数仓数据通道之用户行为搭建
文章目录
- 采集通道系统架构
- 集群规划
- 准备工作
- 1 虚拟机准备(克隆3台虚拟机)
- 1.1 创建用户
- 1.2 给用户增加ROOT权限
- 1.3 修改主机名
- 1.4 修改网卡信息
- 1.5 关闭防火墙
- 1.6 配置域名映射
- 1.7 文件夹准备
- 1.8 修改windows的hosts
- 2 免密登陆
- 2.1 生成密钥
- 2.1 拷贝密钥至其它机器
- 3 安装JDK配置环境变量(jdk1.8)
- 4 编写集群分发文件脚本(分发文件)
- 一 hadoop集群搭建(2.7.2)
- 1 上传安装包解压
- 2 修改8个配置文件
- 2.1 3个env.sh 中添加jdk的环境变量
- 2.2 4个核心配置文件
- 2.2.1 core-site.xml
- 2.2.2 hdfs-site.xml
- 2.2.3 mapred-site.xml
- 2.2.4 yarn-site.xml
- 2.3 slaves文件(方便集群群起,群停)
- 3 配置lzo压缩
- 3.1 将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
- 3.2 同步lzo的压缩包到其它机器
- 3.3 在core-site.xml中配置支持压缩
- 3.4 分发core-site.xml文件
- 3.5 配置hadoop的环境变量
- 4 格式化namenode
- 4.5 编写集群群起脚本(启动hdfs和yarn)
- 4.6 编写查看集群状态jps的脚本
- 5 集群读写性能测试
- 5.1 启动集群
- 5.2 运行官网提供的测试脚本测试读写压力
- 5.2.1写压力测试
- 5.2.2 读压力测试
- 6 集群优化配置点
- 6.1 HDFS参数调优hdfs-site.xml
- 6.2 YARN参数调优yarn-site.xml
- 6.3 Hadoop宕机
- 二 zookeeper集群搭建(3.4)
- 1.1 上传zookeeper安装包
- 1.2 创建zookeeper数据存放目录
- 1.3 修改zoo.cfg添加集群信息
- 1.4 在zookeeper数据存放目录新增myid文件写入对应的id
- 1.5 编写集群群起脚本
- 三 flume 采集(1.7.0)
- 1.1 数据生成测试
- 1.2 数据生成脚本编写
- 1.3 集群时间伪同步脚本
- 2.1 flume采集设计
- 2.2 flume 安装配置
- 2.2.1 上传flume安装包,解压
- 2.2.2 修改配置文件
- 2.3 flume 监控软件Ganglia
- 2.3.1 安装httpd服务与php
- 2.3.2 安装其他依赖
- 2.3.3 安装ganglia
- 2.3.4 修改配置文件/etc/httpd/conf.d/ganglia.conf
- 2.3.5 修改配置文件/etc/ganglia/gmetad.conf
- 2.3.6 修改配置文件/etc/ganglia/gmond.conf
- 2.3.7 修改/etc/selinux/config
- 2.3.8 启动ganglia
- 2.3.9 打开网页浏览ganglia页面
- 2.3.10 修改flume测试监控
- 2.4 flume job任务配置
- 2.4.1 编写flume etl拦截器和类型过滤器
- 2.4.2 在flume 安装目录下创建job文件新增log-flume-kafka.conf文件
- 2.4.3 将flume 分发至hadoop103 和Hadoop104
- 2.4.4 编写flume 采集程序脚本群起
- 四 kafka集群搭建(0.11)
- 1.1 上传kafka安装包解压配置文件
- 1.2 配置kafka集群
- 1.2.1 启动kafka查看是否可以正常启动
- 1.2.2创建主题
- 1.2.3 查看主题详情
- 1.2.4 查看主题列表
- 1.2.5 发送消息至主题first
- 1.2.6 启动消费者消费主题first中的数据
- 1.2.7 删除主题
- 1.3 kafka Manager监控软件安装配置
- 1.3.1上传kafka-manager压缩包到/opt/module解压
- 1.3.4 修改配置文件
- 1.4 kafka 群起脚本
- 1.5 kafka Manager启动停止脚本
- 1.6 kafka测试(对kafka进行压力测试)
- 1.7 kafka集群机器数计算
- 五 flume 消费(1.7.0)
- 5.1 分析
- 5.2 编写kafka-file-hdfs.conf文件
- 5.3 编写启动消费者flume脚本
- 六 编写采集通道群起脚本
- 七 数据通道测试
- 总结
采集通道系统架构

集群规划
| 服务名称 | 子服务 | 服务器hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Presto | Coordinator | √ | ||
| Worker | √ | √ | ||
| Azkaban | AzkabanWebServer | √ | ||
| AzkabanExecutorServer | √ | |||
| Druid | Druid | √ | √ | √ |
| 服务数 | 总计 | 13 | 8 | 9 |
准备工作
1 虚拟机准备(克隆3台虚拟机)
1.1 创建用户
useradd guochao
passwd 123456
1.2 给用户增加ROOT权限
vim /etc/sudoers
guochao ALL=(ALL) NOPASSWD:ALL
1.3 修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop102
GETAWAY=192.168.131.2
1.4 修改网卡信息
vi /etc/udev/rules.d/70-persistent-net.rules
留下需要的网卡,删除掉不需要的
