts".getBytes(),article.getReadCounts().getBytes());
put.addColumn("f1".getBytes(),"content".getBytes(),article.getContent().getBytes());
//把数据存进put中
arrayList.add(put);
}
//把数据保存到hbase表中
table.put(arrayList);
}
//创建hbase中的表
private static Table getTable() throws IOException {
//获取hbase客户端连接
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
//将数据保存到eshbase表的f1列族中--系统原先没有此表,需要创建
Admin admin = connection.getAdmin();
//判断,如果表不存在就创建
if (!admin.tableExists(TableName.valueOf("eshbase"))){
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("eshbase"));
//指定列族
HColumnDescriptor columnDescriptor = new HColumnDescriptor("f1");
tableDescriptor.addFamily(columnDescriptor);
//创建表
admin.createTable(tableDescriptor);
}
//获取表
Table table = connection.getTable(TableName.valueOf("eshbase"));
return table;
}
//把数据保存到ES
private static void save2ES(List list, TransportClient client) {
//把数据保存到es,批量方式
Gson gson = new Gson();
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
for (Article article : list){
//转成json格式
String json = gson.toJson(article);
IndexRequestBuilder indexRequestBuilder =
client.prepareIndex("articles", "article", article.getId()).setSource(json, XContentType.JSON);
bulkRequestBuilder.add(indexRequestBuilder);
}
//触发请求
bulkRequestBuilder.get();
}
//获取ES客户端
private static TransportClient getClient() throws UnknownHostException {
Settings settings = Settings.builder().put("cluster.name", "es").build();
//获取集群
TransportAddress node01 = new TransportAddress(InetAddress.getByName("node01"), 9300);
TransportAddress node02 = new TransportAddress(InetAddress.getByName("node02"), 9300);
TransportAddress node03 = new TransportAddress(InetAddress.getByName("node03"), 9300);
//获取es连接客户端
TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(node01).addTransportAddress(node02).addTransportAddress(node03);
return client;
}
}