vi /etc/sysconfig/network-scripts/ifcfg-eth1
修改对应的网卡信息默认是(ifcfg-eth0)
1.5 关闭防火墙
service iptables status(查看防火墙状态)
1.6 配置域名映射
sudo vim /etc/hosts
192.168.131.102 hadoop102
192.168.131.103 hadoop103
192.168.131.104 hadoop104
重复执行上述步骤,分别再hadoop103 Hadoop104上完成上述配置,完成后重启
reboot
1.7 文件夹准备
sudo mkdir /opt/module
sudo mkdir /opt/soft
sudo chown -R guochao:guochao /opt/module/ /opt/soft/
1.8 修改windows的hosts
C:\Windows\System32\drivers\etc
192.168.131.102 hadoop102
192.168.131.103 hadoop103
192.168.131.104 hadoop104
2 免密登陆
由于在hadoop集群和yarn等组件启动的时候,为了避免重复输入命令的情况,需配置好ssh免密登陆,在Hadoop102和Hadoop103上分别生成对应的公匙和密匙,并分别拷贝至其它机器。
2.1 生成密钥
ssh-keygen -t rsa
连续三次回车即可
2.1 拷贝密钥至其它机器
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
3 安装JDK配置环境变量(jdk1.8)
tar -xvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
sudo vim /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
4 编写集群分发文件脚本(分发文件)
#!/bin/bash
if(($#==0))
then
echo "please input args!"
exit;
fi
# 获取文件名称
fileName=`basename $1`
echo fname=$fileName
#获取上层的目录
filePath=`cd -P $(dirname $fileName); pwd`
echo filePath=$filePath
#获取当前登陆的用户
uname=`whoami`
#循环
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $filePath/$fileName $uname@hadoop$host:$filePath
done
分发jdk到其它节点,并source /etc/profile文件
一 hadoop集群搭建(2.7.2)
1 上传安装包解压
解压hadoop安装包
tar -xvf hadoop-2.7.2.tar.gz -C /opt/module/

2 修改8个配置文件
2.1 3个env.sh 中添加jdk的环境变量
vim hadoop-env.sh
vim mapred-env.sh
vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.2 4个核心配置文件
2.2.1 core-site.xml
fs.defaultFS
hdfs://hadoop102:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
2.2.2 hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
hadoop104:50090
2.2.3 mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
2.2.4 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop103
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
2.3 slaves文件(方便集群群起,群停)
vim slaves(配置的时候不要出现任何的空格和回车)
hadoop102
hadoop103
hadoop104
3 配置lzo压缩
3.1 将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
cp /opt/soft/hadoop-lzo-0.4.20.jar /opt/module/hadoop-2.7.2/share/hadoop/common/
3.2 同步lzo的压缩包到其它机器
3.3 在core-site.xml中配置支持压缩
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codec.lzo.class
com.hadoop.compression.lzo.LzoCodec
3.4 分发core-site.xml文件
分发文件
[guochao@hadoop102 module]$ xync hadoop-2.7.2/
3.5 配置hadoop的环境变量
sudo vim /etc/profile
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

4 格式化namenode
hdfs namenode -format
启动hdfs 和yarn
注意:yarn需要在resoureManager节点上启动,否则无法启动yarn
start-dfs.sh

start-yarn.sh
4.5 编写集群群起脚本(启动hdfs和yarn)
hadoop-shell
#!/bin/bash
#启动hdfs
$1-dfs.sh
sleep 1;
mr-jobhistory-daemon.sh $1 historyserver
sleep 2;
#启动yarn
ssh hadoop103 "source /etc/profile;$1-yarn.sh"
4.6 编写查看集群状态jps的脚本
jpsall
#!/bin/bash
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
ssh $i "source /etc/profile;jps"
done;
5 集群读写性能测试
5.1 启动集群
hadoop-shell start
5.2 运行官网提供的测试脚本测试读写压力
5.2.1写压力测试
向HDFS集群写10个128M的文件
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
19/08/21 19:34:56 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
19/08/21 19:34:56 INFO fs.TestDFSIO: Date & time: Wed Aug 21 19:34:56 CST 2019
19/08/21 19:34:56 INFO fs.TestDFSIO: Number of files: 10
19/08/21 19:34:56 INFO fs.TestDFSIO: Total MBytes processed: 1280.0
19/08/21 19:34:56 INFO fs.TestDFSIO: Throughput mb/sec: 23.08469196364161
19/08/21 19:34:56 INFO fs.TestDFSIO: Average IO rate mb/sec: 67.46253967285156
19/08/21 19:34:56 INFO fs.TestDFSIO: IO rate std deviation: 69.98186203814835
19/08/21 19:34:56 INFO fs.TestDFSIO: Test exec time sec: 51.064
5.2.2 读压力测试
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
19/08/21 19:45:24 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
19/08/21 19:45:24 INFO fs.TestDFSIO: Date & time: Wed Aug 21 19:45:24 CST 2019
19/08/21 19:45:24 INFO fs.TestDFSIO: Number of files: 10
19/08/21 19:45:24 INFO fs.TestDFSIO: Total MBytes processed: 1280.0
19/08/21 19:45:24 INFO fs.TestDFSIO: Throughput mb/sec: 116.08924360602212
19/08/21 19:45:24 INFO fs.TestDFSIO: Average IO rate mb/sec: 131.96041870117188
19/08/21 19:45:24 INFO fs.TestDFSIO: IO rate std deviation: 40.39075067340799
19/08/21 19:45:24 INFO fs.TestDFSIO: Test exec time sec: 28.395
19/08/21 19:45:24 INFO fs.TestDFSIO:
6 集群优化配置点
6.1 HDFS参数调优hdfs-site.xml
(1)dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为8台时,此参数设置为60
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
(2)编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
6.2 YARN参数调优yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
6.3 Hadoop宕机
(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
(2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
二 zookeeper集群搭建(3.4)
1.1 上传zookeeper安装包
tar -zxf zookeeper-3.4.10.tar.gz -C /opt/module/
1.2 创建zookeeper数据存放目录
dataDir=/opt/module/zookeeper-3.4.10/zkdata
1.3 修改zoo.cfg添加集群信息
#添加节点信息
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
1.4 在zookeeper数据存放目录新增myid文件写入对应的id
在zkdata目录下新增myid文本文件,增加2
分发zookeeper到其它节点,修改对应的myid文件
1.5 编写集群群起脚本
zk.sh
#!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo "################$i"
ssh $i "source /etc/profile;/opt/module/zookeeper-3.4.10/bin/zkServer.sh $1"
done
启动zk进程
zk start
查看zk集群状态 zk status
################hadoop102
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
################hadoop103
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
################hadoop104
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
三 flume 采集(1.7.0)
// 参数一:控制发送每条的延时时间,默认是0
Long delay = args.length > 0 ? Long.parseLong(args[0]) : 0L;
// 参数二:循环遍历次数
int loop_len = args.length > 1 ? Integer.parseInt(args[1]) : 1000;
1.1 数据生成测试
上传生成数据的log-collector.jar包到hadoop102 hadoop103
scp log-collector.jar guochao@hadoop103:$PWD
运行jar包,将生成的数据存储到/opt/model/test.log
[guochao@hadoop102 module]$ java -classpath log-collector.jar AppMain >/opt/module/test.log
查看日志生成的目录
cat /tmp/logs/app-2019-08-21.log
1.2 数据生成脚本编写
log.sh
#!/bin/bash
for i in hadoop102 hadoop103
do
$i "java -classpath /opt/module/log-collector.jar AppMain $1 $2 >/opt/module/test.log &"
done
1.3 集群时间伪同步脚本
由于需要生成往期的数据,故需要使用脚本设置集群的时间
dt.sh
#!/bin/bash
log_date=$1
for i in hadoop102 hadoop103 hadoop104
do
ssh -t "sudo date -s $log_date "
done
2.1 flume采集设计
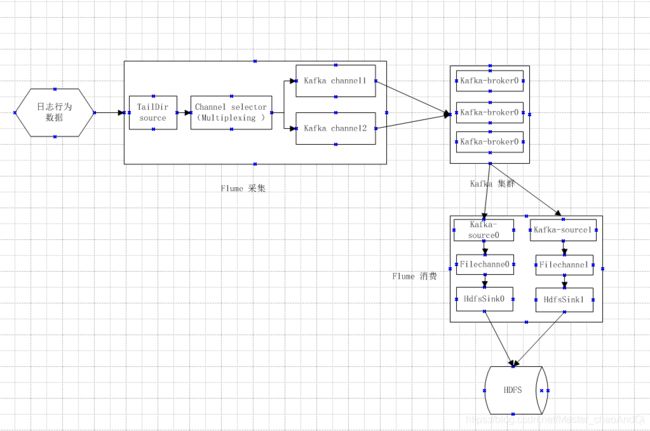
2.2 flume 安装配置
2.2.1 上传flume安装包,解压
2.2.2 修改配置文件
修改mv flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.3 flume 监控软件Ganglia
2.3.1 安装httpd服务与php
sudo yum -y install httpd php
2.3.2 安装其他依赖
sudo yum -y install rrdtool perl-rrdtool rrdtool-devel
sudo yum -y install apr-devel
2.3.3 安装ganglia
sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
sudo yum -y install ganglia-gmetad
sudo yum -y install ganglia-web
sudo yum install -y ganglia-gmond
2.3.4 修改配置文件/etc/httpd/conf.d/ganglia.conf
sudo vim /etc/httpd/conf.d/ganglia.conf
修改为红颜色的配置:
Ganglia monitoring system php web frontend
Alias /ganglia /usr/share/ganglia
Order deny,allow
Deny from all
Allow from all
# Allow from 127.0.0.1
# Allow from ::1
Allow from .example.com
2.3.5 修改配置文件/etc/ganglia/gmetad.conf
sudo vim /etc/ganglia/gmetad.conf
修改为:
data_source "hadoop102" 192.168.1.102
2.3.6 修改配置文件/etc/ganglia/gmond.conf
sudo vim /etc/ganglia/gmond.conf
cluster {
name = "hadoop102"
owner = “unspecified”
latlong = “unspecified”
url = “unspecified”
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine’s hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
#mcast_join = 239.2.11.71
host = 192.168.1.102
port = 8649
ttl = 1
}
udp_recv_channel {
#mcast_join = 239.2.11.71
port = 8649
bind = 192.168.1.102
retry_bind = true
#Size of the UDP buffer. If you are handling lots of metrics you really
#should bump it up to e.g. 10MB or even higher.
#buffer = 10485760
}
2.3.7 修改/etc/selinux/config
sudo vim /etc/selinux/config
修改为:
#This file controls the state of SELinux on the system.
#SELINUX= can take one of these three values:
#enforcing - SELinux security policy is enforced.
#permissive - SELinux prints warnings instead of enforcing.
#disabled - No SELinux policy is loaded.
SELINUX=disabled
#SELINUXTYPE= can take one of these two values:
#targeted - Targeted processes are protected,
#mls - Multi Level Security protection.
SELINUXTYPE=targeted
尖叫提示:selinux本次生效关闭必须重启,如果此时不想重启,可以临时生效之:
sudo setenforce 0
2.3.8 启动ganglia
sudo service httpd start
sudo service gmetad start
sudo service gmond start
2.3.9 打开网页浏览ganglia页面
http://192.168.1.102/ganglia
尖叫提示:如果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限:
sudo chmod -R 777 /var/lib/ganglia
2.3.10 修改flume测试监控
操作Flume测试监控
-
修改/opt/module/flume/conf目录下的flume-env.sh配置:
JAVA_OPTS="-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.1.102:8649
-Xms100m
-Xmx200m" -
启动Flume任务
bin/flume-ng agent
–conf conf/
–name a1
–conf-file job/flume-telnet-logger.conf
-Dflume.root.logger==INFO,console
-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.1.102:8649

2.4 flume job任务配置
2.4.1 编写flume etl拦截器和类型过滤器
打包过滤器上传到flume安装包的lib目录下
cp log-ETL.jar /opt/module/flume-1.7/lib/
2.4.2 在flume 安装目录下创建job文件新增log-flume-kafka.conf文件
#定义组件
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
#声明source
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /opt/module/flume-1.7/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.channels = c1 c2
a1.sources.r1.fileHeader = true
#配置interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.gc.EtlInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.gc.LogTypeInterceptor$Builder
#channel selector
a1.sources.r1.selector.type = multiplexing
#定义的类型
a1.sources.r1.selector.header = topic
#每个类型对应一个channel
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
#定义组件两个kafka channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
2.4.3 将flume 分发至hadoop103 和Hadoop104
2.4.4 编写flume 采集程序脚本群起
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
ssh $i "nohup /opt/module/flume-1.7/bin/flume-ng agent -n a1 -c /opt/module/flume-1.7/conf/ -f /opt/module/flume-1.7/job/log-flume-kafka.conf -Dflume.root.logger=INFO,LOGFILE >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep log-flume-kafka | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
四 kafka集群搭建(0.11)
1.1 上传kafka安装包解压配置文件
1.2 配置kafka集群
vim /opt/module/kafka_0.11/config/server.properties
#broker id 不能重复
broker.id=0
#是否可以删除主题
delete.topic.enable=true
#默认分区数
num.partitions=2
#zookeeper 地址 由于kafka的controller 需要zookeeper辅助工作
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
分发kafka 并修改对应节点上的brokerId 分别为0 1 2
1.2.1 启动kafka查看是否可以正常启动
先启动zookeeper
zk start
/opt/module/kafka_0.11/bin/kafka-server-start.sh /opt/module/kafka_0.11/config/server.properties
1.2.2创建主题
./bin/kafka-topics.sh --create --topic first --zookeeper hadoop102:2181 --replication-factor 3 --partitions 2
1.2.3 查看主题详情
./bin/kafka-topics.sh --describe --topic first --zookeeper hadoop102:2181
Topic:first PartitionCount:2 ReplicationFactor:3 Configs:
Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: first Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
1.2.4 查看主题列表
./bin/kafka-topics.sh --list --zookeeper hadoop102:2181
1.2.5 发送消息至主题first
/opt/module/kafka_0.11/bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello
>hello word
1.2.6 启动消费者消费主题first中的数据
./bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning -topic first
hello
hello word
1.2.7 删除主题
/opt/module/kafka_0.11/bin/kafka-topics.sh --delete --topic first --zookeeper hadoop102:2181
1.3 kafka Manager监控软件安装配置
下载地址:https://github.com/yahoo/kafka-manager
1.3.1上传kafka-manager压缩包到/opt/module解压
unzip kafka-manager-1.3.3.22.zip
1.3.4 修改配置文件
vim application.conf
#修改zookeeper
kafka-manager.zkhosts="hadoop102:2181,hadoop103:2181,hadoop104:2181"
启动kafka-manager
nohup /opt/module/kafka-manager-1.3.3.22/bin/kafka-manager -Dhttp.port=7456 > /opt/module/kafka-manager-1.3.3.22/start.log 2>&1 &

1.4 kafka 群起脚本
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo "start $i kafka"
ssh $i "source /etc/profile;export JMX_PORT=9988 && /opt/module/kafka_0.11/bin/kafka-server-start.sh -daemon /opt/module/kafka_0.11/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo "stop $i kafka "
ssh $i "source /etc/profile;/opt/module/kafka_0.11/bin/kafka-server-stop.sh stop"
done
};;
esac
1.5 kafka Manager启动停止脚本
#!/bin/bash
case $1 in
"start"){
nohup /opt/module/kafka-manager-1.3.3.22/bin/kafka-manager -Dhttp.port=7456 > /opt/module/kafka-manager-1.3.3.22/start.log 2>&1 &
};;
"stop"){
jps -lm | grep -i ProdServerStart | grep -v grep |awk '{print $1}' | xargs kill
};;
esac
1.6 kafka测试(对kafka进行压力测试)
生产者压力测试
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
说明:record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput 是每秒多少条信息。
5000 records sent, 999.4 records/sec (0.10 MB/sec), 1.9 ms avg latency, 254.0 max latency.
5002 records sent, 1000.4 records/sec (0.10 MB/sec), 0.7 ms avg latency, 12.0 max latency.
5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 4.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 3.0 max latency.
5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 5.0 max latency.
参数解析:本例中一共写入10w条消息,每秒向Kafka写入了0.10MB的数据,平均是1000条消息/秒,每次写入的平均延迟为0.8毫秒,最大的延迟为254毫秒。
消费者压力测试
bin/kafka-consumer-perf-test.sh --zookeeper hadoop102:2181 --topic test --fetch-size 10000 --messages 10000000 --threads 1
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153
开始测试时间,测试结束数据,最大吞吐率9.5368MB/s,平均每秒消费2.0714MB/s,最大每秒消费100010条,平均每秒消费21722.4153条。
1.7 kafka集群机器数计算
Kafka机器数量(经验公式)=2*(峰值生产速度副本数/100)+1
先要预估一天大概产生多少数据,然后用Kafka自带的生产压测(只测试Kafka的写入速度,保证数据不积压),计算出峰值生产速度。再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们采用压力测试测出写入的速度是10M/s一台,峰值的业务数据的速度是50M/s。副本数为2。
Kafka机器数量=2(50*2/100)+ 1=3台
五 flume 消费(1.7.0)
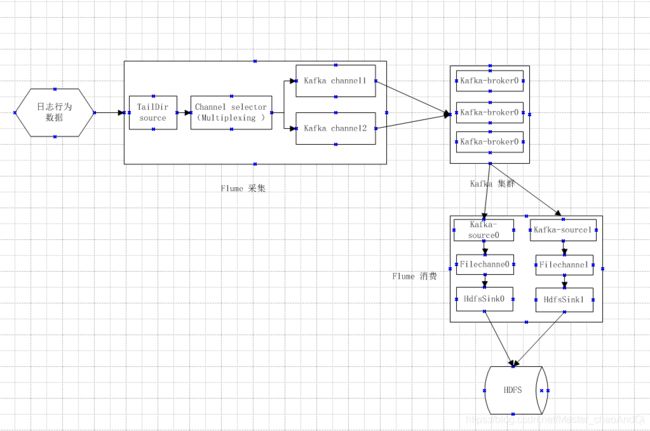
5.1 分析
两个kafka source
两个file channel
两个hdfs sink
根据集群规划kafka消费者flume 部署在Hadoop104上
5.2 编写kafka-file-hdfs.conf文件
#定义组件
a1.sources = r1 r2
a1.channels = c1 c2
a1.sinks = k1 k2
#声明source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.channels=c1
a1.sources.r1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_start
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
#声明source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.channels=c2
a1.sources.r2.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r2.kafka.topics=topic_event
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
#声明channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume-1.7/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume-1.7/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
##channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume-1.7/behavior2
a1.channels.c2.dataDirs = /opt/module/flume-1.7/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
##声明hdfs sink
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
##描述sink与channel的关系
a1.sinks.k1.channel= c1
a1.sinks.k2.channel= c2
5.3 编写启动消费者flume脚本
flume-cusomer
#! /bin/bash
case $1 in
"start"){
for i in hadoop104
do
echo " --------启动 $i 消费flume-------"
ssh $i "source /etc/profile;nohup /opt/module/flume-1.7/bin/flume-ng agent --conf-file /opt/module/flume-1.7/job/kafka-file-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE > /opt/module/flume-1.7/log.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop104
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-file-hdfs | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
六 编写采集通道群起脚本
cluster.sh
#!/bin/bash
if [ $# == 0 ]
then
echo "please input args"
exit;
fi;
case $1 in
"start"){
echo "$1 hadoop cluster"
hadoop-shell $1
echo "$1 zookeeper cluster"
zk $1
sleep 4s;
#启动 Kafka采集集群
echo "$1 kafka cluster"
kafka $1
sleep 6s;
#启动 KafkaManager
echo "$1 km "
km.sh $1
#启动 Flume消费
echo "$1 flume-cusomer "
flume-cusomer $1
#启动 Flume采集进程
echo "$1 flume-producer"
flume-producer $1
};;
"stop"){
#关闭 Flume采集集群
echo "$1 flume-producer "
flume-producer $1
#关闭 Flume消费集群
echo "$1 flume-cusomer"
flume-cusomer $1
#关闭 Kafka采集集群
echo "$1 kafka cluster"
kafka $1
sleep 6s;
#关闭 KafkaManager
echo "$1 km "
km.sh $1
sleep 4s;
echo "$1 zookeeper cluster"
zk $1
echo "$1 hadoop cluster"
hadoop-shell $1
};;
esac
注意:在执行群起脚本的关闭的时候,需要注意顺序,需先关闭kafka 再关闭zookeeper集群,因为kafka 集群还需要一些善后工作。
七 数据通道测试
先启动集群 cluster.sh start
然后在hadoop103 和hadoop102上分别启动kafka消费两个主题种的数据
./bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_start
./bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_event
启动生成日志的脚本log.sh

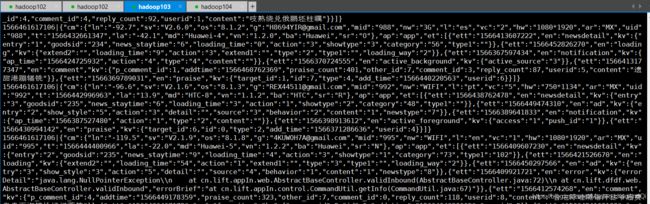
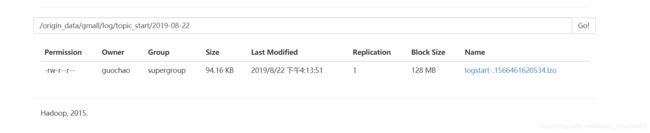
查看hdfs上数据采集文件

总结
至此数据通道就搭建完成了
- 使用简单的生成json数据的java项目 log-collector
- flume1.7的taildir source 动态监听/tmp/logs/文件
- flume的自定义拦截器+channel selector(Multiplexing 选择器),实现脏数据的清洗和日志打标签,根据event的header中设置的日志分类,通过Multiplexing发送到不同的kafkachannel,从而发送到不同的kafka topic
- 在kafka channel中可以显示的指定topic的值,也可以将分类key设置成topic,会默认根据topic的值在kafka中创建对应的topic

- 在消费者flume配置时使用filechannel ,没有使用memorychannel,主要是为了测试,在数据不太重要的情况下,还是选择memory channel(效率快)
- 编写脚本的时候注意JAVA环境变量的问题,由于使用ssh 到其它机器是使用的nologin的方式不会去加载/etc/profile文件